Ribbon提供的负载均衡算法IRule(四)
一、Ribbon算法的介绍
Ribbon的源码地址:https://github.com/Netflix/ribbon
IRule:根据特定算法中从服务器列表中选取一个要访问的服务,Ribbon默认的算法为ZoneAvoidanceRule;
Ribbon中的7中负载均衡算法:
(1)RoundRobinRule:轮询;
(2)RandomRule:随机;
(3)AvailabilityFilteringRule:会先过滤掉由于多次访问故障而处于断路器状态的服务,还有并发的连接数量超过阈值的服务,然后对剩余的服务列表按照轮询策略进行访问;
(4)WeightedResponseTimeRule:根据平均响应时间计算所有服务的权重,响应时间越快的服务权重越大被选中的概率越大。刚启动时如果统计信息不足,则使用RoundRobinRule(轮询)策略,等统计信息足够,会切换到WeightedResponseTimeRule;
(5)RetryRule:先按照RoundRobinRule(轮询)策略获取服务,如果获取服务失败则在指定时间内进行重试,获取可用的服务;
(6)BestAvailableRule:会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务;
(7)ZoneAvoidanceRule:复合判断Server所在区域的性能和Server的可用性选择服务器,在没有Zone的情况下是类似轮询的算法;
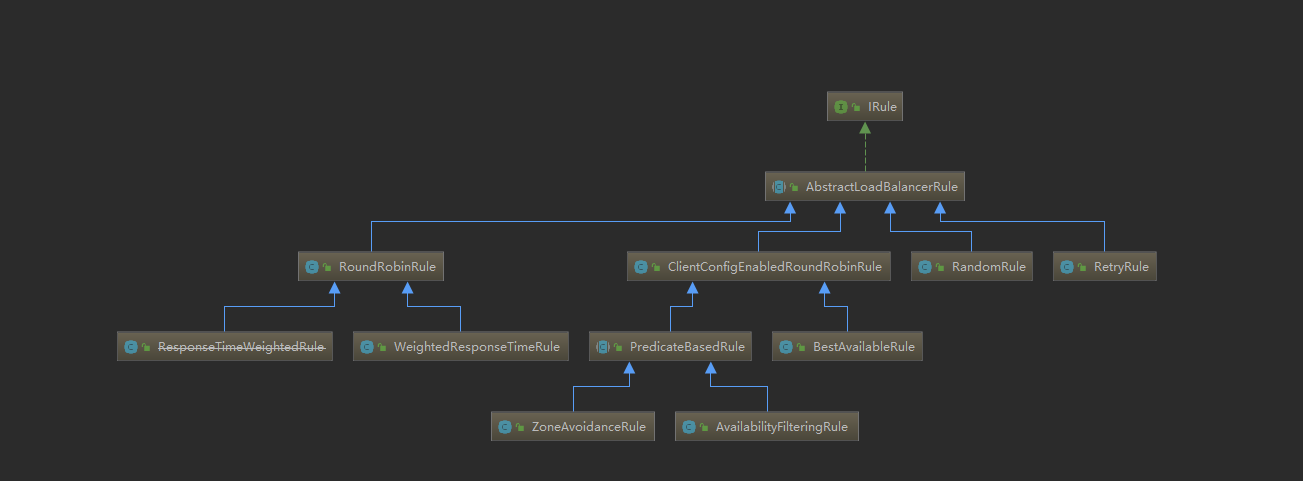
ribbion的负载均衡算法结构:
二、配置指定的负载均衡算法
1、打开消费者工程,增加如下的配置
@Configuration
public class ConfigBean
{
@Bean
@LoadBalanced //Ribbon 是客户端负载均衡的工具;
public RestTemplate getRestTemplate()
{
return new RestTemplate();
} //配置负载均衡的策略为随机,默认算法为轮询算法
@Bean
public IRule myRule()
{
//return new RoundRobinRule();
return new RandomRule();
}
}
2、启动类增加 @EnableEurekaClient 注解
@SpringBootApplication
@EnableEurekaClient //本服务启动后自动注册到eureka中(如果用了注册中心记得加)
public class DeptProvider8001_App
{
public static void main(String[] args)
{
SpringApplication.run(DeptProvider8001_App.class, args);
}
}
3、然后重启这个消费者服务,访问;可以查看到随机访问生产者服务。
三、RetryRule(重试)
//具备重试机制的实例选择功能
public class RetryRule extends AbstractLoadBalancerRule {
//默认使用RoundRobinRule实例
IRule subRule = new RoundRobinRule();
//阈值为500ms
long maxRetryMillis = 500; public RetryRule() {
} public RetryRule(IRule subRule) {
this.subRule = (subRule != null) ? subRule : new RoundRobinRule();
} public RetryRule(IRule subRule, long maxRetryMillis) {
this.subRule = (subRule != null) ? subRule : new RoundRobinRule();
this.maxRetryMillis = (maxRetryMillis > 0) ? maxRetryMillis : 500;
} public void setRule(IRule subRule) {
this.subRule = (subRule != null) ? subRule : new RoundRobinRule();
} public IRule getRule() {
return subRule;
} public void setMaxRetryMillis(long maxRetryMillis) {
if (maxRetryMillis > 0) {
this.maxRetryMillis = maxRetryMillis;
} else {
