通过例子讲解Spring Batch入门,优秀的批处理框架
1 前言
欢迎访问南瓜慢说 www.pkslow.com获取更多精彩文章!
Spring相关文章:Springboot-Cloud相关
Spring Batch是一个轻量级的、完善的批处理框架,作为Spring体系中的一员,它拥有灵活、方便、生产可用的特点。在应对高效处理大量信息、定时处理大量数据等场景十分简便。
结合调度框架能更大地发挥Spring Batch的作用。
2 Spring Batch的概念知识
2.1 分层架构
Spring Batch的分层架构图如下:
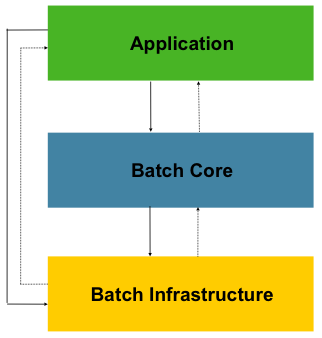
可以看到它分为三层,分别是:
Application应用层:包含了所有任务batch jobs和开发人员自定义的代码,主要是根据项目需要开发的业务流程等。Batch Core核心层:包含启动和管理任务的运行环境类,如JobLauncher等。Batch Infrastructure基础层:上面两层是建立在基础层之上的,包含基础的读入reader和写出writer、重试框架等。
2.2 关键概念
理解下图所涉及的概念至关重要,不然很难进行后续开发和问题分析。

2.2.1 JobRepository
专门负责与数据库打交道,对整个批处理的新增、更新、执行进行记录。所以Spring Batch是需要依赖数据库来管理的。
2.2.2 任务启动器JobLauncher
负责启动任务Job。
2.2.3 任务Job
Job是封装整个批处理过程的单位,跑一个批处理任务,就是跑一个Job所定义的内容。
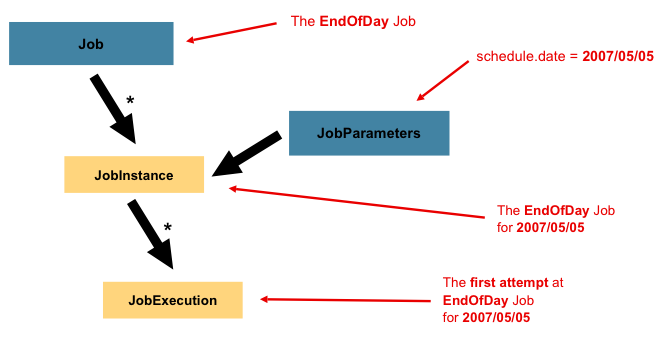
上图介绍了Job的一些相关概念:
Job:封装处理实体,定义过程逻辑。JobInstance:Job的运行实例,不同的实例,参数不同,所以定义好一个Job后可以通过不同参数运行多次。JobParameters:与JobInstance相关联的参数。JobExecution:代表Job的一次实际执行,可能成功、可能失败。
所以,开发人员要做的事情,就是定义Job。
2.2.4 步骤Step
Step是对Job某个过程的封装,一个Job可以包含一个或多个Step,一步步的Step按特定逻辑执行,才代表Job执行完成。
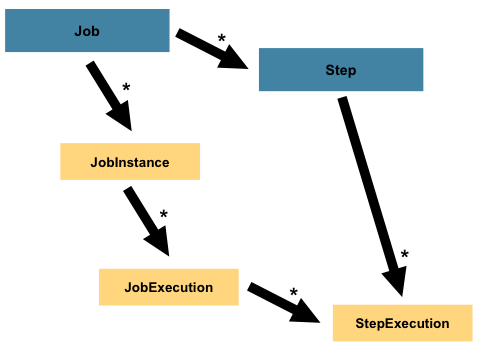
通过定义Step来组装Job可以更灵活地实现复杂的业务逻辑。
2.2.5 输入——处理——输出
所以,定义一个Job关键是定义好一个或多个Step,然后把它们组装好即可。而定义Step有多种方法,但有一种常用的模型就是输入——处理——输出,即Item Reader、Item Processor和Item Writer。比如通过Item Reader从文件输入数据,然后通过Item Processor进行业务处理和数据转换,最后通过Item Writer写到数据库中去。
Spring Batch为我们提供了许多开箱即用的Reader和Writer,非常方便。
3 代码实例
理解了基本概念后,就直接通过代码来感受一下吧。整个项目的功能是从多个csv文件中读数据,处理后输出到一个csv文件。
3.1 基本框架
添加依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
需要添加Spring Batch的依赖,同时使用H2作为内存数据库比较方便,实际生产肯定是要使用外部的数据库,如Oracle、PostgreSQL。
