适用初学者的5种Python数据输入技术
摘要:数据是数据科学家的基础,因此了解许多加载数据进行分析的方法至关重要。在这里,我们将介绍五种Python数据输入技术,并提供代码示例供您参考。
数据是数据科学家的基础,因此了解许多加载数据进行分析的方法至关重要。在这里,我们将介绍五种Python数据输入技术,并提供代码示例供您参考。
作为初学者,您可能只知道一种使用p andas.read_csv函数读取数据的方式(通常以CSV格式)。它是最成熟,功能最强大的功能之一,但其他方法很有帮助,有时肯定会派上用场。
我要讨论的方法是:
- Manual 函数
- loadtxt 函数
- genfromtxtf 函数
- read_csv 函数
- Pickle
我们将用于加载数据的数据集可以在此处找到 。它被称为100-Sales-Records。
Imports
我们将使用Numpy,Pandas和Pickle软件包,因此将其导入。

1. Manual Function
这是最困难的,因为您必须设计一个自定义函数,该函数可以为您加载数据。您必须处理Python的常规归档概念,并使用它来读取 .csv 文件。
让我们在100个销售记录文件上执行此操作。

嗯,这是什么????似乎有点复杂的代码!!!让我们逐步打破它,以便您了解正在发生的事情,并且可以应用类似的逻辑来读取 自己的 .csv文件。
在这里,我创建了一个 load_csv 函数,该函数将要读取的文件的路径作为参数。
我有一个名为data 的列表, 它将具有我的CSV文件数据,而另一个列表 col 将具有我的列名。现在,在手动检查了csv之后,我知道列名在第一行中,因此在我的第一次迭代中,我必须将第一行的数据存储在 col中, 并将其余行存储在 data中。
为了检查第一次迭代,我使用了一个名为checkcol 的布尔变量, 它为False,并且在第一次迭代中为false时,它将第一行的数据存储在 col中 ,然后将checkcol 设置 为True,因此我们将处理 数据列表并将其余值存储在 数据列表中。
逻辑
这里的主要逻辑是,我使用readlines() Python中的函数在文件中进行了迭代 。此函数返回一个列表,其中包含文件中的所有行。
当阅读标题时,它会将新行检测为 \ n 字符,即行终止字符,因此为了删除它,我使用了 str.replace 函数。
由于这是一个 的.csv 文件,所以我必须要根据不同的东西 逗号 ,所以我会各执一个字符串, 用 string.split(“”) 。对于第一次迭代,我将存储第一行,其中包含列名的列表称为 col。然后,我会将所有数据附加到名为data的列表中 。
为了更漂亮地读取数据,我将其作为数据框格式返回,因为与numpy数组或python的列表相比,读取数据框更容易。
输出量
利弊
重要的好处是您具有文件结构的所有灵活性和控制权,并且可以以任何想要的格式和方式读取和存储它。
您也可以使用自己的逻辑读取不具有标准结构的文件。
它的重要缺点是,特别是对于标准类型的文件,编写起来很复杂,因为它们很容易读取。您必须对需要反复试验的逻辑进行硬编码。
仅当文件不是标准格式或想要灵活性并且以库无法提供的方式读取文件时,才应使用它。
2. Numpy.loadtxt函数
这是Python中著名的数字库Numpy中的内置函数。加载数据是一个非常简单的功能。这对于读取相同数据类型的数据非常有用。
当数据更复杂时,使用此功能很难读取,但是当文件简单时,此功能确实非常强大。
要获取单一类型的数据,可以下载 此处 虚拟数据集。让我们跳到代码。
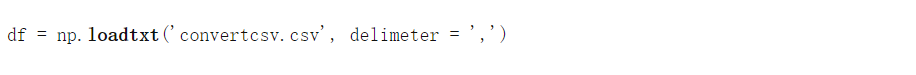
这里,我们简单地使用了在传入的定界符中 作为 ','的 loadtxt 函数 , 因为这是一个CSV文件。
现在,如果我们打印 df,我们将看到可以使用的相当不错的numpy数组中的数据。

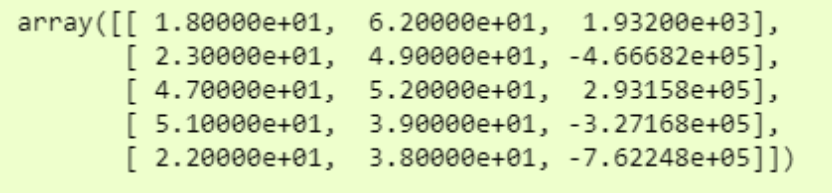
由于数据量很大,我们仅打印了前5行。
利弊
使用此功能的一个重要方面是您可以将文件中的数据快速加载到numpy数组中。
缺点是您不能有其他数据类型或数据中缺少行。
3. Numpy.genfromtxt()
我们将使用数据集,即第一个示例中使用的数据集“ 100 Sales Records.csv”,以证明其中可以包含多种数据类型。
让我们跳到代码。