this.maxRetryMillis = 500;
}
} public long getMaxRetryMillis() {
return maxRetryMillis;
} @Override
public void setLoadBalancer(ILoadBalancer lb) {
super.setLoadBalancer(lb);
subRule.setLoadBalancer(lb);
} public Server choose(ILoadBalancer lb, Object key) {
long requestTime = System.currentTimeMillis();
long deadline = requestTime + maxRetryMillis; Server answer = null; answer = subRule.choose(key); if (((answer == null) || (!answer.isAlive()))
&& (System.currentTimeMillis() < deadline)) { InterruptTask task = new InterruptTask(deadline
- System.currentTimeMillis());
//反复重试
while (!Thread.interrupted()) {
//选择实例
answer = subRule.choose(key);
//500ms内没选择到就返回null
if (((answer == null) || (!answer.isAlive()))
&& (System.currentTimeMillis() < deadline)) {
/* pause and retry hoping it's transient */
Thread.yield();
}
else //若能选择到实例,就返回
{
break;
}
} task.cancel();
} if ((answer == null) || (!answer.isAlive())) {
return null;
} else {
return answer;
}
} @Override
public Server choose(Object key) {
return choose(getLoadBalancer(), key);
} @Override
public void initWithNiwsConfig(IClientConfig clientConfig) {
}
}
四、WeightedResponseTimeRule(权重)
WeightedResponseTimeRule这个策略每30秒计算一次服务器响应时间,以响应时间作为权重,响应时间越短的服务器被选中的概率越大。它有一个LoadBalancerStats类,这里面有三个缓存,它的作用是记住发起请求服务提供者的一些参数,例如响应时间
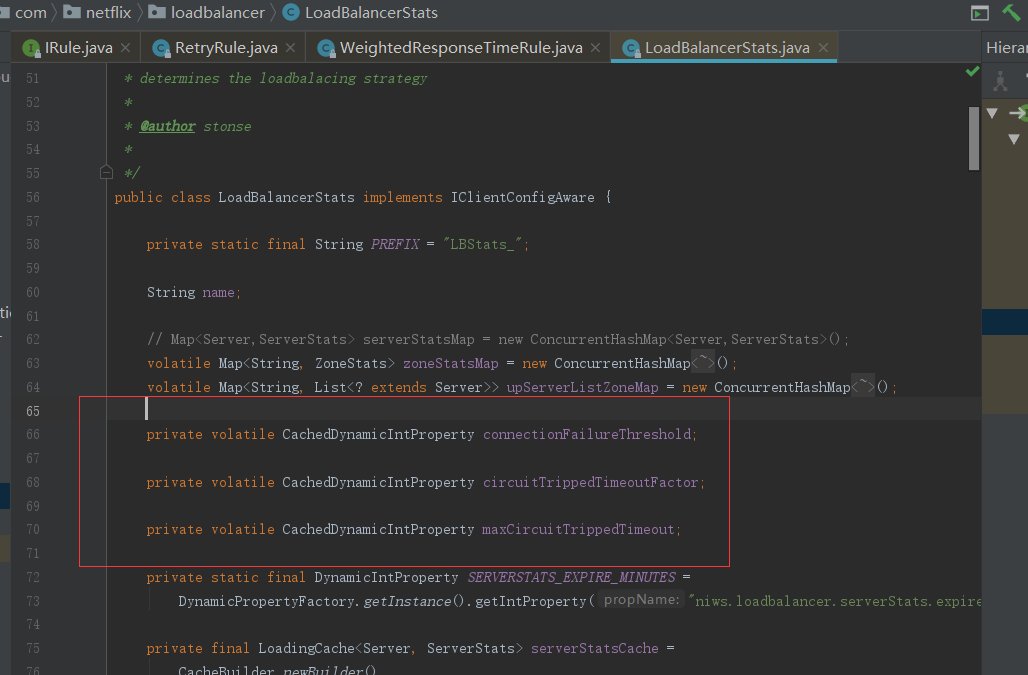
有了缓存数据后权重是怎么处理的呢,下面看WeightedResponseTimeRule,它有一个定时任务,定时去计算权重
//该策略是对RoundRobinRule的扩展,增加了根据实例的运行情况来计算权重
//并根据权重来挑选实例,以达到更优的分配效果
public class WeightedResponseTimeRule extends RoundRobinRule { public static final IClientConfigKey<Integer> WEIGHT_TASK_TIMER_INTERVAL_CONFIG_KEY = new IClientConfigKey<Integer>() {
@Override
public String key() {
return "ServerWeightTaskTimerInterval";
} @Override
public String toString() {
return key();
} @Override
public Class<Integer> type() {
return Integer.class;
}
};
//默认30秒执行一次
public static final int DEFAULT_TIMER_INTERVAL = 30 * 1000; private int serverWeightTaskTimerInterval = DEFAULT_TIMER_INTERVAL; private static final Logger logger = LoggerFactory.getLogger(WeightedResponseTimeRule.class); // 存储权重的对象,该List中每个权重所处的位置对应了负载均衡器维护实例清单中所有实例在
