JVM(七)字符串详解
常量池:
我们前面也一直说常量池有三种:
1:class文件中的常量池,前面我们解析class文件的时候解析的就是,这是静态常量池。在硬盘上。
2:运行时常量池。可以通过HSDB查看,是InstanceKlass的一个属性:ConstantPool *_constants。在方法区或者说在元空间中(JDK1.8+)
可以通过HSDB查看,HSDB的使用可以看JVM第一篇中的介绍。
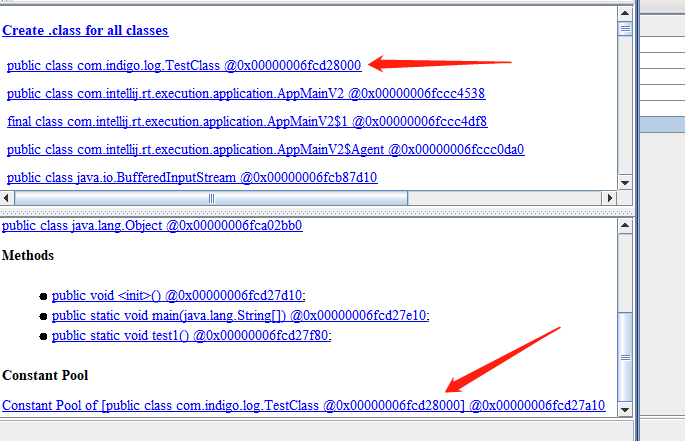

3:字符串常量池。底层是String Pool--StringTable--HashTable。在堆区。
注意:并不是所有的字符串都会在字符串常量池里。
String是怎么存储的?
在java中我们的String对象存储的字符串都是在其内部的一个char数组上的。

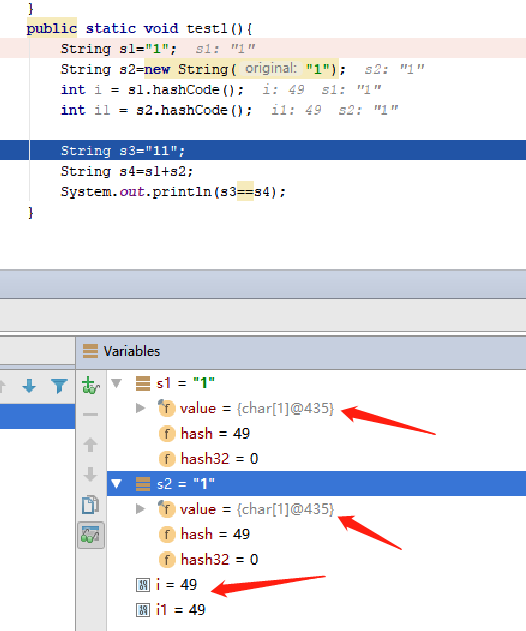
我们看到两个不同的变量,以不同的创建方式创建,字符串一样,但是字符串变量里的value数组属性地址竟然是一样的? 是不是很神奇。这就牵涉到JVM里面
