spark提交至yarn的的动态资源分配
1、为什么开启动态资源分配
⽤户提交Spark应⽤到Yarn上时,可以通过spark-submit的num-executors参数显示地指定executor 个数,随后,ApplicationMaster会为这些executor申请资源,每个executor作为⼀个Container在 Yarn上运⾏。Spark调度器会把Task按照合适的策略分配到executor上执⾏。所有任务执⾏完后, executor被杀死,应⽤结束。在job运⾏的过程中,⽆论executor是否领取到任务,都会⼀直占有着 资源不释放。很显然,这在任务量⼩且显示指定⼤量executor的情况下会很容易造成资源浪费
2.yarn-site.xml加入配置,并重启yarn服务
spark版本:2.2.1,hadoop版本:cdh5.14.2-2.6.0,不是clouder集成的cdh是手动单独搭建的
vim etc/hadoop/yarn-site.xml <property>
<name>yarn.nodemanager.aux-services</name>
<value>spark_shuffle,mapreduce_shuffle</value>
</property> <property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
重启yarn时的需要注意的异常:nodemanager没有正常启动,yarn的8080页面的core与memory都为空
Caused by: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.spark.network.yarn.YarnShuffleService not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2349)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2373)
... 10 more
Caused by: java.lang.ClassNotFoundException: Class org.apache.spark.network.yarn.YarnShuffleService not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:2255)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2347)
... 11 more
2020-02-17 19:54:59,185 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Stopping NodeManager metrics system...
2020-02-17 19:54:59,185 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: NodeManager metrics system stopped.
2020-02-17 19:54:59,185 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: NodeManager metrics system shutdown complete.
2020-02-17 19:54:59,185 FATAL org.apache.hadoop.yarn.server.nodemanager.NodeManager: Error starting NodeManager
java.lang.RuntimeException: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.spark.network.yarn.YarnShuffleService not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2381)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.AuxServices.serviceInit(AuxServices.java:121)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:163)
at org.apache.hadoop.service.CompositeService.serviceInit(CompositeService.java:107)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.ContainerManagerImpl.serviceInit(ContainerManagerImpl.java:236)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:163)