//清单中的位置。
private volatile List<Double> accumulatedWeights = new ArrayList<Double>(); private final Random random = new Random(); protected Timer serverWeightTimer = null; protected AtomicBoolean serverWeightAssignmentInProgress = new AtomicBoolean(false); String name = "unknown"; public WeightedResponseTimeRule() {
super();
} public WeightedResponseTimeRule(ILoadBalancer lb) {
super(lb);
} @Override
public void setLoadBalancer(ILoadBalancer lb) {
super.setLoadBalancer(lb);
if (lb instanceof BaseLoadBalancer) {
name = ((BaseLoadBalancer) lb).getName();
}
initialize(lb);
} void initialize(ILoadBalancer lb) {
if (serverWeightTimer != null) {
serverWeightTimer.cancel();
}
serverWeightTimer = new Timer("NFLoadBalancer-serverWeightTimer-"
+ name, true);
//启动一个定时任务,用来为每个服务实例计算权重,默认30秒执行一次,调用DynamicServerWeighTask方法,向下找
serverWeightTimer.schedule(new DynamicServerWeightTask(), 0,
serverWeightTaskTimerInterval);
// do a initial run
ServerWeight sw = new ServerWeight();
sw.maintainWeights(); Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
public void run() {
logger
.info("Stopping NFLoadBalancer-serverWeightTimer-"
+ name);
serverWeightTimer.cancel();
}
}));
} public void shutdown() {
if (serverWeightTimer != null) {
logger.info("Stopping NFLoadBalancer-serverWeightTimer-" + name);
serverWeightTimer.cancel();
}
} List<Double> getAccumulatedWeights() {
return Collections.unmodifiableList(accumulatedWeights);
} /*
第一步:生成一个[0,maxTotalWeight]的随机值
第二步:遍历权重列表,比较权重值与随机数的大小,如果权重值大于随机数,就拿当前权重列表
的索引值去服务实例表获取具体的实例。
*/
@edu.umd.cs.findbugs.annotations.SuppressWarnings(value = "RCN_REDUNDANT_NULLCHECK_OF_NULL_VALUE")
@Override
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
return null;
}
Server server = null; while (server == null) {
// get hold of the current reference in case it is changed from the other thread
List<Double> currentWeights = accumulatedWeights;
if (Thread.interrupted()) {
return null;
}
List<Server> allList = lb.getAllServers(); int serverCount = allList.size(); if (serverCount == 0) {
return null;
