InnoDB 中的缓冲池(Buffer Pool)
本文主要说明 InnoDB Buffer Pool 的内部执行原理,其生效的前提是使用到了索引,如果没有用到索引会进行全表扫描。
结构
在 InnoDB 存储引擎层维护着一个缓冲池,通过其可以避免对磁盘频繁的IO操作。下面是其内部结构的概要图(实际没有这么简单,本文只着重说一下它的“读”、“写”缓存)。其本质就是将磁盘上的数据页移到内存中,以此来减少对磁盘数据的直接IO。
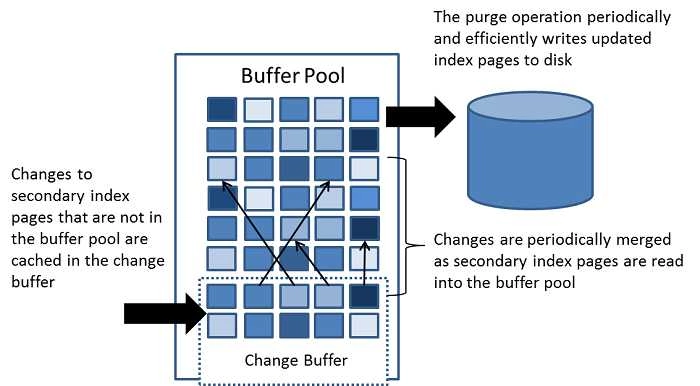
可以看到内部含有一个小区域,叫做 Change Buffer,这个是用 InnoDB 的 "写"缓存,而外面的是 InnoDB 的 “读”缓存。
读缓存
预读
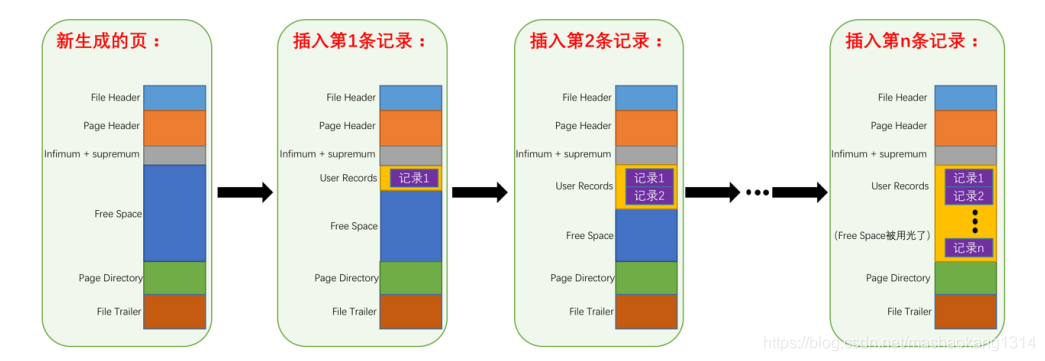
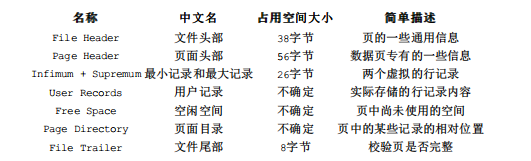
MySQL 在磁盘上读取数据时,一般都会使用缓冲池,而如果多次语句操作的是相邻的记录,那么就会多次进行磁盘读取,导致速度降低,所以 MySQL 一般在读取数据时都是采用预读方式,读取指定数据周围的多条数据。而在 InnoDB 引擎中的数据是以页为单位进行存储的,并且提出了“数据页”概念。数据页的结构如下,大小默认为 16K,关于数据页这里就不过多阐述,感兴趣可以查看原博客。对硬盘上的数据读取最小单位就是数据页。
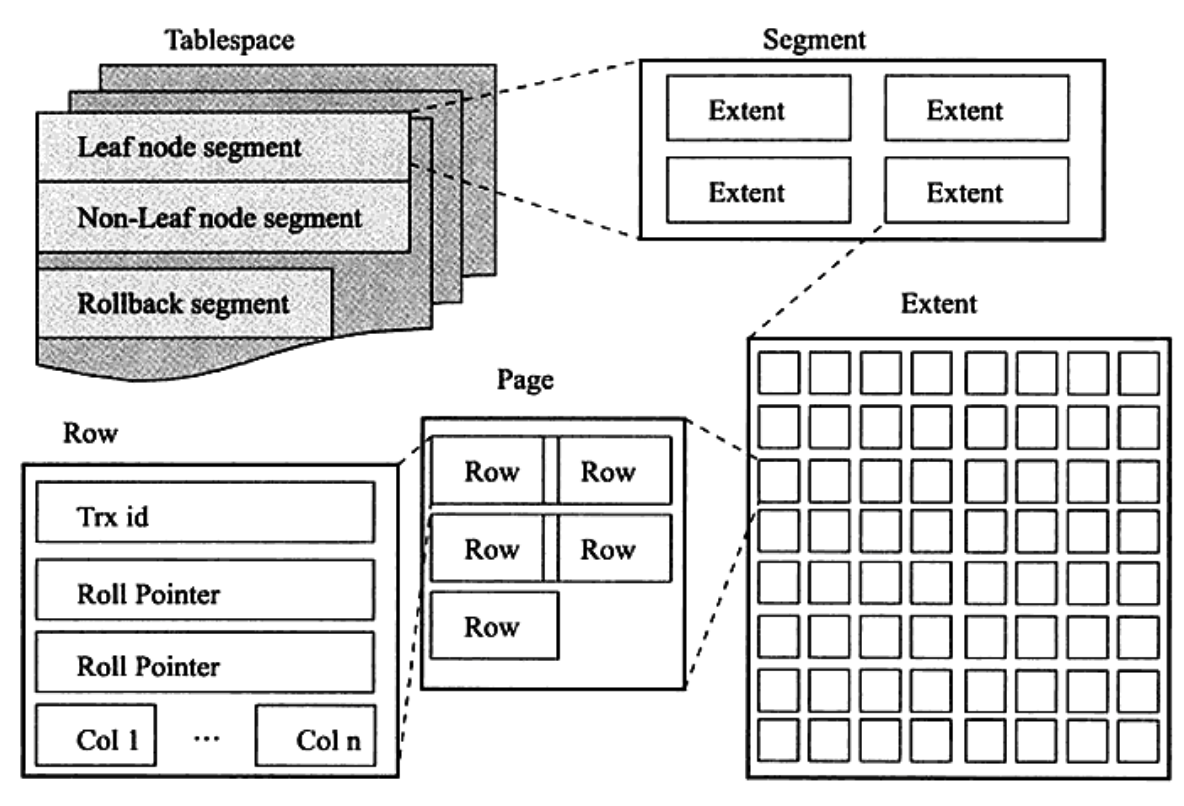
而在数据页上面,还分为区(Extent)、段(Segment)、表空间(Tablespace),它们之间的包含关系如下图。具体可以查看原博客。
InnoDB 引擎在预读时, 有两种预读算法。线性预读和随机预读。
1、线性预读(innodb_read_ahead_threshold)
选择是否预读下一个 Extent 的数据。有一个重要的参数 innodb_read_ahead_threshold,如果当前 Extent 中连续读取的数据页超过规定值,就会将下一个 Extent 的数据也读到缓冲池中。innodb_read_ahead_threshold 的范围是 0-64(因为一个 Extent 也就64页)。
2、随机预读(innodb_random_read_ahead)
用来设置是否将当前 Extent 的剩余页也预读到缓冲池中,由于这种预读性能不稳定,所以MySQL 5.5开始默认关闭。
缓冲池的LRU算法
InnoDB 的缓冲池数据的存储算法是改进版的 LRU 算法,以此来避免了传统 LRU 算法的两个问题,预读失效和缓冲池污染。
LRU 算法简单来说,如果用链表来实现,将最近命中(加载)的数据页移在头部,未使用的向后偏移,直至移除链表。这样的淘汰算法就叫做 LRU 算法。但是其会含有前面说得两个问题。
1、预读失效
