MFiX-DEM中的串行碰撞搜索
在计算颗粒碰撞的时候,需要进行neighbor颗粒的搜寻,只知道大概是基于网格与颗粒绑定的方式,但是具体的实现方式还是比较模糊。搜寻部分代码如下 (mfix-19.2.2):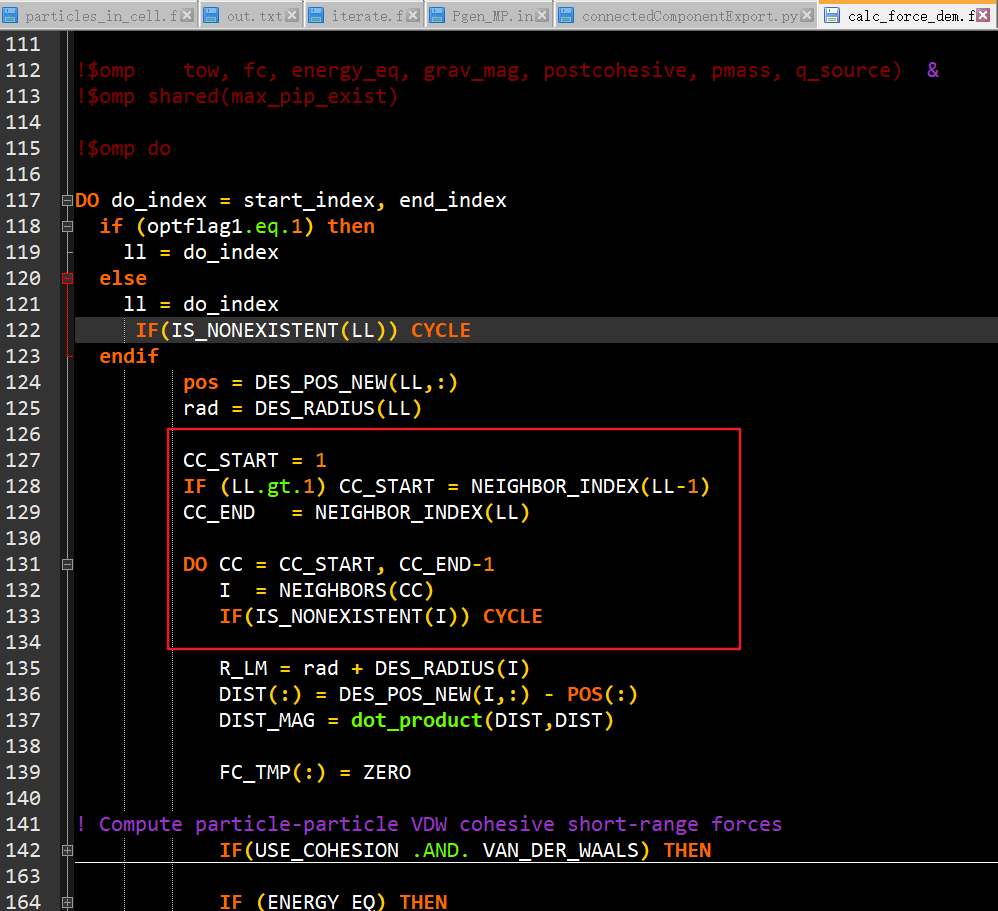
可以直接观察到的是,这里用到了两层do循环,外层循环是遍历所有颗粒的ID,LL,这个ID是每个颗粒的全局标记。内层循环用来遍历颗粒LL周围的颗粒,ID为I。主要问题就在于上图红色方框的内容的含义。
通过借助mfix-16.1版这部分代码debug内容的输出可以大概理解上面的内容。16版代码如下: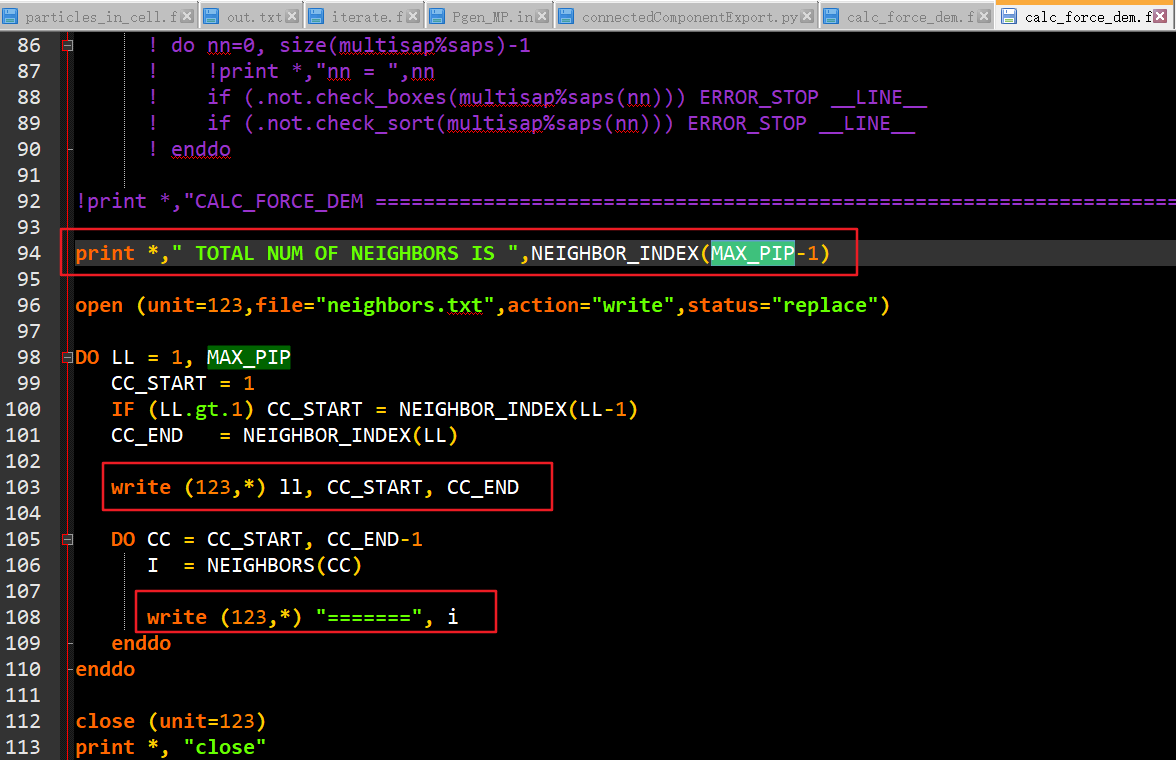
在这里,外层循环输出了三个变量,LL,CC_START,CC_END,内层循环输出了I。输出结果为: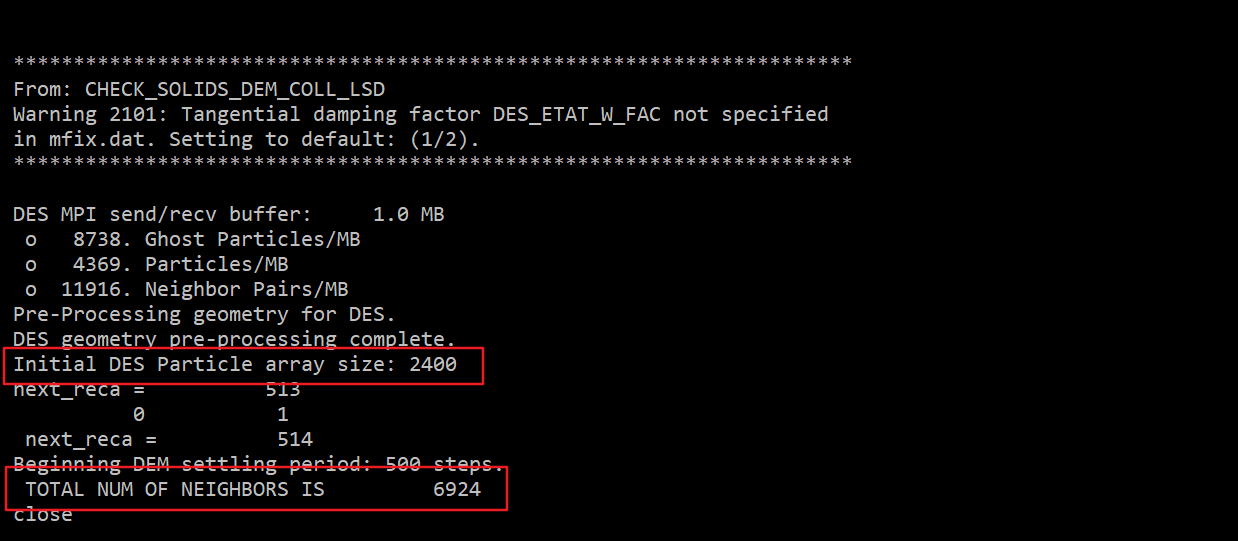