} int serverIndex = 0; // 获取最后一个实例的权重
double maxTotalWeight = currentWeights.size() == 0 ? 0 : currentWeights.get(currentWeights.size() - 1);
// 如果最后一个实例的权重小于0.001,则采用父类实现的现象轮询的策略
if (maxTotalWeight < 0.001d || serverCount != currentWeights.size()) {
server = super.choose(getLoadBalancer(), key);
if(server == null) {
return server;
}
} else {
// 产生一个[0,maxTotalWeight]的随机值
double randomWeight = random.nextDouble() * maxTotalWeight;
int n = 0;
for (Double d : currentWeights) {
//如果遍历维护的权重清单,若权重值大于随机得到的数值,就选择这个实例
if (d >= randomWeight) {
serverIndex = n;
break;
} else {
n++;
}
} server = allList.get(serverIndex);
} if (server == null) {
/* Transient. */
Thread.yield();
continue;
} if (server.isAlive()) {
return (server);
} // Next.
server = null;
}
return server;
} class DynamicServerWeightTask extends TimerTask {
public void run() {
ServerWeight serverWeight = new ServerWeight();
try {
//点击maintainWeights可以进入权重计算的方法
serverWeight.maintainWeights();
} catch (Exception e) {
logger.error("Error running DynamicServerWeightTask for {}", name, e);
}
}
} class ServerWeight {
/*该函数主要分为两个步骤
1 根据LoadBalancerStats中记录的每个实例的统计信息,累计所有实例的平均响应时间,
得到总的平均响应时间totalResponseTime,该值用于后面的计算。
2 为负载均衡器中维护的实例清单逐个计算权重(从第一个开始),计算规则为:
weightSoFar+totalResponseTime-实例平均相应时间,其中weightSoFar初始化为0,并且
每计算好一个权重需要累加到weightSoFar上供下一次计算使用。
示例:4个实例A、B、C、D,它们的平均响应时间为10,40,80,100,所以总的响应时间为
230,每个实例的权重为总响应时间与实例自身的平均响应时间的差的累积所得,所以实例A
B,C,D的权重分别为:
A:230-10=220
B:220+230-40=410
C:410+230-80=560
D:560+230-100=690
需要注意的是,这里的权重值只是表示各实例权重区间的上限,并非某个实例的优先级,所以不
是数值越大被选中的概率就越大。而是由实例的权重区间来决定选中的概率和优先级。
A:[0,220]
B:(220,410]
C:(410,560]
D:(560,690)
实际上每个区间的宽度就是:总的平均响应时间-实例的平均响应时间,所以实例的平均响应时间越短
,权重区间的宽度越大,而权重区间宽度越大被选中的概率就越大。
*/
public void maintainWeights() {
ILoadBalancer lb = getLoadBalancer();
if (lb == null) {
return;
} if (!serverWeightAssignmentInProgress.compareAndSet(false, true)) {
return;
} try {
logger.info("Weight adjusting job started");
AbstractLoadBalancer nlb = (AbstractLoadBalancer) lb;
//根据负载均衡器的状态信息进行计算
LoadBalancerStats stats = nlb.getLoadBalancerStats();
if (stats == null) {
