Springboot+JPA下实现简易爬虫:豆瓣电视剧数据
Springboot+JPA下实现简易爬虫:豆瓣电视剧数据
前言:今天听到产品那边讨论一些需求,好像其中一点是用户要求我们爬虫,在网页上抓取一些数据然后存到我们公司数据库中,众所周知,爬虫的实现对于python语言可是专家,而对于我们使用的Java语言,我也不确定可不可以,趁着无事,上网参考了下资料,自己也写了些demo,所幸爬取数据成功了,由于我使用的基础demo项目是自己搭建的springboot+jpa的项目,因此也会在这个基础上进行爬虫的实现,文章会贴出具体的步骤以及重要的代码,至于项目的搭建就不介绍了,我的完整代码会同步至gitHub,大家可以参考使用,当然也可以使用自己的springboot项目。
gitHub地址:https://github.com/Slience-zae/mail-demo.git
1.材料准备
1.1首先打开豆瓣的网页,同时F12打开控制台

1.2 在控制台中找到接口url,请求头信息,以及相应数据格式和字段
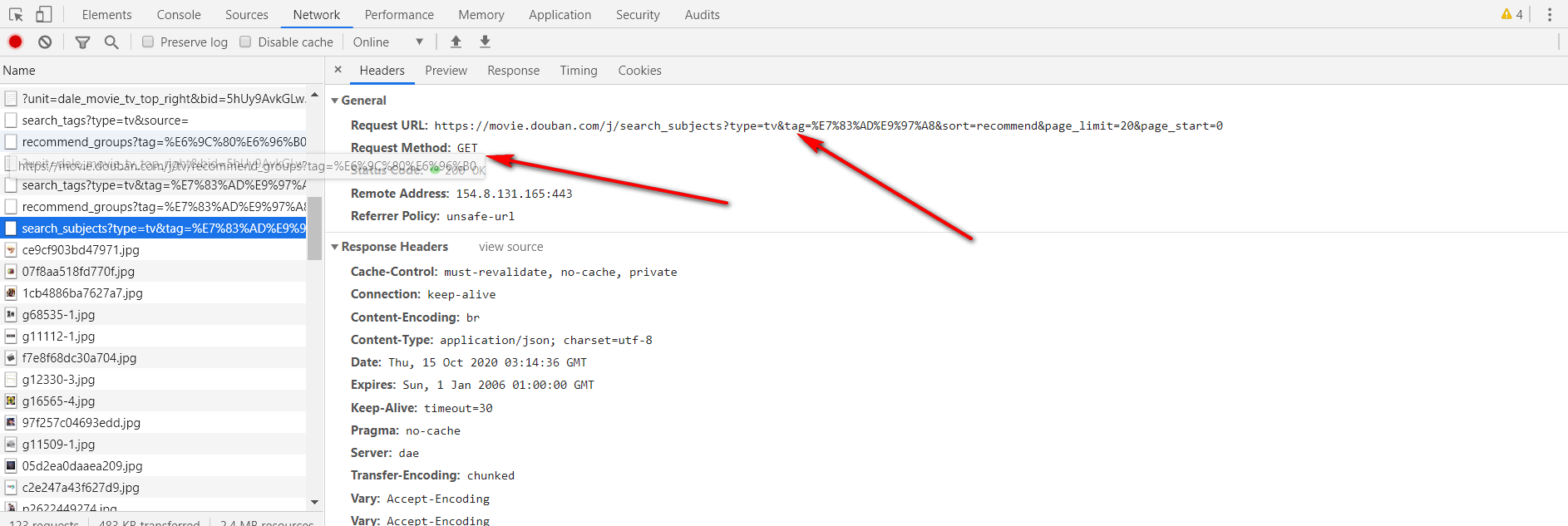
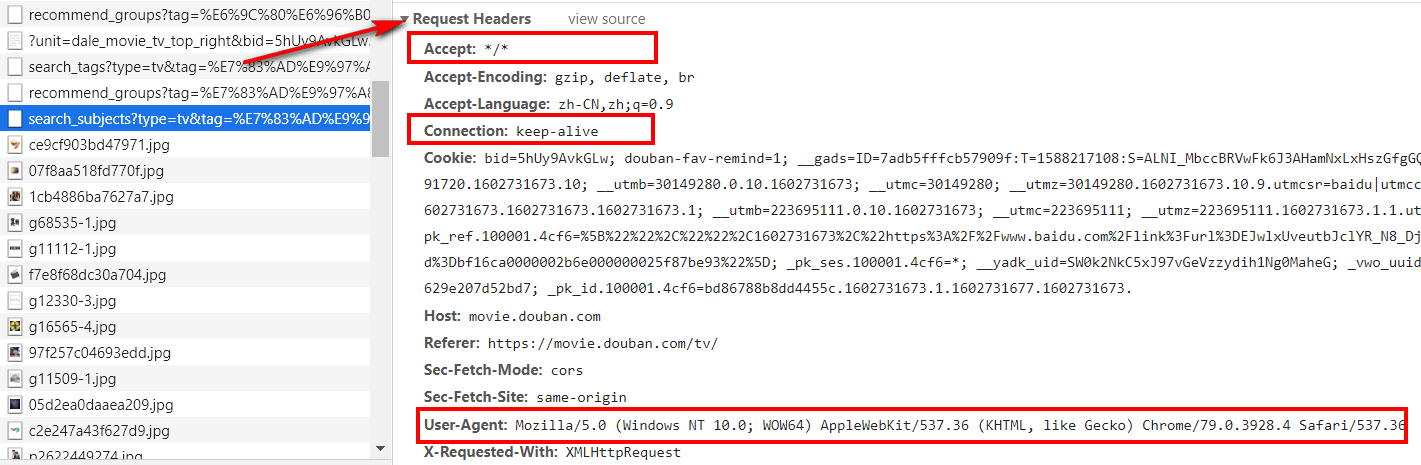