从上面的输出可以看到NEIGHBOR_INDEX(MAX_PIP-1)返回的是总的neighbor数量,从下面的输出可以看出CC_START = NEIGHBOR_INDEX(LL-1)和CC_END = NEIGHBOR_INDEX(LL)分别代表颗粒LL的neighbor遍历区间,下面说明一下这里的逻辑。
通过观察输出最后可以得到结论,首先程序会得到所有neighbor颗粒的数量,然后用数组NEIGHBOR_INDEX(:)来给所有neighbor颗粒编号,例如这个算例中一共有2400个颗粒,neighbor颗粒一共有6924个,因此编号从1~6924。
颗粒LL的neighbor颗粒编号则是从NEIGHBOR_INDEX(LL-1)到NEIGHBOR_INDEX(LL) - 1,这个编号是连续的,然后用这个编号又可以获取到neighbor颗粒的ID,如I = NEIGHBORS(CC)。
需要注意的是,这里在遍历neighbor的时候,没有出现重复计数的情况,用上面的图来举例:
47号颗粒的neighbor编号为75~77(CC = CC_START, CC_END-1),也就是说它有三个neighbor,对应的ID为48,78,79。48号颗粒的neighbor编号为78~80,对应的ID为49,79,80。可以看到48号颗粒的neighbor不再包含47号,因为47号颗粒遍历neighbor的时候已经将48号包含进去了,这样避免了重复循环带来的额外开销。
因此NEIGHBOR_INDEX(MAX_PIP-1)返回的是总的neighbor数量,因为最后一个颗粒MAX_PIP的neighbor编号一定是最大的编号,后面不再有未被遍历的neighbor了,如下图所示: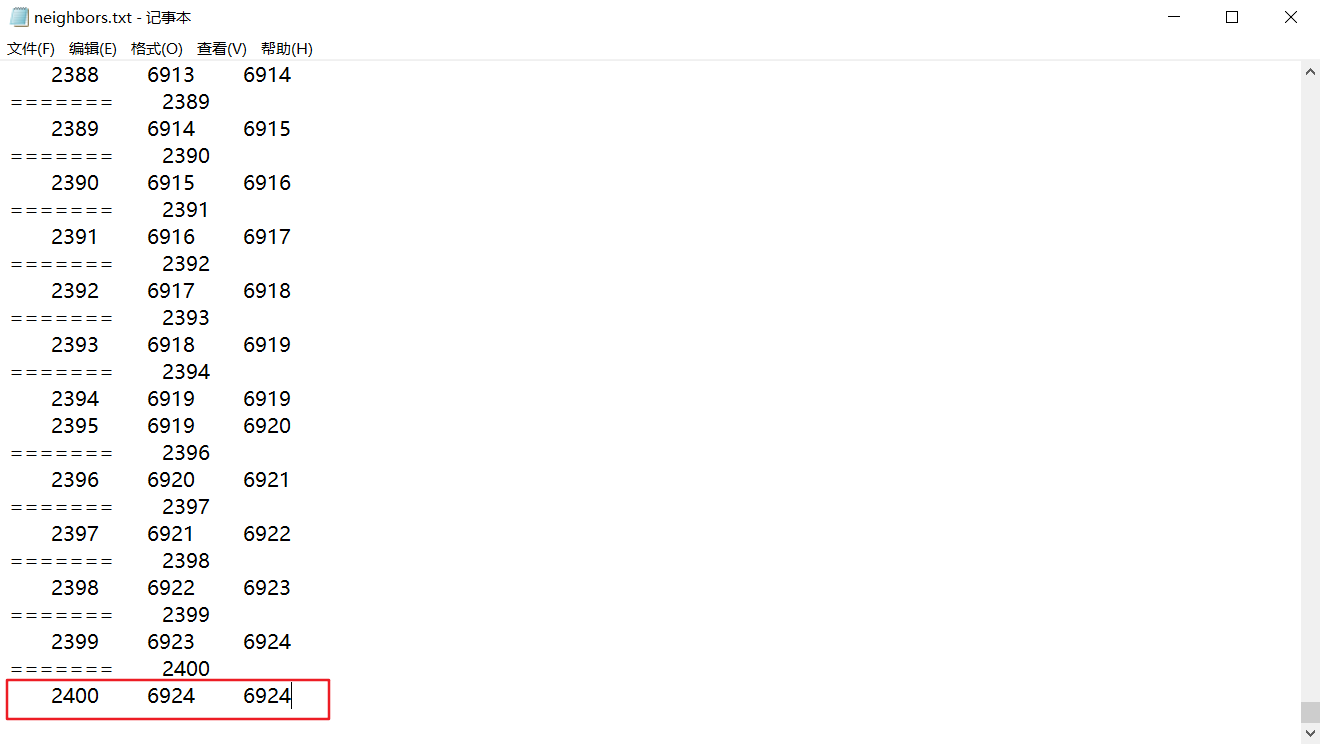
MFiX-DEM中的串行碰撞搜索的更多相关文章
- java面试一日一题:再谈垃圾回收器中的串行、并行、并发
问题:请讲下java中垃圾回收器的串行.并行.并发 分析:该问题主要考察在垃圾回收过程中垃圾回收线程和用户线程的关系 回答要点: 主要从以下几点去考虑, 1.串行.并行.并发的概念 2.如何考虑串行. ...
- 从DataReader中手动串行化JSON
void WriteDataReader(StringBuilder sb, IDataReader reader) { ) { sb.Append("null"); return ...
- iOS:对GCD中 同步、异步、并行、串行的见解
1.GCD-同步执行多线程时 GCD中不管向什么类型的队列加同步任务,实际上都会加到当前线程中(一般为主线程). 2.GCD-异步执行多线程时 GCD中不管向什么类 ...
- 基于51的串行通讯原理及协议详解(uart)
串行与并行通讯方式并行:控制简单,传输速度快.线多,长距离成本较高且同时接受困难.串行:将数据字节分成一位一位的行驶在一条传输线上进行传输.如图: 同步与异步串行通讯方式同步串行通讯方式:同步通讯 ...
- ios--进程/多线程/同步任务/异步任务/串行队列/并行队列(对比分析)
现在先说两个基本的概念,啥是进程,啥是线程,啥又是多线程;先把这两个总是给弄清再讲下面的 进程:正在进行的程序,我们就叫它进程. 线程:线程就是进程中的一个独立的执行路径.这句话怎么理解呢! 一个程序 ...