是怎么存储字符串的问题了。还有就是两个变量的hashcode值也是一样的,这是因为String重写了hashcode方法,hash值只和字符串的内容也就是value有关,所以是一样的。
JVM中的String是怎么存储的呢?
在JVM中,使用StringTable来存储String的当然也有些不是通过StringTable存储的,这个后面说明。StringTable继承HashTable,也就是字符串在JVM中是key-value形式存储的。数据结构也就是数组+链表。
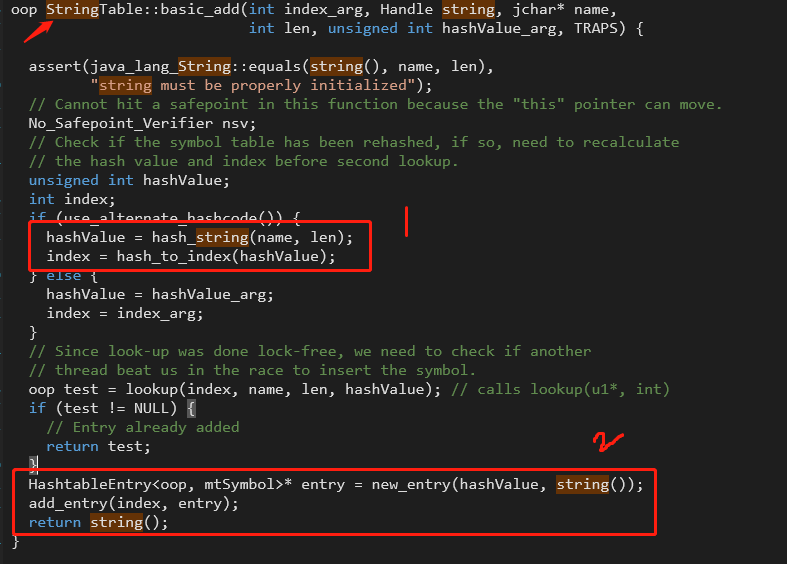
在openJDK中的symbolTable.cpp中如下方法:
key:
是通过1中的方式生成的。1)根据字符串以及字符串的长度计算出hashvalue.2)根据hashvalue计算出index,这个index就是key。也就是数组的下标,在这里称为bucket(桶)默认桶的数量为60013个。
可以通过-XX:StringTableSize=2000参数来调整桶的大小。
value:
key计算出了bucket的位置,value的值就是2中生成的 HashtableEntry<oop, mtSymbol>* entry = new_entry(hashValue, string());
它是将Java中String类的实例instanceOopDesc封装成了HashtableEntry,再存储起来的。
这里补充下,在第一篇JVM中已经提到了oop-klass体系。这里再说明下:
Oop: java中对象在JVM中的存在形式。klass是java中的类在JVM中存在的形式。

通过idea我们可以看到在创建String过程中都创建了些什么内容
实例
我们从idea中接着看上面的例子。看下创建字符串过程中到底创建了那些内容。
public static void main(String[] args) {
test1();
}
public static void test1(){
String s1="1";
String s3="1";
String s2=new String("1");
System.out.println(s1==s3);
System.out.println(s1==s2);
}
以Debug的方式调试,在控制台最右上角有个Memory View,可以实时看到每一步创建了那些对象,创建了几个。
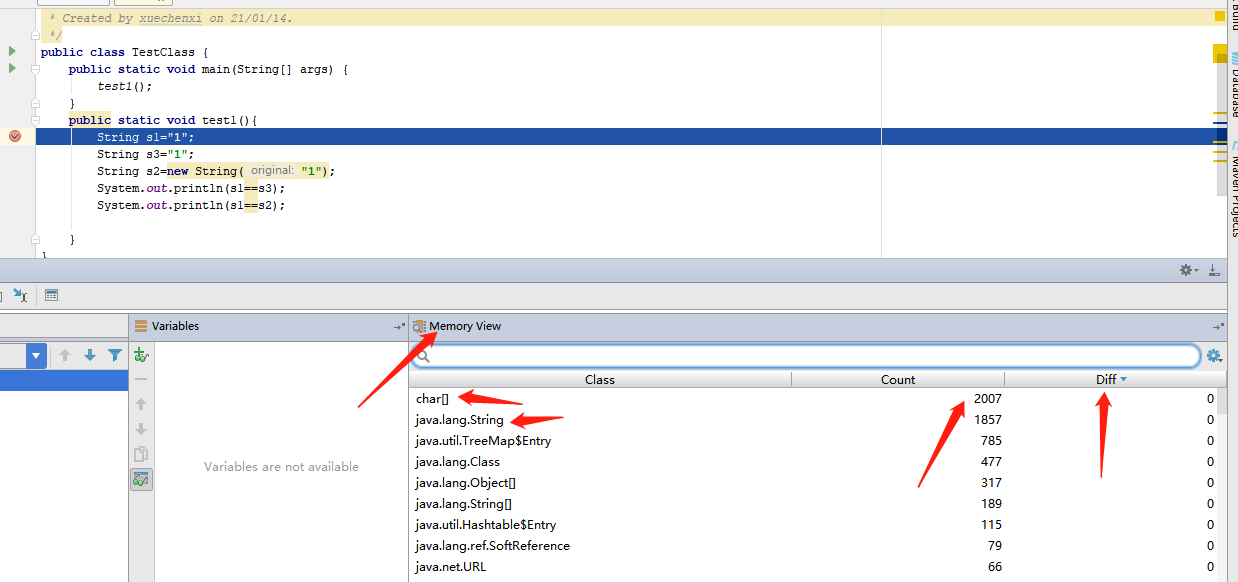
第一行执行完:我们看到char[] ,String各新增了一个。
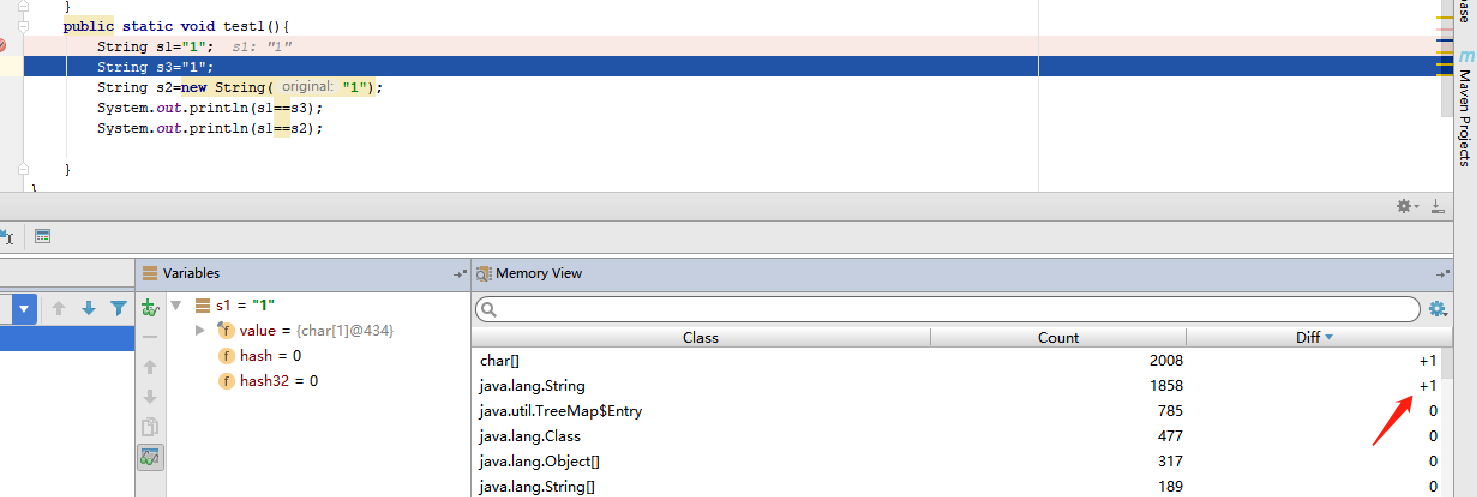
第二行执行完:char[],String一个都没新增,很神奇吧,别慌,执行完。
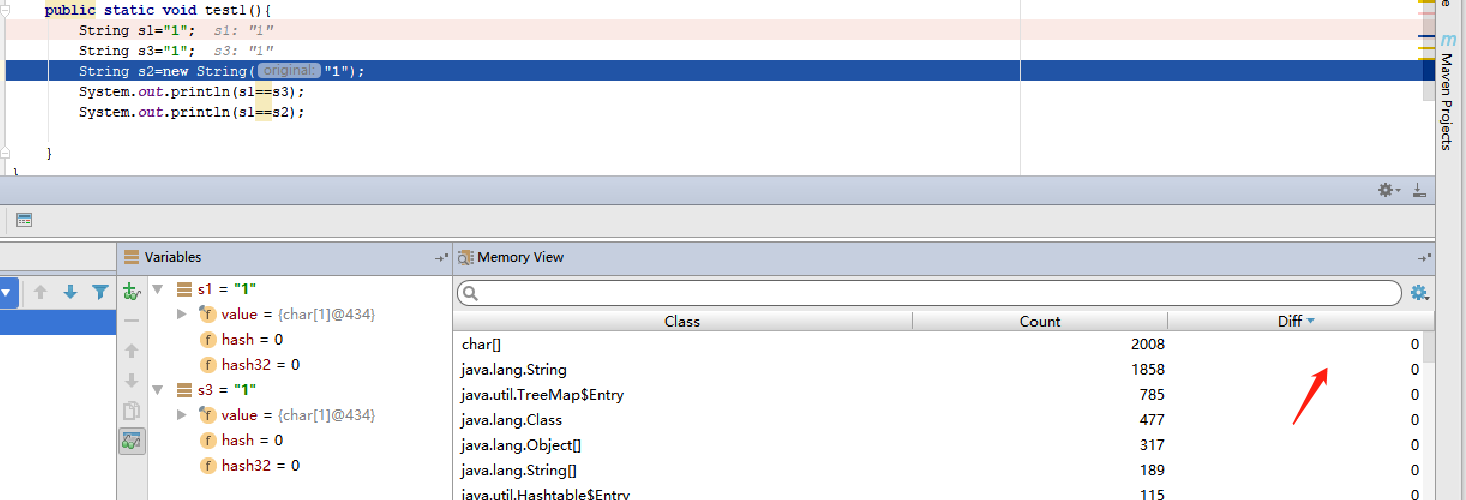
第三行执行完:只新增了一个String。
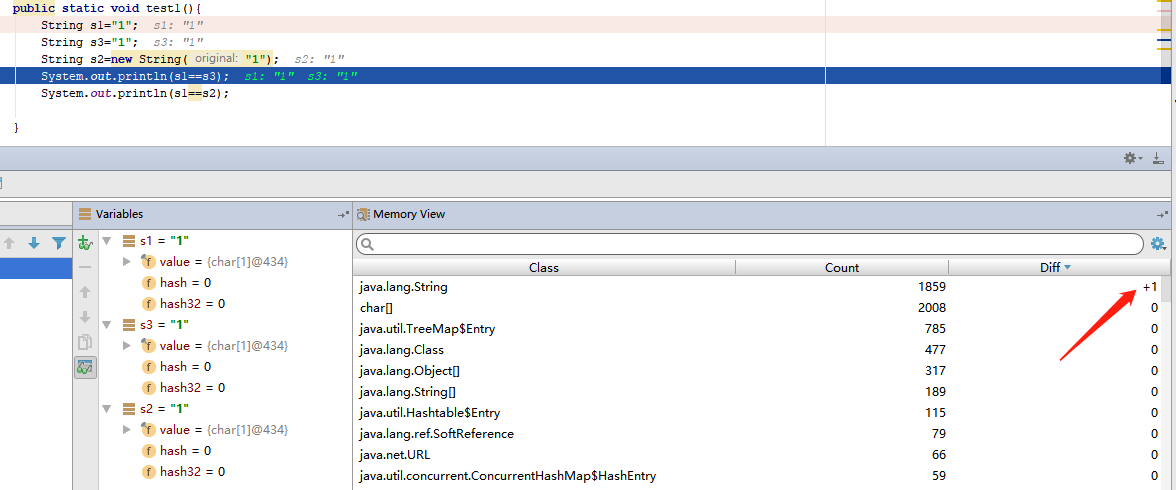
两个比较结果:s1和s3的地址是一样的。s2是不同的地址。

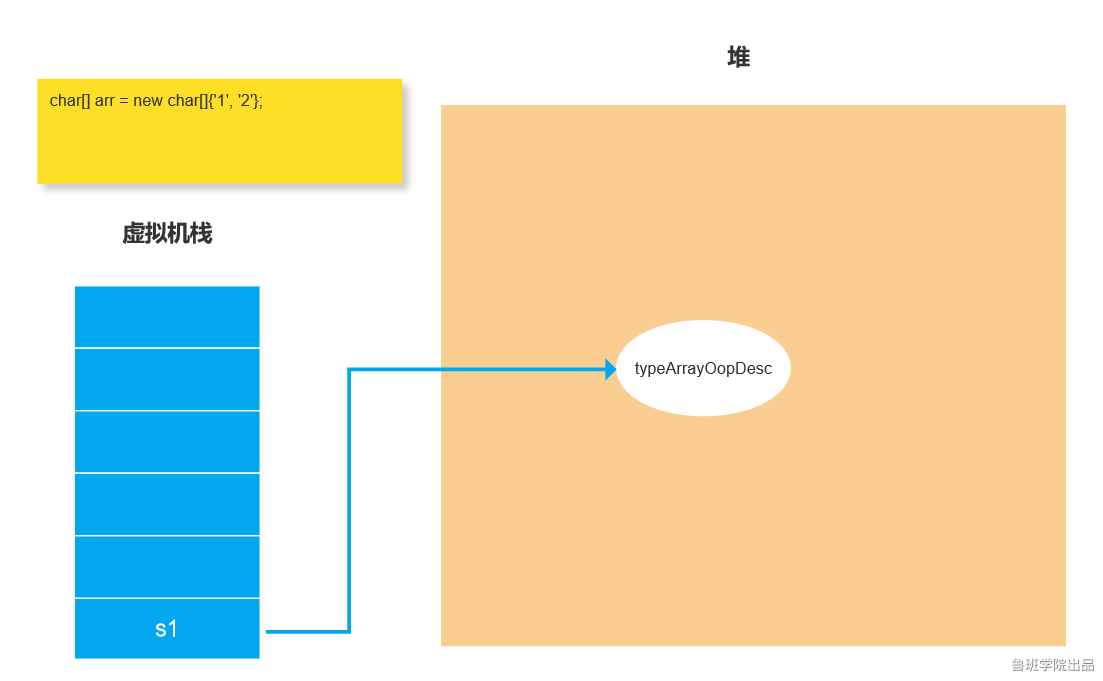
为什么会出现上面看到的结果呢?关键看下图:
1)如果是一个char[]数组类型数据 ,它的对象在JVM中是typeArrayOopDesc形式的。
