Python爬虫学习第一记 (翻译小助手)
1 # Python爬虫学习第一记 8.24 (代码有点小,请放大看吧)
2
3 #实现有道翻译,模块一: $fanyi.py
4
5 import urllib.request
6 import urllib.parse
7 import json
8
9 # word 是将要传入的翻译的内容
10
11 def fanyi(word):
12 while 1:
13 # 去掉url中的 _o 可以解决反爬虫机制
14 url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
15 data={} # 定义一个data字典
16
17 data['i']= word #don't del
18 data['doctype']='json' #don't del
19
20 #data['from']='AUTO'
21 #data['version']='2.1'
22 #data['keyfrom']='fanyi.web'
23 #data['ue']='utf-8'
24 #data['typoResult']='true'
25
26 # 对数据进行编码处理
27 data=urllib.parse.urlencode(data).encode('utf-8')
28
29 # 创建一个res对象,把url和data传进去,并且同时打开这个请求,并且需要注意的使用的是POST请求
30 res = urllib.request.urlopen(url,data)
31 # 进行读取数据并且进行解码操作
32 html=res.read().decode('utf-8')
33 tar=json.loads(html)
34
35 # 返回值为t,也就是翻译之后的内容
36 t=tar['translateResult'][0][0]['tgt']
37 return t
38
39 #初步完成,使用示例:t = fanyi('hello')
------BTLord 小白工作室

以上是第一个模块,接下来将引用以上的这个模块,利用easygui来创建简单图形用户界面
1 # 翻译的小助手 $ 8.27 爬虫(GUI简单界面)
2 import easygui as g
3 import sys
4
import fanyi # 添加翻译模块 while 1:
# 弹出一个对话编辑框
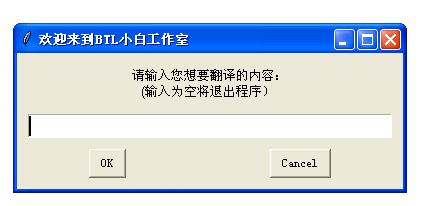
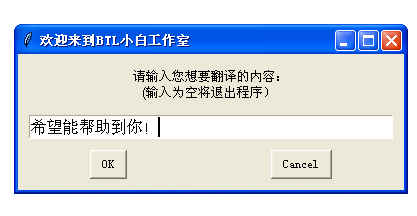
ret=g.enterbox('请输入您想要翻译的内容:\n (输入为空将退出程序)','欢迎来到BTL小白工作室')
# 判断用户点击情况,并且执行相应内容 if ret==None:
sys.exit(0) # 判断点 × 和取消 键的情况,如果是,退出程序 t=fanyi.fanyi(ret)
# 弹出一个选择框,返回值为1或0
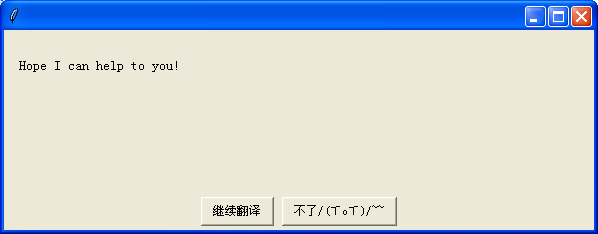
if g.ccbox(t,choices=("继续翻译","不了/(ㄒoㄒ)/~~")):
t=fanyi.fanyi(ret)
else:
sys.exit(0) # 翻译的小程序到此,告一段落,(为什么是 小 程序呢,因为它只能翻译少许内容,具体多少呢,嘿嘿嘿!)
 这两个文件必须在同一个目录,才可以执行。
这两个文件必须在同一个目录,才可以执行。
附上程序图 :
2020-08-27 -BTL 小白工作室
Python爬虫学习第一记 (翻译小助手)的更多相关文章
- Python爬虫学习==>第一章:Python3+Pip环境配置
前置操作 软件名:anaconda 版本:Anaconda3-5.0.1-Windows-x86_64清华镜像 下载链接:https://mirrors.tuna.tsinghua.edu.cn/ ...
- Pyqt5开发一款小工具(翻译小助手)
翻译小助手 开发需求 首先五月份的时候,正在学习爬虫的中级阶段,这时候肯定要接触到js逆向工程,于是上网找了一个项目来练练手,这时碰巧有如何进行对百度翻译的API破解思路,仿造网上的思路,我摸索着完成 ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
随机推荐
- JavaScript基础-06-正则表达式
正则表达式 1. 正则表达式用于定义一些字符串的规则:计算机可以根据正则表达式,来检查一个字符串是否符合规则,将字符串中符合规则的内容提取出来. 2. 创建正则表达式对象: var reg=new R ...
- 三分钟秒懂BIO/NIO/AIO区别?
首先来举个例子说明吧,假设你想吃一份盖饭: 同步阻塞:你到饭馆点餐,然后在那等着,还要一边喊:好了没啊! 同步非阻塞:在饭馆点完餐,就去遛狗了.不过溜一会儿,就回饭馆喊一声:好了没啊! 异步阻塞:遛狗 ...
- 【深度学习】:一门入门3D计算机视觉
一.导论 目前深度学习已经在2D计算机视觉领域取得了非凡的成果,比如使用一张图像进行目标检测,语义分割,对视频当中的物体进行目标跟踪等任务都有非常不错的效果.传统的3D计算机视觉则是基于纯立体几何来实 ...
- 通过CMD远程操作Linux系统
一.文件传输 方法:使用sftp连接方式,sftp 是一个交互式文件传输程式.它类似于 ftp, 但它进行加密传输,比FTP有更高的安全性 命令: //登入:sftp username@ip sftp ...
- /usr/bin/ld: cannot find -lxxx 问题
linux下编译应用程序常常会出现如下错误: /usr/bin/ld: cannot find -lxxx 意思是编译过程找不到对应库文件.其中,-lxxx表示链接库文件 libxxx.so. 注:有 ...
- Hive日期、时间转换:YYYY-MM-DD与YYYYMMDD;hh.mm.ss与hhmmss的相互转换
思路 YYYY-MM-DD与YYYYMMDD:hh-mm-ss与hhmmss的相互转换有两种办法,第一种是利用UNIX时间戳函数,第二种是利用字符串拼接函数. YYYY-MM-DD与YYYYMMDD相 ...
- APEX安装
git clone https://github.com/NVIDIA/apex.gitcd apex export CUDA_HOME=/usr/local/cudapip3 install -v ...
- postman 基本应用
前言 进行post高级应用的一个整理. 正文 批量测试和简单自动化测试 在点击collects的列表中,会弹出下面这个选项. 上面有3个按钮,分别是分享.运行.展示在网页中. 那么就看下这个运行吧. ...
- 牛客网PAT练兵场-德才论
题解:用sort排序即可 题目地址:https://www.nowcoder.com/questionTerminal/97b6a49a85944650b2e3d0660b91c324 /** * C ...
- docker-compose 官网下载特别慢怎么办?
docker compose 官放推荐的下载方式是这样的: sudo curl -L "https://github.com/docker/compose/releases/download ...