KUDU 学习笔记
Kudu
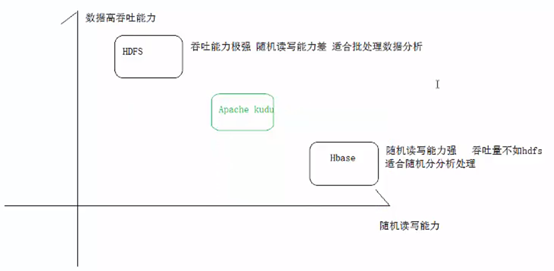
现存系统针对结构化数据存储与查询的一些痛点问题,结构化数据的存储,通常包含如下两种方式:
- 静态数据通常以Parquet/Carbon/Avro形式直接存放在HDFS中,吞吐能力大,适合离线分析,随机读写能力差,难以支持单条记录级别的更新。
- 可变数据的存储通常选择面向列族的HBase或者Cassandra,高效随机读写,吞吐能力小,不适合离线分析场景。
Kudu的设计是结合了Hbase的高效随机读写和HDFS高吞吐能力一种折中处理,既能支持OLTP型实时读写能力又能支持OLAP型分析。另外一个初衷Kudu作为一个新的分布式存储系统期望有效提升CPU的使用率,而低CPU使用率恰是HBase/Cassandra等系统的最大问题。
Kudu架构
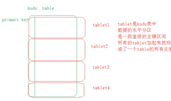
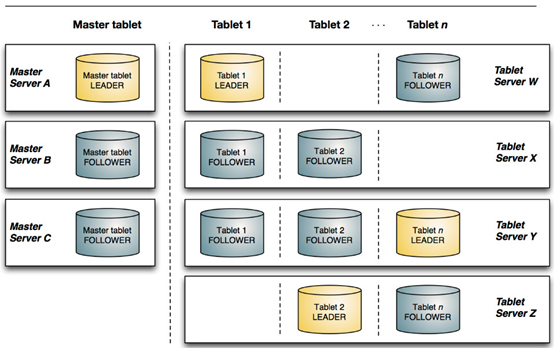
Kudu采用了Master-Slave主从架构,一个table表会按照主键进行hash/或者range(分区)划分出多个小的tablet(相当于Hbase里的Region),每个小的tablet会对应多个副本(其中1个Leader tablet用于读写,其他的副本为Follower tablet用于只读),这个小的tablet会分到各个Tablet Server 中,这些tablet相关信息存储在Master Server中(1个Leader多个Follower)。
Master Server
1用来存放一些表的Schema信息,且负责处理建表等请求,管理元数据(元数据存储在只有一个tablet的Catalog table中),即tablet与表的基本信息。
2. 跟踪管理集群中的所有的Tablet Server,并且在Tablet Server异常之后协调数据的重部署。
3. 存放Tablet到Tablet Server的部署信息。
其中Catalog Table元数据表,用来存储table(schema、locations、states)与tablet(现有的tablet列表,每个tablet及其副本所处Tablet Server,tablet当前状态以及开始和结束键)的信息。
Tablet Server
存储tablet和为tablet向client提供服务。对于给定的tablet,一个Tablet Server充当leader,其他Tablet Server充当该tablet的follower副本。只有leader服务写请求,leader与follower为每个服务提供读请求。
Tablet与HBase中的Region大致相似,但存在如下一些明显的区别点:
分区策略不一样
Tablet包含两种分区策略,一种是基于Hash Partition方式,在这种分区方式下用户数据可较均匀的分布在各个Tablet中,但原来的数据排序特点已被打乱。另外一种是基于Range Partition(分区)方式,数据将按照用户数据指定的有序的分区键的组合String的顺序进行分区。而HBase中仅仅提供了一种按用户数据RowKey的Range Partition方式。
多副本机制不一样
一个Tablet可以被部署到了多个Tablet Server中,由自己系统管理,不依赖HDFS。在HBase最初的架构中,一个Region只能被部署在一个RegionServer中,它的数据多副本交由HDFS来保障。
数据文件存储结构
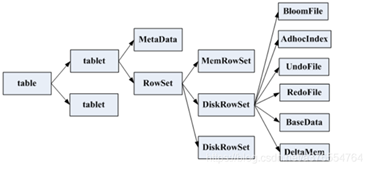
具体结构如下
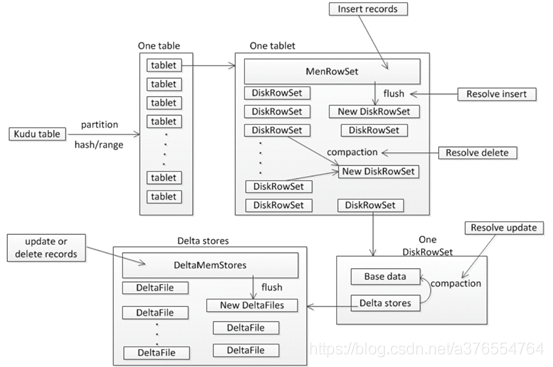
数据的读写更操作
不管数据的读写,还是更新操作,其大致都需要先查找我们要的数据的主键所对应的位置,比如下面的写操作
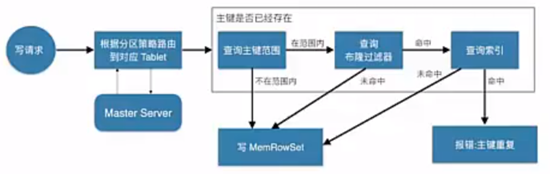
写流程
Client首先连接Master,获取元数据信息。然后连接Tablet Server,查找MemRowSet与DeltMemStore中是否存在相同primary key,如果存在,则报错;如果不存在,则将待插入的数据写入WAL日志,然后将数据写入MemRowSet。

1、client向Master请求预写表的元数据信息
2、Master会进行一定的校验,表是否存在,字段是否存在等
3、如果Master校验通过,则返回表的分区、tablet与其对应的Tablet Server给client;如果校验失败则报错给client。
4、client根据Master返回的元数据信息,将请求发送给tablet对应的Tablet Server.