2:直接双引号创建一个字符串:按照上面说的,字面字符串会在堆里有一个String对象,String对象里有一个char[]数组对象,把String对象对应的instanceOopDesc封装成HashTableEntry然后把HashTableEntry放入常量池中。s1只是引用这个String对象。
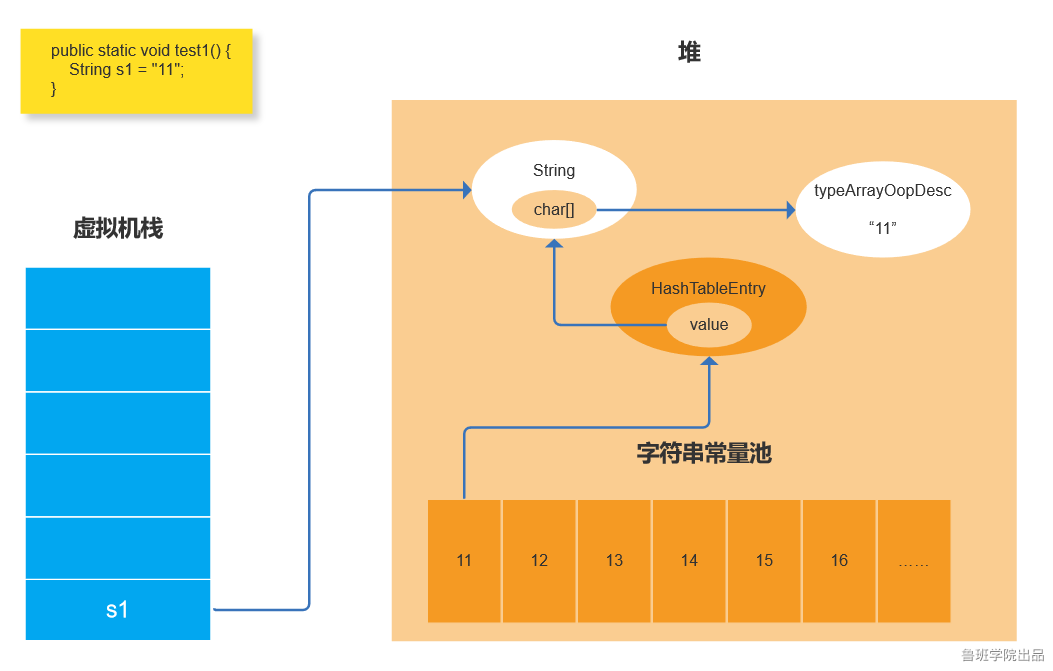
3:两个双引号:当s2创建“11”字面字符串时,会首先判断常量池是否有这个字符串如果有的话会直接返回这个字符串的instanceOopDesc。所以s1,s2指向的是同一个块地址。
如果没有的话会创建一个像2中的那样。
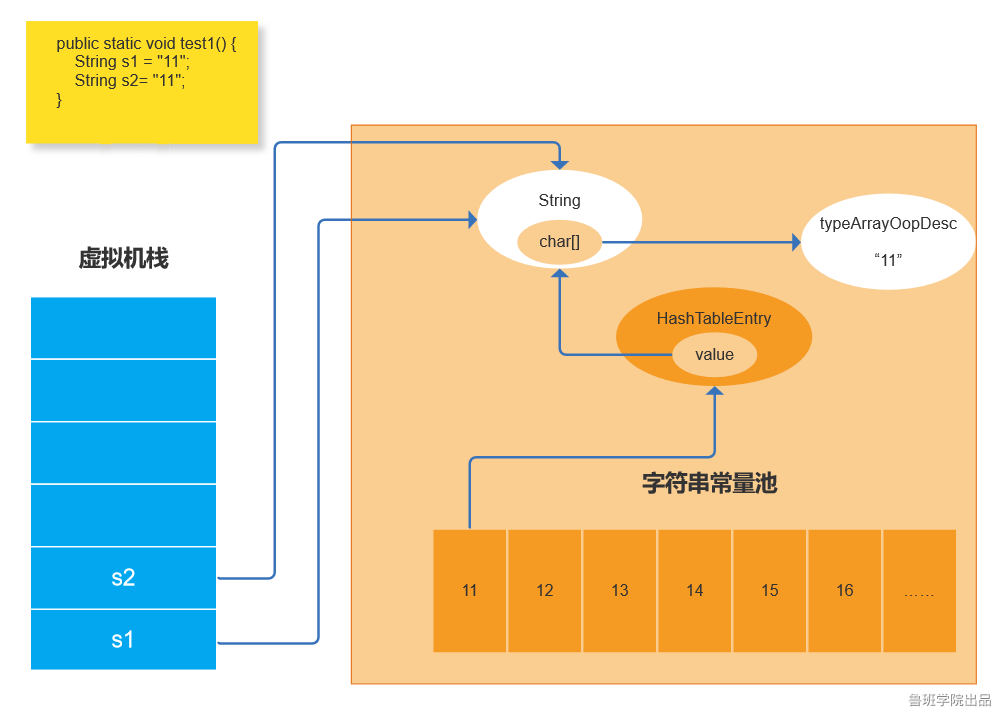
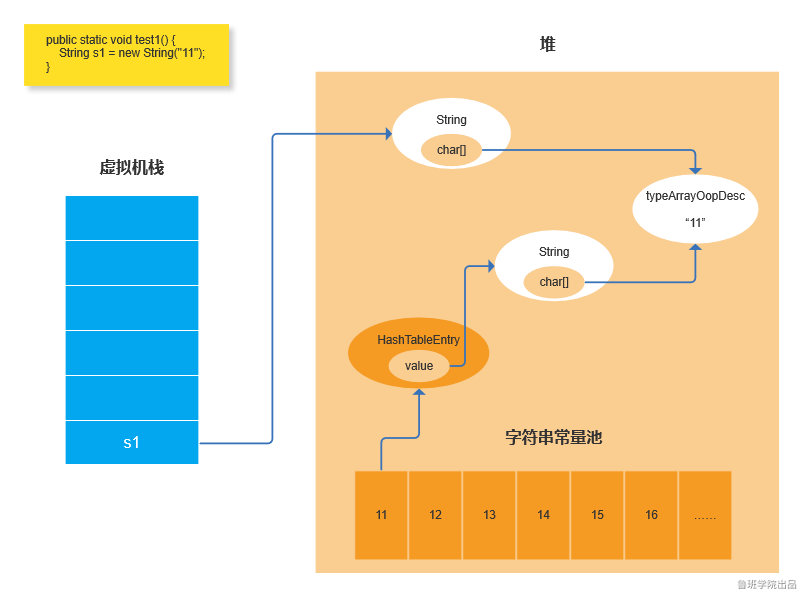
4:通过 new String 创建字符串:new 操作会在堆里创建一个String对象,这个String对象的char数组还是指向typeArrayOopDesc,如果字符串常量池中已经存在了当前字符串,
还是会指向已经存在的地址。
因此可以看到上面举得例子,s1,s2,s3变量中的char数组的内存地址都是一样的!!