入口主类:
@SpringBootApplication
@EnableBatchProcessing
public class PkslowBatchJobMain {
public static void main(String[] args) {
SpringApplication.run(PkslowBatchJobMain.class, args);
}
}
也很简单,只是在Springboot的基础上添加注解@EnableBatchProcessing。
领域实体类Employee:
package com.pkslow.batch.entity;
public class Employee {
String id;
String firstName;
String lastName;
}
对应的csv文件内容如下:
id,firstName,lastName
1,Lokesh,Gupta
2,Amit,Mishra
3,Pankaj,Kumar
4,David,Miller
3.2 输入——处理——输出
3.2.1 读取ItemReader
因为有多个输入文件,所以定义如下:
@Value("input/inputData*.csv")
private Resource[] inputResources;
@Bean
public MultiResourceItemReader<Employee> multiResourceItemReader()
{
MultiResourceItemReader<Employee> resourceItemReader = new MultiResourceItemReader<Employee>();
resourceItemReader.setResources(inputResources);
resourceItemReader.setDelegate(reader());
return resourceItemReader;
}
@Bean
public FlatFileItemReader<Employee> reader()
{
FlatFileItemReader<Employee> reader = new FlatFileItemReader<Employee>();
//跳过csv文件第一行,为表头
reader.setLinesToSkip(1);
reader.setLineMapper(new DefaultLineMapper() {
{
setLineTokenizer(new DelimitedLineTokenizer() {
{
//字段名
setNames(new String[] { "id", "firstName", "lastName" });
}
});
setFieldSetMapper(new BeanWrapperFieldSetMapper<Employee>() {
{
//转换化后的目标类
setTargetType(Employee.class);
}
});
}
});
return reader;
}
这里使用了FlatFileItemReader,方便我们从文件读取数据。
3.2.2 处理ItemProcessor
为了简单演示,处理很简单,就是把最后一列转为大写:
public ItemProcessor<Employee, Employee> itemProcessor() {
return employee -> {