- IOS多线程知识总结/队列概念/GCD/主队列/并行队列/全局队列/主队列/串行队列/同步任务/异步任务区别(附代码)
进程:正在进行中的程序被称为进程,负责程序运行的内存分配;每一个进程都有自己独立的虚拟内存空间 线程:线程是进程中一个独立的执行路径(控制单元);一个进程中至少包含一条线程,即主线程 队列 dispa ...
- IOS多线程知识总结/队列概念/GCD/串行/并行/同步/异步
进程:正在进行中的程序被称为进程,负责程序运行的内存分配;每一个进程都有自己独立的虚拟内存空间: 线程:线程是进程中一个独立的执行路径(控制单元);一个进程中至少包含一条线程,即主线程. 队列:dis ...
- QDataStream类参考(串行化数据,可设置低位高位,以及版本号),还有一个例子
QDataStream类提供了二进制数据到QIODevice的串行化. #include 所 有成员函数的列表. 公有成员 QDataStream () QDataStream ( QIODevice ...
- MFC如何生成一个可串行化的类
一.MFC允许对象在程序运行的整个过程中持久化的串行化机制 (1)串行化是指向持久化存储媒介(如一个磁盘文件)读或写对象的过程. (2)串行化用于在程序运行过程时或之后修复结构化数据(如C++类或结构 ...
随机推荐
- Mybatis快速逆向生成代码
先下载生成器的文件, 并在eclipse或者IDEA里面打开这个工程 热乎乎的链接 然后配置一下 选择你需要生成的数据的ip和端口 点击运行入口函数 运行成功 接着在浏览器输入localhost: 这 ...
- powershell中使用Send-MailMessage发送邮件
在powershell中我们可以使用Send-MailMessage发送邮件,一般都是有这个命令的 笔者的总结是鉴于公司的环境的,大家在借鉴时,需要根据自己的实际情况进行修改 1.你笔者测试的格式如下 ...
- Oracle学习(二)SQL高级--表数据相关
SQL高级语句 top / limit / rownum / percent (前XXX条数据) --top(SQL Server / MS Access) select top 条数 from 表; ...
- Java随谈(三)如何创建好一个对象?
本文推荐阅读时间30分钟 大家都知道,在编写Java程序里,一般就是处理各种各样的对象,那么,你知道一共有多少种创建对象的方式吗? 希望大家能稍微思考一下再往下翻. 答案是4种 new 一个对象 反射 ...
- react 中发布订阅模式使用
react 中发布订阅模式使用 场景 怎么能将设计模式应用到我们的 React 项目中?以前一直在思考这个问题. 场景一 模块 A 模块 B 需要用到同一个数据 data,A 和 B 都会修改这份数据 ...
- 国际化的实现i18n--错误码国际化以及在springboot项目中使用
国际化 ,英文叫 internationalization 单词太长 ,又被简称为 i18n(取头取尾中间有18个字母); 主要涉及3个类: Locale用来设置定制的语言和国家代码 Resource ...
- Apache Shiro 1.3.2入门
简介 Apache Shiro是一个功能强大且灵活的开放源代码安全框架,可以清楚地处理认证,授权,企业会话管理和加密.Apache Shiro的首要目标是易于使用和理解.有时候安全性可能非常复杂和痛苦 ...
- 梯度提升树 Gradient Boosting Decision Tree
Adaboost + CART 用 CART 决策树来作为 Adaboost 的基础学习器 但是问题在于,需要把决策树改成能接收带权样本输入的版本.(need: weighted DTree(D, u ...
- HTML+CSS系列:登录界面实现
一.效果 二.具体实现 1.index.html <!DOCTYPE html> <html> <head> <meta charset="utf- ...
- C++ | 继承(基类,父类,超类),(派生类,子类)
转载:https://blog.csdn.net/Sherlock_Homles/article/details/82927515 文章参考:https://blog.csdn.net/war1111 ...