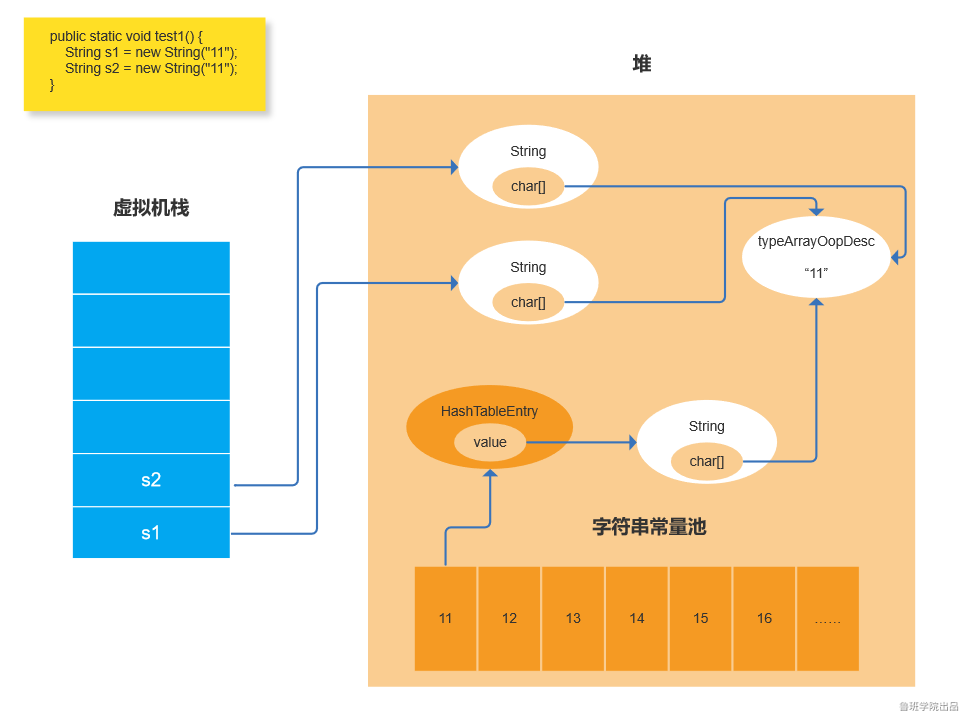
5:创建两个new String方式的字符串,常量池中还是只有一个,但是两个s1,s2地址是不一样的,但是其下的char数组还是会指向同一个typeArrayOopDesc。
字符串拼接
public static void test1(){
String s1="1";
String s2="2";
String s3=new String("3");
String s6="12";
String s7="13";
String s4=s1+s2;
String s5=s1+s3;
}
我们首先看下字符串拼接底层是怎样实现的。通过 javap -c TestString.class 可以查看字节码指令。或者直接通过idea查看.class文件
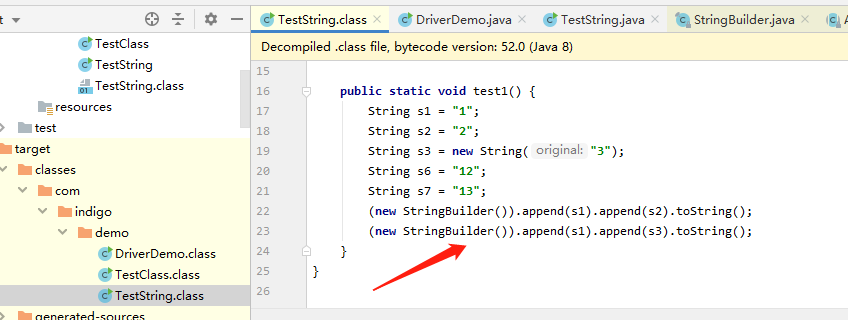
我们看到String s4=s1+s2; String s5=s1+s3; 底层都是通过StringBuilder#append来拼接之后再toString得到的。但是不仅仅只有这一点区别!
我们继续看StringBuilder#toString方法。发现是调用了 new String(value, 0, count); 的构造方法。
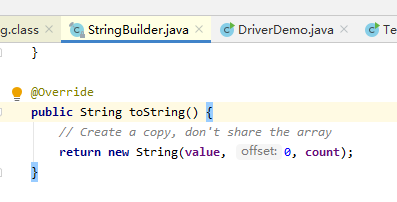
我们通过Debug看下,通过拼接得到的字符串有什么不一样的地方?
首先看下 String s6="12"; String s4=s1+s2; 的区别,s1+s2得到的字符串也是"12", 这里char数组地址竟然不一样了!!!
我们上面知道常量池中如果已经有了这个字符串,下面创建同样的字符串的时候都是从常量池中获取,char数组的地址都是一样的。这里竟然不一样了!
这就是拼接字符串的不同之处,拼接出来的字符串并没有从常量池中获取,创建出来的字符串也不会放入字符串常量池中,s6是常量池中的字符串,s4里面的char数组就是普通的堆里面的数组。s5拼接的字符串也是这样的。
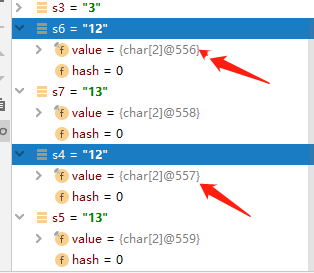
我们这里把这个这个构造函数和常量字符串构建单独拉出来看下。
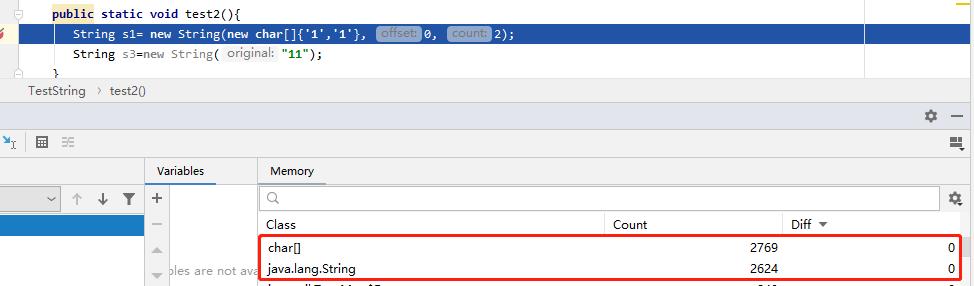
第一行执行完:String,char[] 各新增一个。
