通过BulkLoad快速将海量数据导入到Hbase(TDH,kerberos认证)
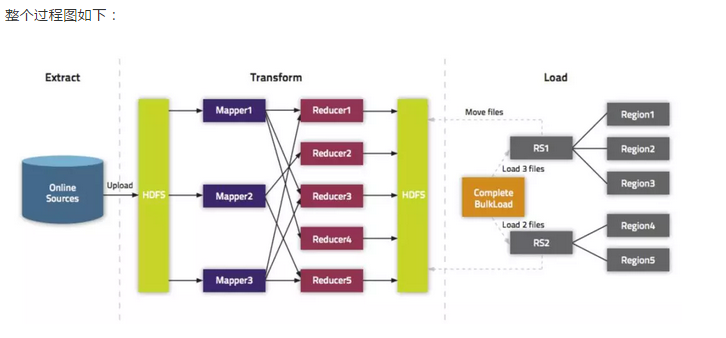
五、实践操作(kerberos认证)
1、创建表
create 'hfiletable','fm1','fm2'
2、数据准备

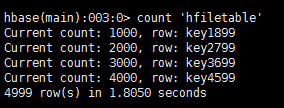
3、使用Mapreduce将数据通过Bulkload入到hbase表中
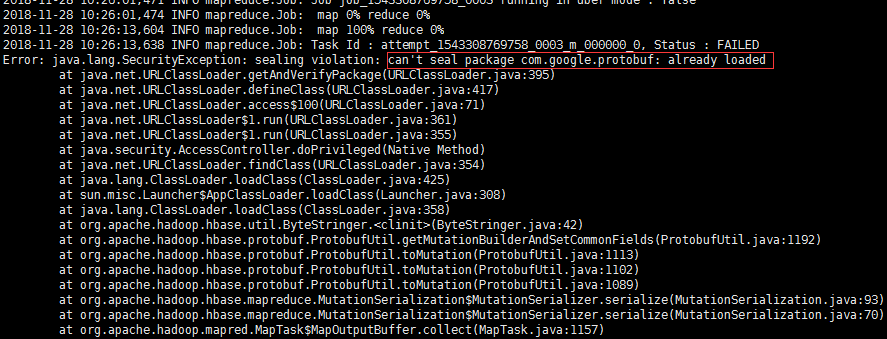
解决:protobuf-java-2.5.0.jar因为包冲突,由于我创建project时,结构为父模块和子模块,可能在导包的时候,被其他子模块的包给冲突了。因此,我新建了一个project重新打包到linux运行成功。

通过BulkLoad快速将海量数据导入到Hbase(TDH,kerberos认证)的更多相关文章
- 在Spark上通过BulkLoad快速将海量数据导入到Hbase
我们在<通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]>文中介绍了一种快速将海量数据导入Hbase的一种方法,而本文将介绍如何在Spark上使用Scala编写快速导入 ...
- 通过BulkLoad快速将海量数据导入到Hbase
在第一次建立Hbase表的时候,我们可能需要往里面一次性导入大量的初始化数据.我们很自然地想到将数据一条条插入到Hbase中,或者通过MR方式等. 但是这些方式不是慢就是在导入的过程的占用Region ...
- sqoop将关系型的数据库得数据导入到hbase中
1.sqoop将关系数据库导入到hbase的参数说明
- BulkLoad加载本地文件到HBase表
BulkLoad加载文件到HBase表 1.功能 将本地数据导入到HBase中 2.原理 BulkLoad会将tsv/csv格式的文件编程hfile文件,然后再进行数据的导入,这样可以避免大量数据导入 ...
- HBase(三): Azure HDInsigt HBase表数据导入本地HBase
目录: hdfs 命令操作本地 hbase Azure HDInsight HBase表数据导入本地 hbase hdfs命令操作本地hbase: 参见 HDP2.4安装(五):集群及组件安装 , ...
