【Pod Terminating原因追踪系列之三】让docker事件处理罢工的cancel状态码
本篇为Pod Terminating原因追踪系列的第三篇,前两篇分别介绍了两种可能导致Pod Terminating的原因。在处理现网问题时,Pod Terminating属于比较常见的问题,而本系列的初衷便是记录导致Pod Terminating问题的原因,希望能够帮助大家在遇到此类问题时,开拓排查思路。
本篇将再介绍一种造成Pod Terminating的原因,即处理事件流的方法异常退出导致的Pod Terminating,当docker版本在19以下且containerd进程由于各种原因(比如OOM)频繁重启时,会有概率导致此问题产生。对于本文中提到的问题,在docker19中已经得到解决,但由于docker18无法直接升级到docker19,且dockerd19修复的改动较大,难以cherry-pick到docker18,因此本文在结尾参考docker19的实现给出了一种简单的解决方案。
Pod Terminating
前一阵有客户反馈使用docker18版本的节点上Pod一直处在Terminating状态,客户通过查看kubelet日志怀疑是Volume卸载失败导致的。现象如下图:

Jul 31 09:53:52 VM_90_48_centos kubelet: E0731 09:53:52.860699 702 plugin_watcher.go:120] error could not find plugin for deleted file /var/lib/kubelet/plugins/kubernetes.io/qcloud-cbs/mounts/disk-o3yxvywa/WTEST.TMP when handling delete event: "/var/lib/kubelet/plugins/kubernetes.io/qcloud-cbs/mounts/disk-o3yxvywa/WTEST.TMP": REMOVE
Jul 31 09:53:52 VM_90_48_centos kubelet: E0731 09:53:52.860717 702 plugin_watcher.go:115] error stat file /var/lib/kubelet/plugins/kubernetes.io/qcloud-cbs/mounts/disk-o3yxvywa/WTEST.TMP failed: stat /var/lib/kubelet/plugins/kubernetes.io/qcloud-cbs/mounts/disk-o3yxvywa/WTEST.TMP: no such file or directory when handling create event: "/var/lib/kubelet/plugins/kubernetes.io/qcloud-cbs/mounts/disk-o3yxvywa/WTEST.TMP": CREATE
通过查看客户Pod的部署情况,发现客户同时使用了in-tree和out-tree的方式挂载cbs,kubelet中的报错是因为在in-tree中检测到了来自out-tree的旁路信息而报错,本质上并不会造成Pod Terminating不掉的问题,看来造成Pod Terminating的原因并非这么简单。
分析日志及源码
在排除了cbs卸载的问题后,我们首先想到会不会还是dockerd和containerd状态不一致的问题呢?通过下面两个指令查看了一下容器和task的状态,发现容器的状态是up而task的状态为STOPPED,果然又是状态不一致导致的问题。按照前两篇的经验来看应该是来自containerd的事件在dockerd中没有得到处理或处理的过程阻塞了。
#查看容器状态,看到容器状态为up
docker ps | grep <container-id>
#查看task状态,显示task的状态为STOPPED
docker-container-ctr --namespace moby --address var/run/docker/containerd/docker-containerd.sock task ls | grep <container-id>
这里提供一种简单验证方法来验证是否为task事件没有得到处理造成的Pod Terminating,随便起一个容器(例如CentOS),并通过exec进入容器并退出,这时去查看docker的堆栈(发送SIGUSR1信号给dockerd),如果发现如下有一条堆栈信息:
goroutine 10717529 [select, 16 minutes]:
github.com/docker/docker/daemon.(*Daemon).ContainerExecStart(0xc4202b2000, 0x25df8e0, 0xc42010e040, 0xc4347904f1, 0x40, 0x7f7ea8250648, 0xc43240a5c0, 0x7f7ea82505e0, 0xc43240a5c0, 0x0, ...)