在磁盘上读取数据时,可能会因为操作不当导致多个用不到的数据页加载到缓冲池。从而导致之前经常被使用的数据页缓存被无用的数据页挤到尾部,甚至被移出缓存,那么就会降低性能。而 InnoDB 的解决方案是将缓冲池分为两部分,新生代和老年代,比例默认为5:3,分别存储常用的数据页以及不常用的数据页,新生代位于头部,新生代位于尾部,这两部分都有头部和尾部。当从磁盘的数据页移入缓冲池中时,首先是放入老年代的头部,然后进行筛选,使用到的数据页会移入新生代的头部,未使用的数据页会随着时间流逝而慢慢移入老年代的尾部,直至淘汰。
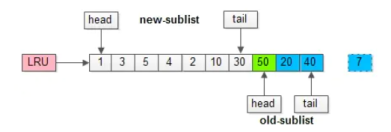
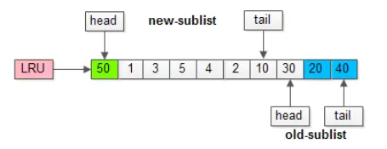
2、缓冲池污染。
在处理数据页时,如果需要对大量数据页进行筛选(但是没有用到),那么还是会使大量的热点数据页被挤出。如 select * from student where name like '张%';name字段包含索引,那么在执行时虽然会先加载到老年代的头部,但是因为每条数据都需要筛选,所以都会移入新生代头部,导致新生代热点数据页被挤到老年代甚至移除。InnoDB 为了解决这个问题,使用了 "老年代停留时间窗口" 机制,这个机制是设置一个时间,如果在老年代的数据页被调用后还需要去检查它在老年代的停留时间是否达到了这个规定时间,达到了才能移入新生代头部,否则只会移到老年代头部。
写缓存(Change Buffer)
写缓存(Change Buffer)在5.5之前叫做 插入缓存(insert Buffer),因为只支持插入的缓存,在随后版本又添加了 update、delete,所以改名 change Buffer。因为直接对磁盘进行IO操作会比较耗时,如果我们的程序在高并发的场景,同时某段时间写操作非常多,那么如果直接更新到磁盘上数据库的压力就会非常大,甚至崩溃。为了避免这种情况,可以错开高峰期,让数据在系统空闲时再更新到磁盘,那么该如何实现,Change Buffer就起到这样的作用。
执行
在更新语句进来时,首先会判断数据页缓存中有没有对应的数据,如果有直接更新对应的缓存数据,否则将其记录在 Change Buffer 中。随后(前面是哪种情况)再将这条sql依次写入 redo log、bin log(Server 层的日志,所有执行引擎都可以用,而 redo log 是InnoDB内部维护的,binlog 一般用于主从复制数据更新)。
redo log落盘的时机
将日志中的sql更新到硬盘上的操作叫做“落盘(merge)”。
1、mysql系统后台会定期落盘
2、查询 redo log中sql操作过的数据时需要先落盘
3、mysql 正常关闭时
Change Buffer 适用场景