- HBase结合MapReduce批量导入(HDFS中的数据导入到HBase)
HBase结合MapReduce批量导入 package hbase; import java.text.SimpleDateFormat; import java.util.Date; import ...
- 干货 | 快速实现数据导入及简单DCS的实现
干货 | 快速实现数据导入及简单DCS的实现 原创: 赵琦 京东云开发者社区 4月18日 对于多数用户而言,在利用云计算的大数据服务时首先要面临的一个问题就是如何将已有存量数据快捷的导入到大数据仓库 ...
- 使用Spark的newAPIHadoopRDD接口访问有kerberos认证的hbase
使用newAPIHadoopRDD接口访问hbase数据,网上有很多可以参考的例子,但是由于环境使用了kerberos安全加固,spark使用有kerberos认证的hbase,网上的参考资料不多,访 ...
- zookeeper、hbase集成kerberos
1.KDC创建principal 1.1.创建认证用户 登陆到kdc服务器,使用root或者可以使用root权限的普通用户操作: # kadmin.local -q “addprinc -randke ...
随机推荐
- PyQt(Python+Qt)学习随笔:QAbstractScrollArea的sizeAdjustPolicy、horizontalScrollBarPolicy、verticalScrollB属性
老猿Python博文目录 老猿Python博客地址 Qt Designer中QAbstractScrollArea包括三个属性,分别是horizontalScrollBarPolicy.vertica ...
- burp-requests插件安装使用
这段时间都没更博客,扫描器的更新也暂时停止了,因为回了学校之后需要准备实验室招新和几个比赛的事情,内疚两秒钟,赶快学习! burp里面的插件很多,但是不要被纷繁复杂的功能迷了双眼,还是那句话:适合自己 ...
- 【Alpha冲刺阶段】Scrum Meeting Daily1
1.会议简述 会议开展时间 2020/5/22 8:30-9:00 PM 会议基本内容摘要 讨论了基础的分工,以及明确了各自模块需要完成的任务 参与讨论人员 全体参与 特别说明 会议需要每天都开展!! ...
- 手把手教你写DI_3_小白徒手支持 `Singleton` 和 `Scoped` 生命周期
手把手教你写DI_3_小白徒手支持 Singleton 和 Scoped 生命周期 在上一节:手把手教你写DI_2_小白徒手撸构造函数注入 浑身绷带的小白同学:我们继续开展我们的工作,大家都知道 Si ...
- redis学习之——在分布式数据库中CAP原理CAP+BASE
分布式系统 分布式系统(distributed system) 由多台计算机和通信的软件组件通过计算机网络连接(本地网络或广域网)组成.分布式系统是建立在网络之上的软件系统.正是因为软件的特性,所以分 ...
- 服务器ganglia安装(带有登录验证)
1.ganglia组件gmond相当于agent端,主要手机各node的性能状态:gmetad相当于server端,从gmond以poll的方式收集和存储原数据:ganglia-web相当于一个web ...
- EasyX 简易绘图工具接口整理
EasyX Library for C++ (Ver:20190415(beta)) http://www.easyx.cn EasyX.h 1 #pragma once 2 3 #ifndef ...
- 云小课 | 需求任务还未分解,该咋整!项目管理Scrum项目工作分解的心酸谁能知?
温馨提醒:本文约3000字,需要阅读5分钟,共分为8个部分,建议分段阅读! 软件开发过程中,从产品概念形成到产品规划.往往要做详细的需求分析和项目规划等,因此,选对一款项目管理工具对开发者就显得尤为重 ...
- Redis安装教程及安装报错解决方案(大佬勿喷)
安装环境:CentOS7 Redis版本:redis-6.0.9.tar.gz 依次按照以下顺序执行: 1. [root@localhost ~]# wget https://download.red ...
- Java 方法内联
什么是Java 方法内联? 我们先来看看普遍的内联函数含义.在维基百科中解释为: 内联函数:在计算机科学中,内联函数(有时称作在线函数或编译时期展开函数)是一种编程语言结构,用来建议编译器对一些特殊函 ...