at org.apache.hadoop.service.CompositeService.serviceInit(CompositeService.java:107)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.serviceInit(NodeManager.java:318)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:163)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.initAndStartNodeManager(NodeManager.java:562)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.main(NodeManager.java:609)
Caused by: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.spark.network.yarn.YarnShuffleService not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2349)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2373)
... 10 more
Caused by: java.lang.ClassNotFoundException: Class org.apache.spark.network.yarn.YarnShuffleService not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:2255)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2347)
... 11 more
2020-02-17 19:54:59,189 INFO org.apache.hadoop.yarn.server.nodemanager.NodeManager: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NodeManager at bigdata.server1/192.168.121.12
************************************************************/
原因是缺少了:sparkShuffle的jar包
mv spark/yarn/spark-2.11-2.2.1-shuffle_.jar /opt/modules/hadoop-2.6.0-cdh5.14.2/share/hadoop/yarn/
nodemanager依然启动不了,查询nodemanger.log日志、继续报错:
java.lang.NoSuchMethodError: org.spark_project.com.fasterxml.jackson.core.JsonFactory.requiresPropertyOrdering()Z
添加了jackson的包没啥用,网上有一样的报错方式:https://www.oschina.net/question/3721355_2269200
结果:未解决
3.spark的动态资源分配开启
spark.shuffle.service.enabled true //启⽤External shuffle Service服务
spark.shuffle.service.port 7337 //Shuffle Service服务端⼝,必须和yarn-site中的⼀致
spark.dynamicAllocation.enabled true //开启动态资源分配
spark.dynamicAllocation.minExecutors 1 //每个Application最⼩分配的executor数
spark.dynamicAllocation.maxExecutors 30 //每个Application最⼤并发分配的executor数
spark.dynamicAllocation.schedulerBacklogTimeout 1s
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout 5s
也可以在代码或者脚本中添加sparkconf
4.hadoop版本cdh5.14.2-2.6.0与spark 2.2.1单独搭建的会报错
5.使用clouderCDH 5.14.0 的版本测试
1.在yarn-site.xml添加上面的配置
1
2.普通提交,spark2版本进行shell提交,观察yarn