5、Tablet Server首先会查询内存中MemRowSet与DeltMemStore中是否存在与待插入数据主键相同的数据,如果存在则报错。
6、Tablet Server会讲写请求预写到WAL日志,用来server宕机后的恢复操作
7、将数据写入内存中的MemRowSet中,一旦MemRowSet的大小达到1G或120s后,MemRowSet会flush成一个或DiskRowSet,用来将数据持久化
8、返回client数据处理完毕
更新流程
Client首先向Master请求元数据,然后根据元数据提供的tablet信息,连接Tablet Server,根据数据所处位置的不同,有不同的操作:在内存MemRowSet中的数据,会将更新信息写入数据所在行的mutation链表中;在磁盘中的数据,会将更新信息写入DeltMemStore中。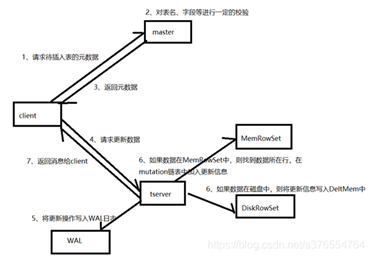
1、client向Master请求预更新表的元数据,首先Master会校验表是否存在,字段是否存在,如果校验通过则会返回给client表的分区、tablet、tablet所在Tablet Server信息
2、client向Tablet Server发起更新请求
3、将更新操作预写如WAL日志,用来在server宕机后的数据恢复
4、根据Tablet Server中待更新的数据所处位置的不同,有不同的处理方式:
如果数据在内存中,则从MemRowSet中找到数据所处的行,然后在改行的mutation链表中写入更新信息,在MemRowSet flush的时候,将更新合并到baseData中
如果数据在DiskRowSet中,则将更新信息写入DeltMemStore中,DeltMemStore达到一定大小后会flush成DeltFile。
5、更新完毕后返回消息给client。
读流程
客户端将要读取的数据信息发送给Master,Master对其进行一定的校验,比如表是否存在,字段是否存在。Master返回元数据信息给client,然后client与Tablet Server建立连接,通过metaData找到数据所在的RowSet,首先加载内存里面的数据(MemRowSet与DeltMemStore),然后加载磁盘里面的数据,最后返回最终数据给client.
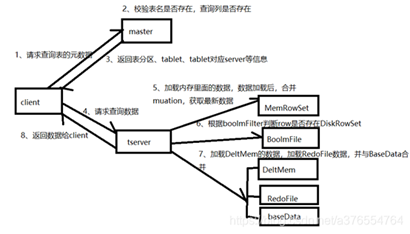
1、客户端Master请求查询表指定数据
2、Master对请求进行校验,校验表是否存在,schema中是否存在指定查询的字段,主键是否存在
3、Master通过查询Catalog Table返回表,将tablet对应的Tablet Server信息、Tablet Server状态等元数据信息返回给client
4、client与Tablet Server建立连接,通过metaData找到primary key对应的RowSet。
5、首先加载RowSet内存中MemRowSet与DeltMemStore中的数据
6、然后加载磁盘中的数据,也就是DiskRowSet中的BaseData与DeltFile中的数据
7、返回数据给Client
8、继续4-7步骤,直到拿到所有数据返回给client
参考
https://blog.csdn.net/nosqlnotes/article/details/79496002
https://blog.csdn.net/a376554764/article/details/89445319
KUDU 学习笔记的更多相关文章
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- PHP-自定义模板-学习笔记
1. 开始 这几天,看了李炎恢老师的<PHP第二季度视频>中的“章节7:创建TPL自定义模板”,做一个学习笔记,通过绘制架构图.UML类图和思维导图,来对加深理解. 2. 整体架构图 ...