// no statistics, nothing to do
return;
}
double totalResponseTime = 0;
// 计算所有实例的平均响应时间的总和
for (Server server : nlb.getAllServers()) {
// 如果服务实例的状态快照不在缓存中,那么这里会进行自动加载
ServerStats ss = stats.getSingleServerStat(server);
totalResponseTime += ss.getResponseTimeAvg();
}
// 逐个计算每个实例的权重
Double weightSoFar = 0.0; // create new list and hot swap the reference
List<Double> finalWeights = new ArrayList<Double>();
//weightSoFar+totalResponseTime-实例平均相应时间
for (Server server : nlb.getAllServers()) {
ServerStats ss = stats.getSingleServerStat(server);
double weight = totalResponseTime - ss.getResponseTimeAvg();
weightSoFar += weight;
finalWeights.add(weightSoFar);
}
//将计算结果进行保存
setWeights(finalWeights);
} catch (Exception e) {
logger.error("Error calculating server weights", e);
} finally {
serverWeightAssignmentInProgress.set(false);
} }
} void setWeights(List<Double> weights) {
this.accumulatedWeights = weights;
} @Override
public void initWithNiwsConfig(IClientConfig clientConfig) {
super.initWithNiwsConfig(clientConfig);
serverWeightTaskTimerInterval = clientConfig.get(WEIGHT_TASK_TIMER_INTERVAL_CONFIG_KEY, DEFAULT_TIMER_INTERVAL);
} }
五、利用配置来重设负载均衡算法

根据文档要求进行配置权重算法

Debugger一下,可以看到进入了自己定义的权重里面来了,而且服务节点数什么都是对的,所以如果Ribbon提供的算法你觉得不够好,你就可以自己定义一个,其实和我之前自定义一个GhyPing一样,自己定义一个类然后继承抽象类 AbstractLoadBalancerRule,实现它的抽象方法
Ribbon提供的负载均衡算法IRule(四)的更多相关文章
- 负载均衡算法(四)IP Hash负载均衡算法
/// <summary> /// IP Hash负载均衡算法 /// </summary> public static class IpHash { static Dicti ...
- 服务注册发现Eureka之三:Spring Cloud Ribbon实现客户端负载均衡(客户端负载均衡Ribbon之三:使用Ribbon实现客户端的均衡负载)
在使用RestTemplate来消费spring boot的Restful服务示例中,我们提到,调用spring boot服务的时候,需要将服务的URL写死或者是写在配置文件中,但这两种方式,无论哪一 ...
- Ribbon核心组件IRule及配置指定的负载均衡算法
Ribbon在工作时分为两步: 第一步:先选择 EurekaServer,它优先选择在同一个区域内负载较少的Server: 第二步:再根据用户指定的策略,在从Server取到的服务注册列表中选择一个地 ...
- Ribbon,主要提供客户侧的软件负载均衡算法。
Ribbon Ribbon,主要提供客户侧的软件负载均衡算法.Ribbon客户端组件提供一系列完善的配置选项,比如连接超时.重试.重试算法等.Ribbon内置可插拔.可定制的负载均衡组件.下面是用到的 ...
- spring-cloud-starter-ribbon提供客户端的软件负载均衡算法
Ribbon是什么? Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法,将Netflix的中间层服务连接在一起.Ribbon客户端组件提供一系列完善的配置项如连接超时 ...