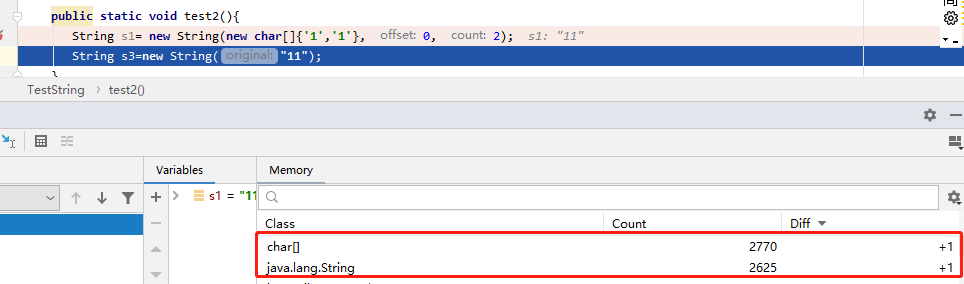
第二行执行完:新增了两个String,一个char[]数组 ,而且看到s1,s3字符串虽然一样的,但是char[] 却不再一样了。这也就是s1字符串并不在常量池中,s3会把字符串放入常量池中。
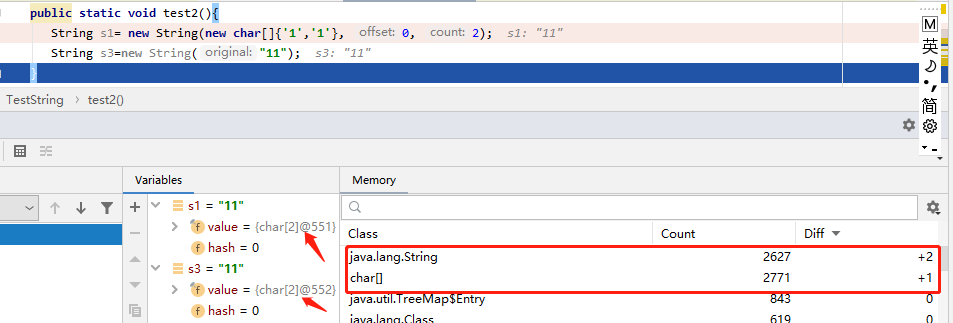
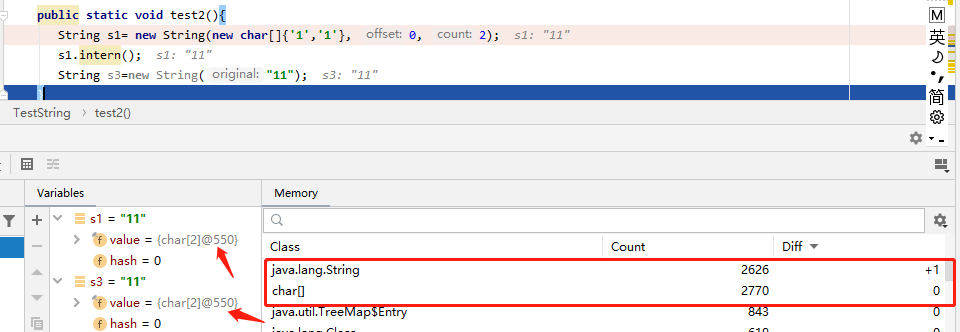
虽然String s=s1+s2这种拼接的字符串并不会放到字符串常量池中,但是我们可以调用String#intern方法把当前的字符串主动放入字符串常量池中。
我们还是以上面这个例子,加一行代码:
第一行执行完结果:
第二行执行完结果:没有什么明显的结果
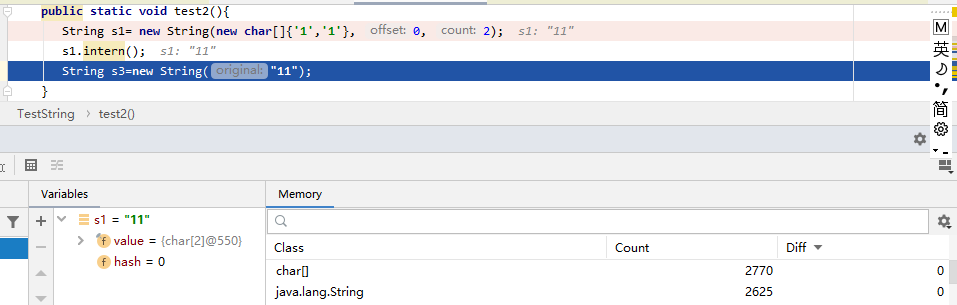
第三行执行完: 只新增了一个String对象,而且char[] 数组地址是一样的。这是因为s1.intern()方法,把s1的字符串放入常量池中了,s3创建的时候,只是在堆里再创建一个新的String对象就可以了,这个在上面的图解中也说明了。
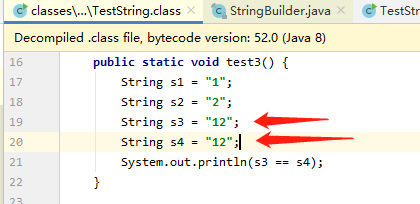
还有一种特殊情况我们来看下,有final修饰符修饰的字符串之间的拼接情况:
public static void test3(){
final String s1="1";
final String s2="2";
String s3=s1+s2;
String s4="12";
System.out.println(s3==s4);
}
因为s1,s2是final修饰的,在编译阶段就放入了字节码的常量池中,s3其实在编译阶段已经指向了常量池中的"12"了。
我们通过编译后的class也可以看到:所以比较肯定是true。
// 只会创建一个String 一个char[],编译的时候就优化成"帅帅"
String s="帅"+"帅";
// 三个String,三个char数组对象,
String s2 = "帅" + new String("真帅");
JVM(七)字符串详解的更多相关文章
- SQL Server日期时间格式转换字符串详解
本文我们主要介绍了SQL Server日期时间格式转换字符串的相关知识,并给出了大量实例对其各个参数进行对比说明,希望能够对您有所帮助. 在SQL Server数据库中,SQL Server日期时间格 ...