1、更新后立刻需要读取该数据场景少。因为读取更新过的数据需要先落盘,那么 Change Buffer 存在的意义就没有了,同时还增加了redo log 写入的成本。
2、非唯一索引,如果使用的是唯一索引进行查询,那么操作的数据需要进行唯一性检查,所以需要将相应数据页先加载到缓冲池中,然后再判断,更新,过程中不会用到 Change Buffer。
写入redo log不也是磁盘数据IO么?为什么就比直接更新到磁盘上效率高?
使用 redo log 只是将操作存储进去,而更新到磁盘数据则是需要先读操作查找 B+ 树,找到数据后再进行写操作。
相关参数
Buffer Pool :
1、innodb_buffer_pool_size:缓冲池大小,在内存足够的条件下,越大越好。
2、innodb_old_blocks_pct:老年代占整个LRU链长度的比例,默认是37,即整个LRU的新生代和老年代长度比例是63:37。(如果配置是100就变成普通的LRU了)
3、innodb_old_blocks_time:老年代停留时间窗口,单位是毫秒,默认是1000,即同时满足“被访问”与“在老年代停留时间超过1秒”两个条件,才会被插入到新生代头部。
Change Buffer:
1、innodb_change_buffer_max_size:
配置写缓冲的大小,占整个缓冲池的比例,默认值是25%,最大值是50%。
画外音:写多读少的业务,才需要调大这个值,读多写少的业务,25%其实也多了。
2、innodb_change_buffering:
介绍:配置哪些写操作启用写缓冲,可以设置成all/none/inserts/deletes等。
参考文献:
https://blog.csdn.net/mashaokang1314/article/details/109716569
https://blog.csdn.net/fu_zhongyuan/article/details/90244503
https://www.cnblogs.com/geaozhang/p/7397699.html
https://www.cnblogs.com/virgosnail/p/10454150.html
InnoDB 中的缓冲池(Buffer Pool)的更多相关文章
- 【MySQL】InnoDB 内存管理机制 --- Buffer Pool
InnoDB Buffer Pool 是一块连续的内存,用来存储访问过的数据页面 innodb_buffer_pool_size 参数用来定义 innodb 的 buffer pool 的大小 是 M ...
- MySql 缓冲池(buffer pool) 和 写缓存(change buffer) 转
应用系统分层架构,为了加速数据访问,会把最常访问的数据,放在缓存(cache)里,避免每次都去访问数据库. 操作系统,会有缓冲池(buffer pool)机制,避免每次访问磁盘,以加速数据的访问. M ...