- SpringCloud全家桶学习之客户端负载均衡及自定义负载均衡算法----Ribbon(三)
一.Ribbon是什么? Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端 负载均衡的工具(这里区别于nginx的负载均衡).简单来说,Ribbon是Netf ...
- Spring Cloud(十四):Ribbon实现客户端负载均衡及其实现原理介绍
年后到现在一直很忙,都没什么时间记录东西了,其实之前工作中积累了很多知识点,一直都堆在备忘录里,只是因为近几个月经历了一些事情,没有太多的经历来写了,但是一些重要的东西,我还是希望能坚持记录下来.正好 ...
- Ribbon源码分析(一)-- RestTemplate 以及自定义负载均衡算法
如果只是想看ribbon的自定义负载均衡配置,请查看: https://www.cnblogs.com/yangxiaohui227/p/13186004.html 注意: 1.RestTemplat ...
- springcloud第四步:ribbon搭建服务负载均衡
使用ribbon实现负载均衡 启动两个会员服务工程,端口号分别为8762.8763,订单服务 使用负载均衡策略轮训到会员服务接口. 什么是ribbon ribbon是一个负载均衡客户端 类似nginx ...
随机推荐
- [COCI2016-2017#1] Mag
[COCI2016-2017#1] Mag 题解 题目TP门 题目描述 你将获得一棵由无向边连接的树.树上每个节点都有一个魔力值. 我们定义,一条路径的魔力值为路径上所有节点魔力值的乘积除以路径上的节 ...
- iMindMap不同视图的应用技巧介绍
在刚开始使用iMindMap思维导图软件时,很多用户会习惯性地使用默认的Mind Map视图.因该视图布局自由,用户可以发挥自我创造力,进行多种形式的思维图表创建. 其实,除此之外,iMindMap还 ...
- mac下让iterm2记住远程ssh连接
brew安装sshpass brew install http://git.io/sshpass.rb 在根目录下建立passowrd目录用来管理密码,vim testserver 输入明文密码,保存 ...
- 【Azure微服务 Service Fabric 】Service Fabric中应用开启外部访问端口及微服务之间通过反向代理端口访问问题
问题描述 1) 当成功的在Service Fabric集群中部署了应用后,如何来访问呢?如果是一个Web服务,它的URL又是什么呢? 2) 当Service Fabric集群中,服务之间如需要相互访问 ...
- selenium元素定位不到问题分析及解决办法
最近正在学习写自动化测试脚本,遇到一个错误迟迟未解决,导致自信心大受挫败,甚至想放弃. 思考许久突然想到,我遇到的问题是否也有人会遇到,如果有的话问题就应该有解决办法了.没什么问题是百度解决不了的,如 ...
- 2018年第九届蓝桥杯【C++省赛B组】B、C、D、F、G 题解
B. 明码 #STL 题意 把每个字节转为2进制表示,1表示墨迹,0表示底色.每行2个字节,一共16行,布局是: 第1字节,第2字节 第3字节,第4字节 .... 第31字节, 第32字节 给定一段由 ...
- LeetCode 040 Combination Sum II
题目要求:Combination Sum II Given a collection of candidate numbers (C) and a target number (T), find al ...
- 领域设计:Entity与VO
本文探讨如下内容: 什么是状态 什么是标识 什么是Entity 什么是VO(ValueObject) 在设计中如何识别Entity和VO 要理解Entity和VO,需要先理解两个概念:「状态」和「标识 ...
- 半监督伪标签方法:Feature Space Regularization和Joint-Distance
原文链接 小样本学习与智能前沿 . 在这个公众号后台回复"200706",即可获得课件电子资源. @ 目录 Abstract I. INTRODUCTION Framework. ...
- 第三十二章、使用splitDockWidget和tabifyDockWidget嵌套布局QDockWidget的PyQt人机对话案例
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 一.引言 在第<第三十一章.containers容器类部件QDo ...