- Swift_字符串详解(String)
Swift_字符串详解(String) 类型别名 //类型别名 fileprivate func testTypeAliases() { let index = String.Index.self p ...
- MS SQL Server 数据库连接字符串详解
MS SQL Server 数据库连接字符串详解 原地址:http://blog.csdn.net/jhhja/article/details/6096565 问题 : 超时时间已到.在从池中获取连接 ...
- JVM类加载机制详解(二)类加载器与双亲委派模型
在上一篇JVM类加载机制详解(一)JVM类加载过程中说到,类加载机制的第一个阶段加载做的工作有: 1.通过一个类的全限定名(包名与类名)来获取定义此类的二进制字节流(Class文件).而获取的方式,可 ...
- JVM类加载机制详解
引言 如下图所示,JVM类加载机制分为五个部分:加载,验证,准备,解析,初始化,下面我们就分别来看一下这五个过程. 加载 在加载阶段,虚拟机需要完成以下三件事情: 1)通过一个类的全限定名来获取定义此 ...
- Python变量和字符串详解
Python变量和字符串详解 几个月前,我开始学习个人形象管理,从发型.妆容.服饰到仪表仪态,都开始做全新改造,在塑造个人风格时,最基础的是先了解自己属于哪种风格,然后找到参考对象去模仿,可以是自己欣 ...
- C语言中字符串详解
C语言中字符串详解 字符串时是C语言中非常重要的部分,我们从字符串的性质和字符串的创建.程序中字符串的输入输出和字符串的操作来对字符串进行详细的解析. 什么是字符串? C语言本身没有内置的字符串类型, ...
- JVM运行原理详解
1.JVM简析: 作为一名Java使用者,掌握JVM的体系结构也是很有必要的. 说起Java,我们首先想到的是Java编程语言,然而事实上,Java是一种技术,它由四方面组成:Ja ...
- JVM 内存溢出详解(栈溢出,堆溢出,持久代溢出、无法创建本地线程)
出处: http://www.jianshu.com/p/cd705f88cf2a 1.内存溢出和内存泄漏的区别 内存溢出 (Out Of Memory):是指程序在申请内存时,没有足够的内存空间供 ...
随机推荐
- Liunx运维(五)-信息显示与搜索文件命令
文档目录: 一.uname:显示系统信息 二.hostname:显示或设置系统的主机名 三.dmesg:系统启动异常诊断 四.stat:显示文件或文件系统状态 五.du:统计磁盘空间使用情况 六.da ...
- 部署docker镜像仓库及高可用
下载地址: https://github.com/goharbor/harbor/releases 安装harbor服务器: 安装harbor root@harbor-vm1:/usr/loc ...
- burpsuite暴力破解之四种方式
给出字典排列.详情: 1. 2. 第一项:snipper(中译:狙击手) 1.为两个参数添加payload并且选中snipper,同时指定一个字典. 2.开始attack,并且给出响应结果. 可见有两 ...
- OSPF --- 不规则区域实验
OSPF不规则区域实验: 一.知识点整理: OSPF中路由器的角色(看图): 骨干路由器:路由器所有接口属于area 0 -->R3 非骨干路由器:路由器所有接口属于非area 0 --&g ...
- matplotlib学习日记(十)-划分画布的主要函数
(1)函数subplot()绘制网格区域中的几何形状相同的子区布局 import matplotlib.pyplot as plt import numpy as np '''函数subplot的介绍 ...
- Java学习_面向对象编程
抽象类 一个class定义了方法,但没有具体执行代码,这个方法就是抽象方法,抽象方法用abstract修饰.因为抽象类本身被设计成只能用于被继承,因此,抽象类可以强迫子类实现其定义的抽象方法,否则编译 ...
- 实体类转json 和 json转实体类
1.new JSONObject().toJSONString(rootEntity) JSONObject.toJSONString(specPrices)//specPrices实体类 2. ...
- POLARDB与其他关系型数据库对比
https://baijiahao.baidu.com/s?id=1610828839695075926&wfr=spider&for=pc 前言 在数据库的选择上,MySQL成为中国 ...
- GC算法与回收策略
算法: 标记-清理 :首先标记出需要回收的对象 ,然后统一回收待标记的对象. 缺点:易产生大量空间碎片,空间碎片太多导致程序在运行过程中产生大对象时 因为空间不足导致容易导致另一个垃圾收集动作 标记 ...
- ACID隔离性
数据库ACID 一致性 原子性 隔离性 持久性 隔离性: 1.读未提交 2.读已提交 3.可重复读 4.串行 读未提交:容易引起脏读 读已提交:容易引起幻读(前后读到的行数不一致) 场景: A事务 ...