employee.setLastName(employee.getLastName().toUpperCase());
return employee;
};
}
3.2.3 输出ItremWriter
比较简单,代码及注释如下:
private Resource outputResource = new FileSystemResource("output/outputData.csv");
@Bean
public FlatFileItemWriter<Employee> writer()
{
FlatFileItemWriter<Employee> writer = new FlatFileItemWriter<>();
writer.setResource(outputResource);
//是否为追加模式
writer.setAppendAllowed(true);
writer.setLineAggregator(new DelimitedLineAggregator<Employee>() {
{
//设置分割符
setDelimiter(",");
setFieldExtractor(new BeanWrapperFieldExtractor<Employee>() {
{
//设置字段
setNames(new String[] { "id", "firstName", "lastName" });
}
});
}
});
return writer;
}
3.3 Step
有了Reader-Processor-Writer后,就可以定义Step了:
@Bean
public Step csvStep() {
return stepBuilderFactory.get("csvStep").<Employee, Employee>chunk(5)
.reader(multiResourceItemReader())
.processor(itemProcessor())
.writer(writer())
.build();
}
这里有一个chunk的设置,值为5,意思是5条记录后再提交输出,可以根据自己需求定义。
3.4 Job
完成了Step的编码,定义Job就容易了:
@Bean
public Job pkslowCsvJob() {
return jobBuilderFactory
.get("pkslowCsvJob")
.incrementer(new RunIdIncrementer())
.start(csvStep())
.build();
}
3.5 运行
完成以上编码后,执行程序,结果如下:
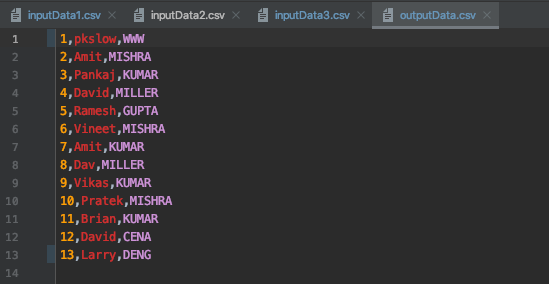
成功读取数据,并将最后字段转为大写,并输出到outputData.csv文件。
4 监听Listener
可以通过Listener接口对特定事件进行监听,以实现更多业务功能。比如如果处理失败,就记录一条失败日志;处理完成,就通知下游拿数据等。
我们分别对Read、Process和Write事件进行监听,对应分别要实现ItemReadListener接口、ItemProcessListener接口和ItemWriteListener接口。因为代码比较简单,就是打印一下日志,这里只贴出ItemWriteListener的实现代码:
public class PkslowWriteListener implements ItemWriteListener<Employee> {