为了更清楚地看到它,我们可以以数据框格式看到它,即
这是什么?哦,它已跳过所有具有字符串数据类型的列。怎么处理呢?
只需添加另一个 dtype 参数并将dtype 设置 为None即可,这意味着它必须照顾每一列本身的数据类型。不将整个数据转换为单个dtype。

然后输出

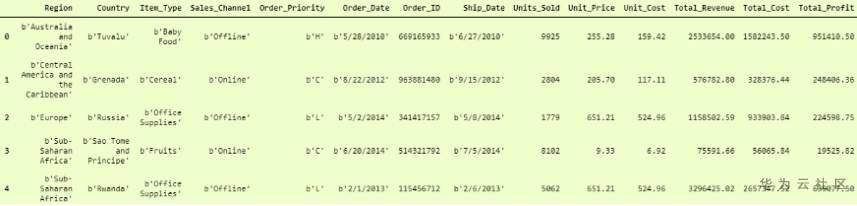
比第一个要好得多,但是这里的“列”标题是“行”,要使其成为列标题,我们必须添加另一个参数,即 名称 ,并将其设置为 True, 这样它将第一行作为“列标题”。
即

我们可以将其打印为

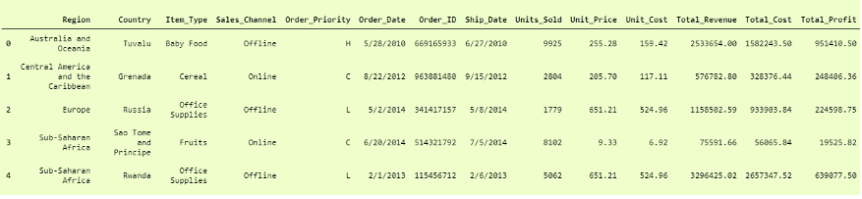
4. Pandas.read_csv()
Pandas是一个非常流行的数据操作库,它非常常用。read_csv()是非常重要且成熟的 功能 之一,它 可以非常轻松地读取任何 .csv 文件并帮助我们进行操作。让我们在100个销售记录的数据集上进行操作。
此功能易于使用,因此非常受欢迎。您可以将其与我们之前的代码进行比较,然后进行检查。

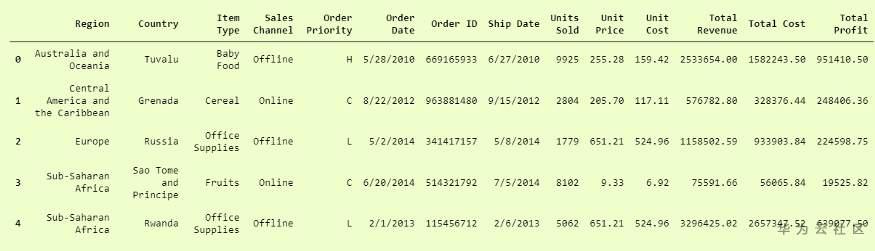
你猜怎么着?我们完了。这实际上是如此简单和易于使用。Pandas.read_csv肯定提供了许多其他参数来调整我们的数据集,例如在我们的 convertcsv.csv 文件中,我们没有列名,因此我们可以将其读取为
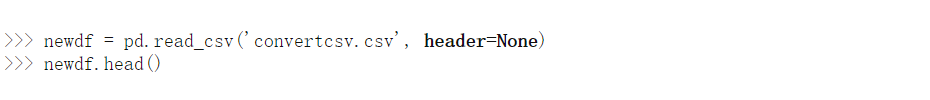
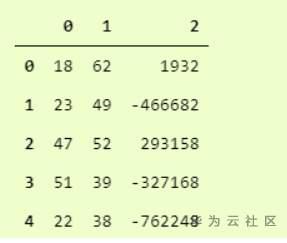
我们可以看到它已经读取了没有标题的 csv 文件。您可以在此处查看官方文档中的所有其他参数 。
5. Pickle
如果您的数据不是人类可以理解的良好格式,则可以使用pickle将其保存为二进制格式。然后,您可以使用pickle库轻松地重新加载它。
我们将获取100个销售记录的CSV文件,并首先将其保存为pickle格式,以便我们可以读取它。

这将创建一个新文件 test.pkl ,其中包含来自 Pandas 标题的 pdDf 。
现在使用pickle打开它,我们只需要使用 pickle.load 函数。