- 【大白话系统】MySQL 学习总结 之 缓冲池(Buffer Pool) 的设计原理和管理机制
一.缓冲池(Buffer Pool)的地位 在<MySQL 学习总结 之 InnoDB 存储引擎的架构设计>中,我们就讲到,缓冲池是 InnoDB 存储引擎中最重要的组件.因为为了提高 M ...
- 【大白话系统】MySQL 学习总结 之 缓冲池(Buffer Pool) 如何支撑高并发和动态调整
如果大家对我的 [大白话系列]MySQL 学习总结系列 感兴趣的话,可以点击关注一波. 一.上节回顾 在上节< 缓冲池(Buffer Pool) 的设计原理和管理机制>中,介绍了缓冲池整体 ...
- MySQL -- Innodb中的change buffer
change buffer是一种特殊的数据结构,当要修改的辅助索引页不在buffer pool中时,用来cache对辅助索引页的修改.对辅助索引页的操作可能是insert.update和delete操 ...
- mysql内核源代码深度解析 缓冲池 buffer pool 整体概述
http://blog.csdn.net/cjcl99/article/details/51063078
- innodb buffer pool小解
INNODB维护了一个缓存数据和索引信息到内存的存储区叫做buffer pool,他会将最近访问的数据缓存到缓冲区.通过配置各个buffer pool的参数,我们可以显著提高MySQL的性能. INN ...
- Innodb buffer pool/redo log_buffer 相关
InnoDB存储引擎是基于磁盘存储的,并将其中的记录按照页的方式进行管理.在数据库系统中,由于CPU速度和磁盘速度之前的鸿沟,通常使用缓冲池技术来提高数据库的整体性能. 1. Innodb_buffe ...
- 14.4.3.1 The InnoDB Buffer Pool
14.4.3.1 The InnoDB Buffer Pool 14.4.3.2 Configuring Multiple Buffer Pool Instances 14.4.3.3 Making ...
随机推荐
- Redis常用命令(3)——Hash
HDEL 格式:HDEL key field [field ...] 作用:删除哈希表中的一个或多个域. 返回值:删除的域的个数. HEXISTS 格式:HEXISTS key field 作用:判断 ...
- 关于DevOps的七大误解,99%的人都曾中过招!
[摘要] DevOps方法可以为组织带来显著的积极影响,降低成本.提高效率,使开发团队的工作更加精简.为了掌握这个过程的优势,有必要认识到DevOps是什么.不是什么.在本文中,就将讨论一些流传甚广的 ...
- glog修改
在写代码的过程中,打log肯定是少不了的,毕竟不能总靠调试来发现问题.log库的选用就很纠结了,成熟的log库非常多,log4cpp.log4cxx.poco.log.boost.log.glog等等 ...
- R语言factor类型转numeric
R 语言中为了进行数据分析,比如回归分析,这时候对于数据表格中的factor类型的数据会带来弊端,比如对因子的每一个数据都进行一次回归,这样就显得很复杂,且违背了我们的初衷,需要把factor转换为n ...
- SpringBoot的外部化配置最全解析!
目录 SpringBoot中的配置解析[Externalized Configuration] 本篇要点 一.SpringBoot官方文档对于外部化配置的介绍及作用顺序 二.各种外部化配置举例 1.随 ...
- C++ 有用的资源
C++ 有用的资源 以下资源包含了 C++ 有关的网站.书籍和文章.请使用它们来进一步学习 C++ 的知识. C++ 有用的网站 C++ Programming Language Tutorials ...
- string.contains()
public class test { public static void main(String[] args){ System.out.println("abcde".con ...
- gdb 符号表 &信息 &工具
查看二进制文件的编译器版本 strings info.o |grep GCCGCC: (crosstool-NG linaro-1.13.1-2012.02-20120222 - Linaro GC ...
- Mysql事物与二阶段提交
1.事务的四种特性(ACID) 事务可以是一个非常简单的SQL构成,也可以是一组复杂的SQL语句构成.事务是访问并且更新数据库中数据的一个单元,在事务中的操作,要么都修改,要么都不做修改,这就是事务 ...
- 我要进大厂之大数据Hadoop HDFS知识点(2)
01 我们一起学大数据 老刘继续分享出Hadoop中的HDFS模块的一些高级知识点,也算是对今天复习的HDFS内容进行一次总结,希望能够给想学大数据的同学一点帮助,也希望能够得到大佬们的批评和指点! ...