private static final Log logger = LogFactory.getLog(PkslowWriteListener.class);
@Override
public void beforeWrite(List<? extends Employee> list) {
logger.info("beforeWrite: " + list);
}
@Override
public void afterWrite(List<? extends Employee> list) {
logger.info("afterWrite: " + list);
}
@Override
public void onWriteError(Exception e, List<? extends Employee> list) {
logger.info("onWriteError: " + list);
}
}
把实现的监听器listener整合到Step中去:
@Bean
public Step csvStep() {
return stepBuilderFactory.get("csvStep").<Employee, Employee>chunk(5)
.reader(multiResourceItemReader())
.listener(new PkslowReadListener())
.processor(itemProcessor())
.listener(new PkslowProcessListener())
.writer(writer())
.listener(new PkslowWriteListener())
.build();
}
执行后看一下日志:
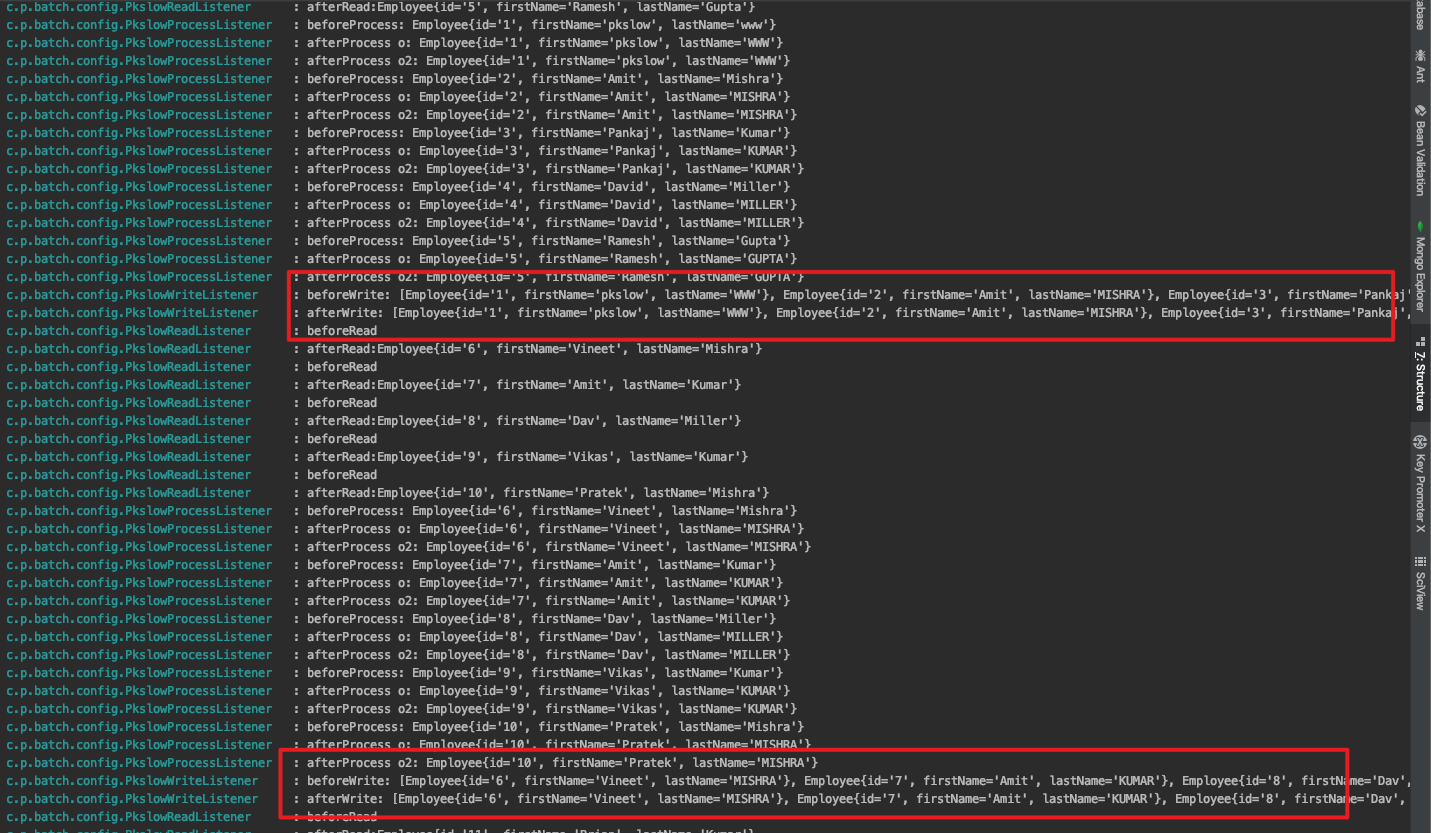
这里就能明显看到之前设置的chunk的作用了。Writer每次是处理5条记录,如果一条输出一次,会对IO造成压力。
5 总结
Spring Batch还有许多优秀的特性,如面对大量数据时的并行处理。本文主要入门介绍为主,不一一介绍,后续会专门讲解。
欢迎关注微信公众号<南瓜慢说>,将持续为你更新...

多读书,多分享;多写作,多整理。
通过例子讲解Spring Batch入门,优秀的批处理框架的更多相关文章
- Spring Boot下Spring Batch入门实例
一.About Spring Batch是什么能干什么,网上一搜就有,但是就是没有入门实例,能找到的例子也都是2.0的,看文档都是英文无从下手~~~,使用当前最新的版本整合网络上找到的例子. 关于基础 ...
- 大量数据也不在话下,Spring Batch并行处理四种模式初探
1 前言 欢迎访问南瓜慢说 www.pkslow.com获取更多精彩文章! Spring相关文章:Springboot-Cloud 前面写了一篇文章<通过例子讲解Spring Batch入门,优 ...
- Spring Batch远程分区的本地Jar包模式
1 前言 欢迎访问南瓜慢说 www.pkslow.com获取更多精彩文章! Spring相关文章:Springboot-Cloud Spring Batch远程分区对于大量数据的处理非常擅长,它的实现 ...
- spring boot + spring batch 读数据库文件写入文本文件&读文本文件写入数据库
好久没有写博客,换了一家新公司,原来的公司用的是spring,现在这家公司用的是spring boot.然后,项目组布置了一个任务,关于两个数据库之间的表同步,我首先想到的就是spring batch ...