spark2-shell --master yarn-client \
--executor-memory 2G \
--num-executors 10
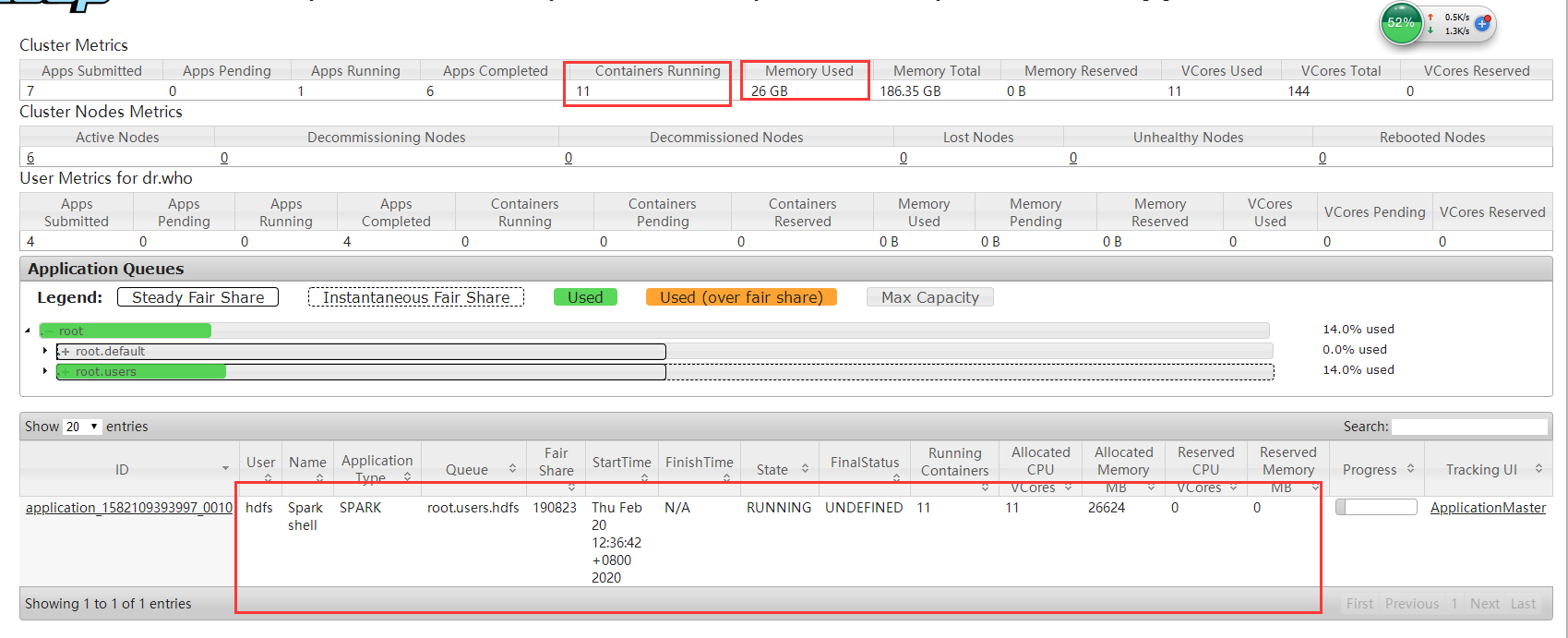
可以看到10个executor(driver占一核)没有任务也是申请到资源,占着不用,造成了资源浪费
3.使用spark的动态资源分配提交
spark2-shell —master yarn —eploy-mode client \
//指定队列
—queue "test" \
//日志配置
—conf spark.driver.extraJava0ptions=-Dlog4j.configuration=log4j-yarn.properties \
—conf spark.executor.extraJava0ptions=-Dlog4j.configuration=log4j-yarn.properties \
—conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
//推测执行等待时间
—conf spark.locality.wait=10 \
//最大失败重试次数
—conf spark.task.maxFailures=8 \
—conf spark.ui.killEnabled=false \
—conf spark.logConf=true \
//非堆内存配置
—conf spa rk.yarn.d river.memoryOverhead=512 \
—conf spark.yarn.executor.memoryOverhead=1024 \
—conf spark.yarn.maxAppAttempts=4 \
—conf spark.yarn.am.attemptFailuresValidityInterval=lh \
—conf spark.yarn.executor.failuresValidityInterval=lh \
//动态资源开启
—conf spark.dynamicAllocation.enabled=true \
//最大最小申请的Executors数
—conf spark.dynamicAllocation.minExecutors=l \
—conf spark.dynamicAllocation.maxExecutors=30 \
—conf spark.dynamicAllocation.executorldleTimeout=3s \
—conf spark.shuffle.service.enabled=true
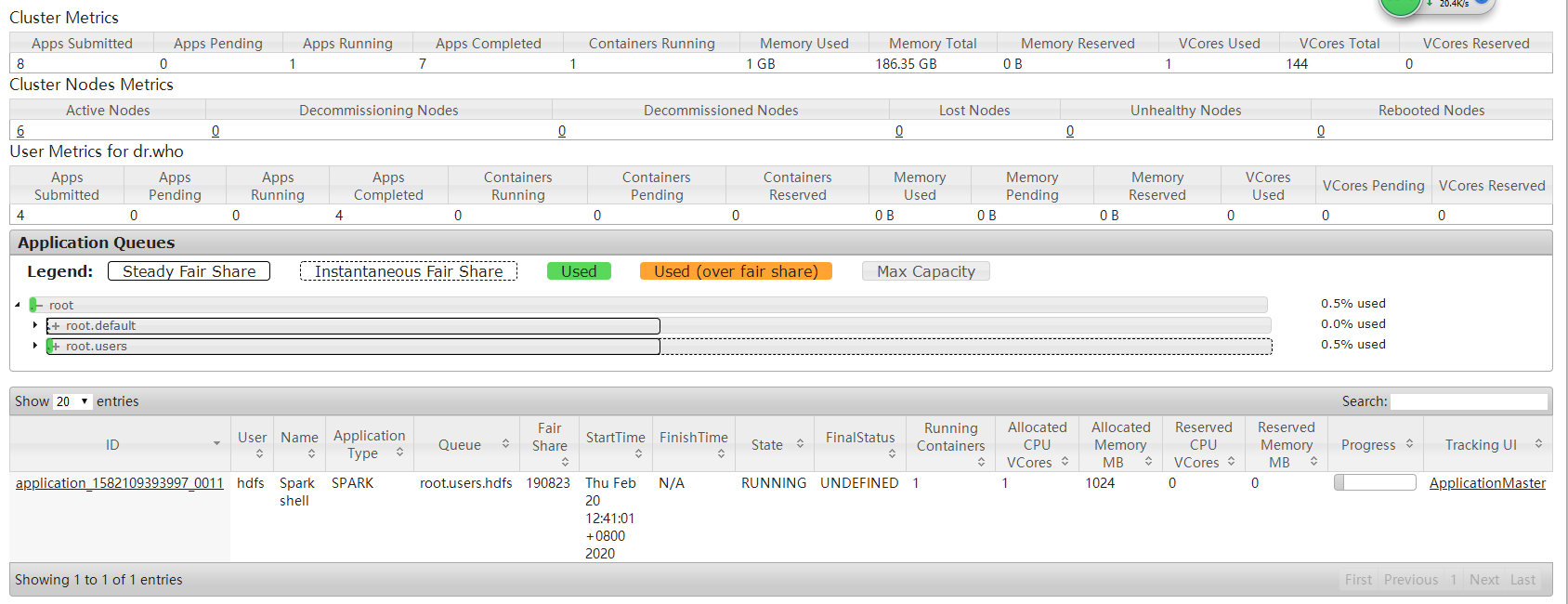
可以看到申请的只有1个executor(driver端的),暂时没有提交任务,最小申请为1个,
sc.textFile("file:///etc/hosts").flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_ + _).count()
提交一个wrodcount程序跑一下,发现使用2个executor(1个driver),说明这种数量级的数据就2个就可以满足了,不需要开启更多的资源去空转,占用


4.动态资源的好处
1.多个部门去使用集群资源,有运行的任务时候申请资源,没有时将资源回收给yarn,供其他人使用
2.防止小数据申请大资源,造成资源浪费,executor空转
3.在进行流式处理时不建议开启,流式处理的数据量在不同时段是不同的,需要最大利用资源,从而提高消费速度,以免造成数据堆积,流式处理时如果一直去判断数据量的大小进行动态申请时,创建与销毁资源也需要时间,从而让流式处理造成了延迟
spark提交至yarn的的动态资源分配的更多相关文章
- spark on yarn 动态资源分配报错的解决:org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:spark_shuffle does not exist
组件:cdh5.14.0 spark是自己编译的spark2.1.0-cdh5.14.0 第一步:确认spark-defaults.conf中添加了如下配置: spark.shuffle.servic ...
- spark任务提交到yarn上命令总结
spark任务提交到yarn上命令总结 1. 使用spark-submit提交任务 集群模式执行 SparkPi 任务,指定资源使用,指定eventLog目录 spark-submit --class ...
- Spark动态资源分配-Dynamic Resource Allocation
微信搜索lxw1234bigdata | 邀请体验:数阅–数据管理.OLAP分析与可视化平台 | 赞助作者:赞助作者 Spark动态资源分配-Dynamic Resource Allocation S ...