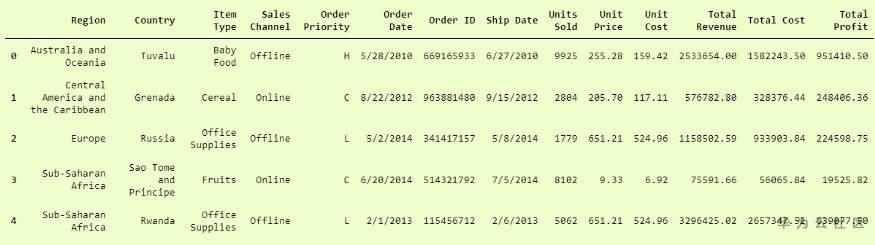
在这里,我们已成功从pandas.DataFrame 格式的pickle文件中加载了数据 。
本文分享自华为云社区《Python加载数据的5种不同方式》,原文作者:一只无脑程序员
适用初学者的5种Python数据输入技术的更多相关文章
- Python学习教程(learning Python)--1.3 Python数据输入
多数应用程序都有数据输入语句,用于读入数据,和用户进行交互,在Python语言里,可以通过raw_input函数实现数据的从键盘读入数据操作. 基本语法结构:raw_input(prompt) 通常p ...
- Python数据可视化的四种简易方法
摘要: 本文讲述了热图.二维密度图.蜘蛛图.树形图这四种Python数据可视化方法. 数据可视化是任何数据科学或机器学习项目的一个重要组成部分.人们常常会从探索数据分析(EDA)开始,来深入了解数据, ...
- 设计一种前端数据延迟加载的jQuery插件(2)
背景 最近看到很多网站都运用到了一种前端数据延迟加载技术,包括淘宝,新浪网等等,这样做的目的可以使得一些未显示的图片随 着滚动条的滚动进行延迟显示. 好处显而易见,可以减少前端对于图片的Http请求, ...
- Python中输入和输出(打印)数据
一个程序要进行交互,就需要进行输入,进行输入→处理→输出的过程.所以就需要用到输入和输出功能.同样的,在Python中,怎么实现输入和输出? Python3中的输入方式: Python提供了 inpu ...
- 15种Python片段去优化你的数据科学管道
来源:15 Python Snippets to Optimize your Data Science Pipeline 翻译:RankFan 15种Python片段去优化你的数据科学管道 为什么片段 ...
- 干货!小白入门Python数据科学全教程
前言 本文讲解了从零开始学习Python数据科学的全过程,涵盖各种工具和方法 你将会学习到如何使用python做基本的数据分析 你还可以了解机器学习算法的原理和使用 说明 先说一段题外话.我是一名数据 ...
- 【数据科学】Python数据可视化概述
注:很早之前就打算专门写一篇与Python数据可视化相关的博客,对一些基本概念和常用技巧做一个小结.今天终于有时间来完成这个计划了! 0. Python中常用的可视化工具 Python在数据科学中的地 ...
- python文件输入和输出
1.1文件对象 文件只是连续的字节序列.数据的传输经常会用到字节流,无论字节流是由单个字节还是大块数据组成.1.2文件内建函数open()和file() 内建函数open()的基本语法是: file_ ...
- 《Python数据科学手册》第五章机器学习的笔记
目录 <Python数据科学手册>第五章机器学习的笔记 0. 写在前面 1. 判定系数 2. 朴素贝叶斯 3. 自举重采样方法 4. 白化 5. 机器学习章节总结 <Python数据 ...
随机推荐
- 多测师讲解html _无序列表006_高级讲师肖sir
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>无 ...
- BST,Splay平衡树学习笔记
BST,Splay平衡树学习笔记 1.二叉查找树BST BST是一种二叉树形结构,其特点就在于:每一个非叶子结点的值都大于他的左子树中的任意一个值,并都小于他的右子树中的任意一个值. 2.BST的用处 ...
- requirements基本使用
requirements作用描述:很多 Python 项目中经常会包含一个 requirements.txt 文件,里面内容是项目的依赖包及其对应版本号的信息列表,即项目依赖关系清单,其作用是用来重新 ...
- 使用C++标准库cout输出枚举类型
由于枚举类型呢,是属于一种标签类型,所以在使用std::cout输出的时候,会导致无法匹配数据类型而导致cout函数失败. 这里给的建议呢就是在想要输出的时候,将枚举类型转换为数据类型就可以啦. 如: ...
- Dubbo 常用模型
先了解如下几个概念 Invoker Invoker 是实体域,它是 Dubbo 的核心模型,其它模型都向它靠扰,或转换成它,它代表一个可执行体,可向它发起 invoke 调用,它有可能是一个本地的实现 ...
- 【手摸手,带你搭建前后端分离商城系统】03 整合Spring Security token 实现方案,完成主业务登录
[手摸手,带你搭建前后端分离商城系统]03 整合Spring Security token 实现方案,完成主业务登录 上节里面,我们已经将基本的前端 VUE + Element UI 整合到了一起.并 ...
- frida框架hook获取方法输出参数(常用于简单的so输出参数获取,快速开发)
一.模板 function douyinencode(data) { var result = {}; Java.perform(function () { try { var Test = Java ...
- git 团队协作的一些命令
1.开分支 git branch 新分支名 例如,在master分支下,新开一个开发分支: git branch dev 2.切换到新分支 git checkout 分支名 例如,在master分支下 ...
- 浅谈DevOps
DevOps: Development和Operations的组合,是一种软件开发方法,涉及软件在整个开发生命周期中的持续开发,持续测试,持续集成,持续部署和持续监控. 可以把DevOps看作系统开发 ...
- origin把点图和线图放在一起
首先分别做好点图和线图在两个graph中,然后选中其中一副图(点图或者线图),然后按下图选择: 如果有多个图,可以在弹出窗口中选择多个sheet.