- PHP-会员登录与注册例子解析-学习笔记
1.开始 最近开始学习李炎恢老师的<PHP第二季度视频>中的“章节5:使用OOP注册会员”,做一个学习笔记,通过绘制基本页面流程和UML类图,来对加深理解. 2.基本页面流程 3.通过UM ...
- 2014年暑假c#学习笔记目录
2014年暑假c#学习笔记 一.C#编程基础 1. c#编程基础之枚举 2. c#编程基础之函数可变参数 3. c#编程基础之字符串基础 4. c#编程基础之字符串函数 5.c#编程基础之ref.ou ...
- JAVA GUI编程学习笔记目录
2014年暑假JAVA GUI编程学习笔记目录 1.JAVA之GUI编程概述 2.JAVA之GUI编程布局 3.JAVA之GUI编程Frame窗口 4.JAVA之GUI编程事件监听机制 5.JAVA之 ...
- seaJs学习笔记2 – seaJs组建库的使用
原文地址:seaJs学习笔记2 – seaJs组建库的使用 我觉得学习新东西并不是会使用它就够了的,会使用仅仅代表你看懂了,理解了,二不代表你深入了,彻悟了它的精髓. 所以不断的学习将是源源不断. 最 ...
- CSS学习笔记
CSS学习笔记 2016年12月15日整理 CSS基础 Chapter1 在console输入escape("宋体") ENTER 就会出现unicode编码 显示"%u ...
- HTML学习笔记
HTML学习笔记 2016年12月15日整理 Chapter1 URL(scheme://host.domain:port/path/filename) scheme: 定义因特网服务的类型,常见的为 ...
- DirectX Graphics Infrastructure(DXGI):最佳范例 学习笔记
今天要学习的这篇文章写的算是比较早的了,大概在DX11时代就写好了,当时龙书11版看得很潦草,并没有注意这篇文章,现在看12,觉得是跳不过去的一篇文章,地址如下: https://msdn.micro ...
随机推荐
- 解放双手!用 Python 控制你的鼠标和键盘
在工作中难免遇到需要在电脑上做一些重复的点击或者提交表单等操作,如果能通过 Python 预先写好相关的操作指令,让它帮你操作,然后你自己去刷网页打游戏,岂不是很爽?] 很多人学习python,不知道 ...
- 朴素贝叶斯分类器基本代码 && n折交叉优化
自己也是刚刚入门.. 没脸把自己的代码放上去,先用别人的. 加上自己的解析,挺全面的,希望有用. import re import pandas as pd import numpy as np fr ...
- Spring Cloud 之 基础学习资料
通过调研发现,官方及国内基础学习资料已经比较完善,故不再重复赘述,安静地做个搬运工. 如工作中遇到比较复杂或重要的点,再做详述. 官方 Spring 官方入门系列 服务注册与发现 Service Re ...
- docker镜像,容器的操作和应用
镜像操作 拉取镜像 从中央仓库拉取到本地 docker pull 镜像名称[:tag] #举个例子 :docker pull daocloud.io/libarary/tomcat:8.5.-jre8 ...
- 将vscode打造成强大的C/C++ IDE
一.安装 你可以直接从微软官网下载,如果你想要一个纯净的vscode(微软官方的有一项商标.一个插件库.一个 C# 调试器以及遥测),可以手动编译https://github.com/microsof ...
- Java—增强for循环与for循环的区别/泛型通配符/LinkedList集合
增强for循环 增强for循环是JDK1.5以后出来的一个高级for循环,专门用来遍历数组和集合的. 它的内部原理其实是个Iterator迭代器,所以在遍历的过程中,不能对集合中的元素进行增删操作. ...
- java 异常一
一 异常的继承体系 在Java中使用Exception类来描述异常. 查看API中Exception的描述,Exception 类及其子类是 Throwable 的一种形式,它用来表示java程序中 ...
- 2020-03-26:eureka 和其他注册中心比如zk有什么不同?
从eureka工作原理可以看出,eureka client有缓存功能,即使eureka所有的serve都宕掉,仍然能给服务消费者发送服务信息,所以eureka保证了服务可用性,不能保证数据一致性,是一 ...
- CSS动画基础知识
CSS动画就是通过CSS (Cascading Style Sheet,层叠样式表)代码搭建的网页动画.它允许设计师和开发人员通过编辑网站的CSS代码来添加页面动画,从而轻松取代传统动画图片或flas ...
- Azure Application Gateway(二)对后端 VM 进行负载均衡
一,引言 上一节有讲到使用 Azure Application Gateway 为我们后端类型为 Web App 的 Demo 项目提供负载均衡,Azure Application Gateway 的 ...