- 利用动态资源分配优化Spark应用资源利用率
背景 在某地市开展项目的时候,发现数据采集,数据探索,预处理,数据统计,训练预测都需要很多资源,现场资源不够用. 目前该项目的资源3台旧的服务器,每台的资源 内存为128G,cores 为24 (co ...
- 记一次有关spark动态资源分配和消息总线的爬坑经历
问题: 线上的spark thriftserver运行一段时间以后,ui的executor页面上显示大量的active task,但是从job页面看,并没有任务在跑.此外,由于在yarn mode下, ...
- Spark如何进行动态资源分配
一.操作场景 对于Spark应用来说,资源是影响Spark应用执行效率的一个重要因素.当一个长期运行的服务,若分配给它多个Executor,可是却没有任何任务分配给它,而此时有其他的应用却资源紧张,这 ...
- 「Spark从精通到重新入门(二)」Spark中不可不知的动态资源分配
前言 资源是影响 Spark 应用执行效率的一个重要因素.Spark 应用中真正执行 task 的组件是 Executor,可以通过spark.executor.instances 指定 Spark ...
- Spark作业提交至Yarn上执行的 一个异常
(1)控制台Yarn(Cluster模式)打印的异常日志: client token: N/A diagnostics: Application application_1584359 ...
- Idea里面远程提交spark任务到yarn集群
Idea里面远程提交spark任务到yarn集群 1.本地idea远程提交到yarn集群 2.运行过程中可能会遇到的问题 2.1首先需要把yarn-site.xml,core-site.xml,hdf ...
随机推荐
- 第14.10节 Python中使用BeautifulSoup解析http报文:html标签相关属性的访问
一. 引言 在<第14.8节 Python中使用BeautifulSoup加载HTML报文>中介绍使用BeautifulSoup的安装.导入和创建对象的过程,本节介绍导入后利用Beauti ...
- 【面试题】在浏览器中输入URL后,执行的全部过程。会用到哪些协议?(一次完整的HTTP请求过程)
整个流程如下: 域名解析 为了将消息从你的PC上传到服务器上,需要用到IP协议.ARP协议和OSPF协议. 发起TCP的三次握手 建立TCP连接后发起HTTP请求 服务器响应HTTP请求 浏览器解析h ...
- mysql 列转行 动态写法
-- 列转行动态sql -- 测试表DROP TABLE IF EXISTS `tb_score`; CREATE TABLE `tb_score` ( `id` int(11) NOT NULL A ...
- 颜色直方图(Color Histogram)
数字成像中的颜色直方图是对给定图像中具有相同颜色的像素的频率进行计算的一种方法.这种方法通常被转换成一个图形,以帮助分析和调整图像中的平衡.几乎所有的照片编辑软件和大量的数码相机都具有颜色直方图的查看 ...
- windows 远程连接报错
在windows7上或者windows10上远程连接服务器报错("连接错误"),试了网上的方法,发现是服务器安装ssl证书关闭了ssh服务,开启ssh服务后,重启电脑就可以解决这个 ...
- 从0到1实战移动Web App开发
从0到1实战移动Web App开发 教程介绍 从0到1 实战webapp,通过热门的web前端技术实现移动端app应用,先基础.后实战,在讲解的同时引导思考,会抛出自己独特的观点,一行一行写代码讲 ...
- 从零到一快速搭建个人博客网站(域名备案 + https免费证书)(一)
环境介绍 资源 说明 centos v7.2 docker 快速部署项目环境 nginx 反向代理,同时配置https证书 halo v1.4.2,开源博客项目 Let's Encrypt 免费证书 ...
- Typora + 七牛云图床快速配置,告别手动上传图片!
大家好,我是zeroing,本文将介绍关于 Typora 软件如何配置七牛云图床,实现图片即插即用,可以先看一下最终效果! 可以看到图片借助 Typora 软件自动将本地存储转化为第三方图片网络链接 ...
- SQL学习(三) 复杂查询
我们本节考察的数据库如下所示: 3.1 创建出满足下述三个条件的视图(视图名称为 ViewPractice5_1).使用 product(商品)表作为参照表,假设表中包含初始状态的 8 行数据. 条件 ...
- 【程序包管理】Linux程序包管理之rpm安装总结
rpm简介 rpm( Red Hat Package Manager )是一个开放的软件包管理系统.它工作于Red Hat Linux及其他Linux系统,成为Linux中公认的软件包管理标准. rp ...