/go/src/github.com/docker/docker/daemon/exec.go:264 +0xcb6
github.com/docker/docker/api/server/router/container.(*containerRouter).postContainerExecStart(0xc421069b00, 0x25df960, 0xc464e089f0, 0x25dde20, 0xc446f3a1c0, 0xc42b704000, 0xc464e08960, 0x0, 0x0)
/go/src/github.com/docker/docker/api/server/router/container/exec.go:125 +0x34b
之后可以使用《Pod Terminating原因追踪系列之二》中介绍的方法,确认一下该条堆栈信息是否是刚刚创建的CentOS容器产生的,当然从堆栈的时间上来看很容易看出来,也可以通过gdb判断ContainerExecStart参数(第二个参数的地址)中的execID是否和CentOS容器的execID相等的方式来确认,通过返回结果发现exexID相等,说明虽然我们的exec退出了,但是dockerd却没有正确处理来自containerd的exit事件。
在有了之前的排查经验后,我们很快猜到会不会是处理事件流的方法processEventStream在处理exit事件的时候发生了阻塞?验证方法很简单,只需要查看堆栈有没有goroutine卡在StreamConfig.Wait()即可,通过搜索processEventStream堆栈信息发现并没有goroutine卡在Wait方法上,甚至连processEventStream这个处理事件流的方法在堆栈都中也没有找到,说明事件处理的方法已经return了!自然也就无法处理来自containerd的所有事件了。
那么造成processEventStream方法return的具体原因是什么呢?通过查看源码发现,processEventStream中只有在一种情况下会return,即当gRPC连接返回的错误能够被解析(ok为true)且返回cancel状态码的时候proceEventStream会return,否则会另起协程递归调用proceEventStream:
case err = <-errC:
if err != nil {
errStatus, ok := status.FromError(err)
if !ok || errStatus.Code() != codes.Canceled {
c.logger.WithError(err).Error("failed to get event")
go c.processEventStream(ctx)
} else {
c.logger.WithError(ctx.Err()).Info("stopping event stream following graceful shutdown")
}
}
return
那么为什么gRPC连接会返回cancel状态码呢?
在查看客户docker日志时发现containerd在之前不断的被kill并重启,持续了大概11分钟左右:
#日志省略了部分内容
Jul 29 19:23:09 VM_90_48_centos dockerd[11182]: time="2020-07-29T19:23:09.037480352+08:00" level=error msg="containerd did not exit successfully" error="signal: killed" module=libcontainerd
Jul 29 19:24:06 VM_90_48_centos dockerd[11182]: time="2020-07-29T19:24:06.972243079+08:00" level=info msg="starting containerd" revision=e6b3f5632f50dbc4e9cb6288d911bf4f5e95b18e version=v1.2.4
Jul 29 19:24:52 VM_90_48_centos dockerd[11182]: time="2020-07-29T19:24:52.643738767+08:00" level=error msg="containerd did not exit successfully" error="signal: killed" module=libcontainerd
Jul 29 19:25:02 VM_90_48_centos dockerd[11182]: time="2020-07-29T19:25:02.116798771+08:00" level=info msg="starting containerd" revision=e6b3f5632f50dbc4e9cb6288d911bf4f5e95b18e version=v1.2.4
查看系统日志文件(/var/log/messages)看下为什么containerd会被不断地重启:
#日志省略了部分内容
Jul 29 19:23:09 VM_90_48_centos kernel: Memory cgroup out of memory: Kill process 15069 (docker-containe) score 0 or sacrifice child
Jul 29 19:23:09 VM_90_48_centos kernel: Killed process 15069 (docker-containe) total-vm:51688kB, anon-rss:10068kB, file-rss:324kB
Jul 29 19:24:52 VM_90_48_centos kernel: Memory cgroup out of memory: Kill process 12411 (docker-containe) score 0 or sacrifice child
Jul 29 19:24:52 VM_90_48_centos kernel: Killed process 5836 (docker-containe) total-vm:1971688kB, anon-rss:22376kB, file-rss:0kB
可以发现containerd被kill是由于OOM导致的,那么会不会是因为containerd的不断重启导致gRPC返回cancel的状态码呢。先查看一下重启containerd这部分的逻辑:
在启动dockerd时,会创建一个独立的到containerd的gRPC连接,并启动一个monitor协程基于该gRPC连接对containerd的服务做健康检查,monitor每隔500ms会对到containerd的grpc连接做健康检查并记录失败的次数,如果发现gRPC连接返回状态码为UNKNOWN或者NOT_SERVING时对失败次数加一,当失败次数大于域值(域值为3)并且containerd进程已经down掉(通过向进程发送信号进行判断),则会重启containerd进程,并执行reconnect重置dockerd和containerd之间的gRPC连接,在reconnect的逻辑中,会先close旧的gRPC连接,之后新建一条新的gRPC连接:
// containerd/containerd/client.go
func (c *Client) Reconnect() error {
....