- spring batch批量处理框架
spring batch精选,一文吃透spring batch批量处理框架 前言碎语 批处理是企业级业务系统不可或缺的一部分,spring batch是一个轻量级的综合性批处理框架,可用于开发企业信息 ...
- Spring Batch 中文参考文档 V3.0.6 - 1 Spring Batch介绍
1 Spring Batch介绍 企业领域中许多应用系统需要采用批处理的方式在特定环境中运行业务操作任务.这种业务作业包括自动化,大量信息的复杂操作,他们不需要人工干预,并能高效运行.这些典型作业包括 ...
- spring batch学习笔记
Spring Batch是什么? Spring Batch是一个基于Spring的企业级批处理框架,按照我师父的说法,所有基于Spring的框架都是使用了spring的IoC特性,然后加上 ...
- Spring Batch 跑批框架
SpringBatch的框架包括启动批处理作业的组件和存储Job执行产生的元数据. 如果作为一个批处理应用程序的开发人员,你暂时没有必要跟这些组件打交道, 因为它们主要为我们提供组件支持的角色,但是您 ...
- 陪你解读Spring Batch(一)Spring Batch介绍
前言 整个章节由浅入深了解Spring Batch,让你掌握批处理利器.面对大批量数据毫无惧色.本章只做介绍,后面章节有代码示例.好了,接下来是我们的主角Spring Batch. 1.1 背景介绍 ...
随机推荐
- 2020-04-10:有一个 API 服务,后端只使用了数据库来持久化数据,平时在 API 网关上监控到响应时间平均值大约为10ms,现在突然上涨到 5s,而且一直居高不下。请简单描述一下你排查这个问题的思路。
福哥答案2020-04-11: 1 排查api服务 是否是有大量请求 2 查看mysql的系统情况 cpu 磁盘io 连接数 还是要先定位问题出现在哪个环节
- C#LeetCode刷题之#387-字符串中的第一个唯一字符(First Unique Character in a String)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/3939 访问. 给定一个字符串,找到它的第一个不重复的字符,并返回 ...
- .Net微服务实战之Kubernetes的搭建与使用
系列文章 .Net微服务实战之技术选型篇 .Net微服务实战之技术架构分层篇 .Net微服务实战之DevOps篇 .Net微服务实战之负载均衡(上) .Net微服务实战之CI/CD 前言 说到微服务就 ...
- 【算法•日更•第三十二期】教你用出windows体验的Linux
▎前言 小编昨天闲的不行,就装了一个linux系统,linux的发行版很多,小编认为ubuntu很好用,于是就在使用ubuntu. 没错,我现在就在使用ubuntu来写博客. 刚才还装了一个QQ,不过 ...
- js使用html2canvas 生成图片然后下载
1:html2canvas官网 首先去官网把这个JS下载下来 <!DOCTYPE html> <html lang="en"> <head> & ...
- MySQL数据库练习题
表结构 DROP DATABASE IF EXISTS test1; CREATE DATABASE test1; USE test1; ##部门表 #DROP IF EXISTS TABLE DEP ...
- Vue管理系统前端系列三登录页和首页及`vuex`管理登录状态
目录 登录页面设计 vuex 对应 用户模块 丰富界面 首页相关代码 登录页面设计 该节记录了登录界面的设计,以及 vuex 的简单实用,然后将首页简单搭建完成. 先看最终效果图 先在 views 文 ...
- install-newton部署安装--------控制节点
#################################################################################################### ...
- hdu.2042 超级楼梯
这种递归来写,除了递归我也想不到怎么写了 AC代码: #include<iostream>using namespace std;int x[41];//打表,不打表我不用想就知道过不了, ...
- Java——注解
注解的产生背景以前,xml以低耦合的方式得到了广大开发者的青睐,xml在当时基本上能完成框架中的所有配置.但是随着项目越来越庞大,xml的配置也越来越复杂,维护性也随之降低,维护成本增高.于是就产生了 ...