// close掉旧的连接
c.conn.Close()
// 建立新的连接
conn, err := c.connector()
....
c.conn = conn
return nil
}
connector := func() (*grpc.ClientConn, error) {
ctx, cancel := context.WithTimeout(context.Background(), 60*time.Second)
defer cancel()
conn, err := grpc.DialContext(ctx, dialer.DialAddress(address), gopts...)
if err != nil {
return nil, errors.Wrapf(err, "failed to dial %q", address)
}
return conn, nil
}
由于reconnect会先close旧连接,那么会不会是close造成的gRPC返回cancel呢?可以写一个简单的demo验证一下,服务端和客户端之间通过unix socket连接,客户端订阅服务端的消息,服务端不断地publish消息给客户端,客户端每隔一段时间close一次gRPC连接,得到的结果如下:
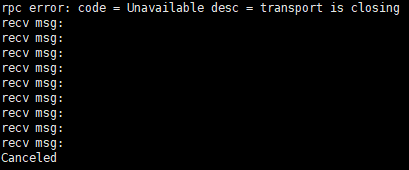
从结果中发现在unix socket下客户端close连接是有概率导致grpc返回cancel状态码的,那么具体什么情况下会产生cancel状态码呢?通过查看gRPC源码发现,当服务端在发送事件过程中,客户端close了连接则会使服务端返回cancel状态码,若此时服务端没有发送事件,则会返回图中的transport is closing错误,至此,问题已经基本定位了,很有可能是客户端close了gRPC连接导致服务端返回了cancel状态码,使processEventStream方法return,导致来自containerd的事件流无法得到处理,最终导致dockerd和containerd的状态不一致。但由于客户的日志级别较高,我们没法从中获得问题产生时的具体时序,因此希望通过调低日志级别复现问题来定位具体在什么情况下会产生这个问题。
问题复现
这个问题复现起来比较简单,只需要模仿客户产生问题时的情况,不断重启containerd进程即可。在docker18.06.3-ce版本集群下创建一个Pod,我们通过下面的脚本不断kill containerd进程:
#!/bin/bash
for i in $(seq 1 1000)
do
process=`ps -elf | grep "docker-containerd --config /var/run/docker/containerd/containerd.toml"| grep -v "grep"|awk '{print $4}'`
if [ ! -n "$process" ]; then
echo "containerd not running"
else
echo $process;
kill -9 $process;
fi
sleep 1;
done
运行上面的脚本便有几率复现该问题,之后删除Pod并查看Pod状态,发现Pod会一直卡在Terminating状态。

查看容器状态和task状态,发现和客户问题的现象完全一致:

由于我们调低了日志级别,查看日志发现下面这样一条日志,而这条日志只有processEventStream方法return时才会打印,且打印日志后processEventStream方法立即return,因此可以确定问题的根本原因就是processEventStream收到了gRPC返回的cancel状态码导致方法return,之后的来自containerd的事件无法得到处理,最终出现dockerd和containerd状态不一致的问题。
Aug 13 15:23:16 VM_1_6_centos dockerd[25650]: time="2020-08-13T15:23:16.686289836+08:00" level=info msg="stopping event stream following graceful shutdown" error="<nil>" module=libcontainerd namespace=moby
问题定位
通过分析docker日志,可以了解到docker18具体在什么情况下会产生processEventStream return的问题,下图是会导致processEventStream return的时序图:
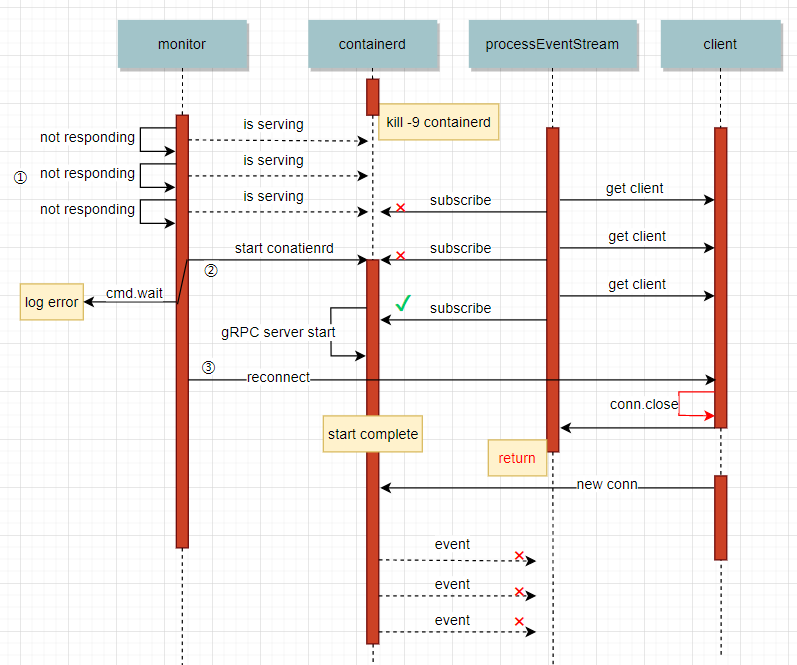
通过该时序图能够看出问题所在,首先当containerd进程被kill后,monitor通过健康检查,发现containerd进程已经停止,便会通过cmd重新启动containerd进程,并重新连接到contaienrd,如果processEventStream在reconnect之前使用旧的gRPC连接成功,订阅到containerd的事件,那么在reconnect时会close这条旧连接,而如果恰好在这时containerd在传输事件,那么该gRPC连接就会返回一个cancel的状态码给processEventStream方法,导致processEventStream方法return。
修复与反思
此问题产生的根本原因在于reconnect的逻辑,在重启时无法保证reconnect一定在processEventStream的subscribe之前发生。由于processEventStream会递归调用自动重连,因此实际上并不需要reconnect,在docker19中也已经修复了这个问题,且没有reconnect,但是docker19这部分改动较大,无法cherry-pick到docker18,因此我们可以参考docker19的实现修改docker18代码,只需要将reconnect的逻辑去除即可。
另外在修复时顺便修复了processEventStream方法不断递归导致瞬间产生大量日志的问题,由于subscribe失败以后会不断地启动协程递归调用,因此会在瞬间产生大量日志,在社区也有人已经提交过PR解决这个问题。(https://github.com/moby/moby/pull/39513)
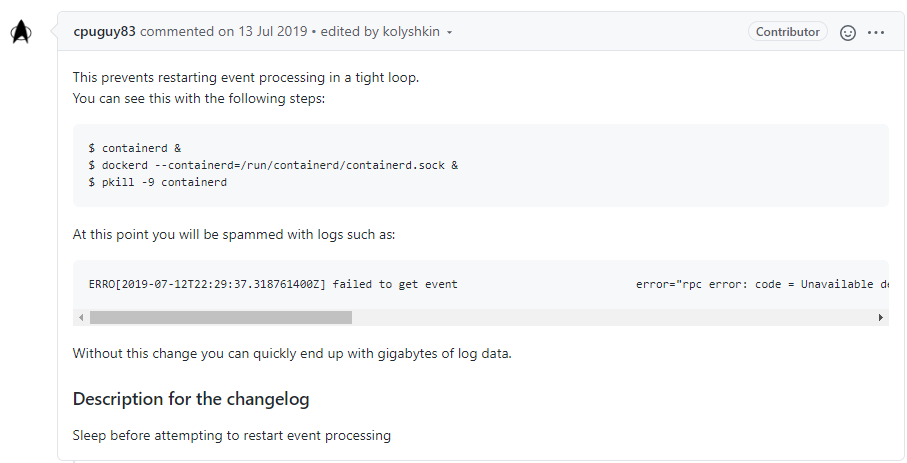
解决办法也很简单,在每次递归调用之前sleep 1秒即可,该改动也已经合进了docker19的代码中。
在后续我们将推出产品化运行时版本升级修复本篇中提到的bug,用户可以在控制台看到升级提醒并方便的进行一键升级。
希望本篇文章对您有帮助,谢谢观看!
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!

【Pod Terminating原因追踪系列之三】让docker事件处理罢工的cancel状态码的更多相关文章
- 【Pod Terminating原因追踪系列之二】exec连接未关闭导致的事件阻塞
前一阵有客户docker18.06.3集群中出现Pod卡在terminating状态的问题,经过排查发现是containerd和dockerd之间事件流阻塞,导致后续事件得不到处理造成的. 定位问题的 ...
- 【Pod Terminating原因追踪系列之一】containerd中被漏掉的runc错误信息
前一段时间发现有一些containerd集群出现了Pod卡在Terminating的问题,经过一系列的排查发现是containerd对底层异常处理的问题.最后虽然通过一个短小的PR修复了这个bug,但 ...
- docker系列之三:docker实际应用
以Docker为基础完成持续集成.自动交付.自动部署: 原理: RD推送代码到git 仓库或者svn等代码服务器上面,git服务器就会通过hook通知jenkins. jenkine 克隆git代码到 ...
- 完毕port(CompletionPort)具体解释 - 手把手教你玩转网络编程系列之三
手把手叫你玩转网络编程系列之三 完毕port(Completion Port)具体解释 ...
- 跟我学: 使用 fireasy 搭建 asp.net core 项目系列之三 —— 配置
==== 目录 ==== 跟我学: 使用 fireasy 搭建 asp.net core 项目系列之一 —— 开篇 跟我学: 使用 fireasy 搭建 asp.net core 项目系列之二 —— ...
- docker系列四之docker镜像与容器的常用命令
docker镜像与容器的常用命令 一.概述 docker的镜像于容器是docker中两个至关重要的概念,首先给各位读者解释一下笔者对于这两个概念的理解.镜像,我们从字面意思上看,镜子里成像,我们人 ...
- Docker 技术系列之安装Docker Desktop for Mac
终于要进入到Docker技术系列了,感谢大家的持续关注. 为什么要选择Docker?因为Docker 轻巧快速,提供了可行.经济.高效的替代方案.举个例子,安装Nginx,Mysql,Redis等常用 ...
- DataSnap 2009 系列之三 (生命周期篇)
DataSnap 2009 系列之三 (生命周期篇) DataSnap 2009的服务器对象的生命周期依赖于DSServerClass组件的设置 当DSServer启动时从DSServerClass组 ...
- Sql Server来龙去脉系列之三 查询过程跟踪
我们在读写数据库文件时,当文件被读.写或者出现错误时,这些过程活动都会触发一些运行时事件.从一个用户角度来看,有些时候会关注这些事件,特别是我们调试.审核.服务维护.例如,当数据库错误出现.列数据被更 ...
随机推荐
- 类加载Class Loading
JVM 何时.如何把 Class 文件加载到内存,形成可以直接使用的 Java 类型,并开始执行代码? 类的生命周期 加载 - 连接(验证.准备.解析)- 初始化 - 使用 - 卸载. 注意,加载 ...
- TF签名为什么这么稳定?TF签名找微导流!
TF签名作为目前最稳定的签名方式收到了业界开发者们的认可,而在如今鱼龙混杂的签名平台中,应该如何选择客厅的TF签名平台呢?下面就一起来看看TF签名为什么这么稳定?TF签名找微导流! TF签名的 ...
- linux下的node版本管理利器:nvm
nvm是一款node版本管理工具,简单来说,如果你想在一个环境下安装多个node版本,并向自由地切换相关版本,那你就需要使用nvm进行版本管理,有点类似pyenv,也是一款python版本管理工具. ...
- 033_go语言中的打点器
代码演示 package main import "fmt" import "time" func main() { ticker := time.NewTic ...
- MySQL时间设计 int timestamp datatime 查询效率性能比较
在数据库设计的时候,我们经常会需要设计时间字段,在MYSQL中,时间字段可以使用int.timestamp.datetime三种类型来存储,那么这三种类型哪一种用来存储时间性能比较高,效率好呢?飘易就 ...
- PHP基础之排序
前言 之前简单介绍了流程控制,函数,数组等.有兴趣的可以看看. PHP入门之类型与运算符 PHP入门之流程控制 PHP入门之函数 PHP入门之数组 接下来介绍一下排序,排序是将一组数据,依指定的顺序进 ...
- TCP学习指北
限于博主水平有限不敢说指南,但应该能够避免刚学TCP的同学出现找不着北的情况. TCP与UDP的区别 区别: UDP是无连接的,而TCP是面向连接的,传数据前要先建立连接. UDP可以一对多,多对多通 ...
- C#LeetCode刷题之#874-模拟行走机器人(Walking Robot Simulation)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/4038 访问. 机器人在一个无限大小的网格上行走,从点 (0, 0 ...
- C#设计模式之21-策略模式
策略模式(Stragety Pattern) 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/427 访问. 策略模式属于 ...
- C#LeetCode刷题之#557-反转字符串中的单词 III(Reverse Words in a String III)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/3955 访问. 给定一个字符串,你需要反转字符串中每个单词的字符顺 ...