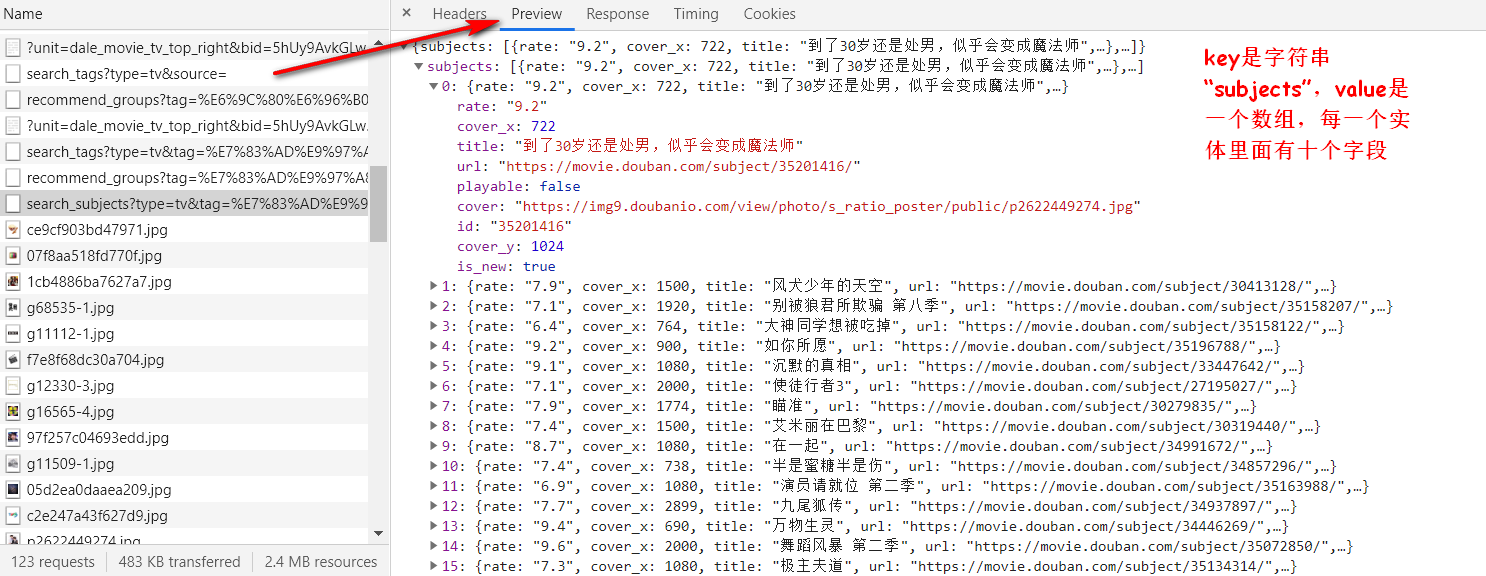
在网页上准备的材料这些就可以了,接下来,该动手撰写代码了。
2.代码实现步骤
2.1 数据库创建表格
CREATE TABLE `subjects` (
`id` varchar(255) NOT NULL COMMENT 'id',
`title` varchar(255) DEFAULT NULL COMMENT '标题',
`rate` decimal(10,2) DEFAULT NULL COMMENT '豆瓣评分',
`url` varchar(255) DEFAULT NULL COMMENT '观影地址',
`playable` tinyint(4) DEFAULT NULL COMMENT '是否可以观看:0是 1否',
`cover` varchar(255) DEFAULT NULL COMMENT '封面图片地址',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
通过相应数据可以得知共有九个字段,但是我们主要保存的是数据主要信息,其中cover_x,cover_y,is_new对于我们来说没有什么意义,可以不保存到数据库,因此略过。
2.2 hibernate逆向生成实体
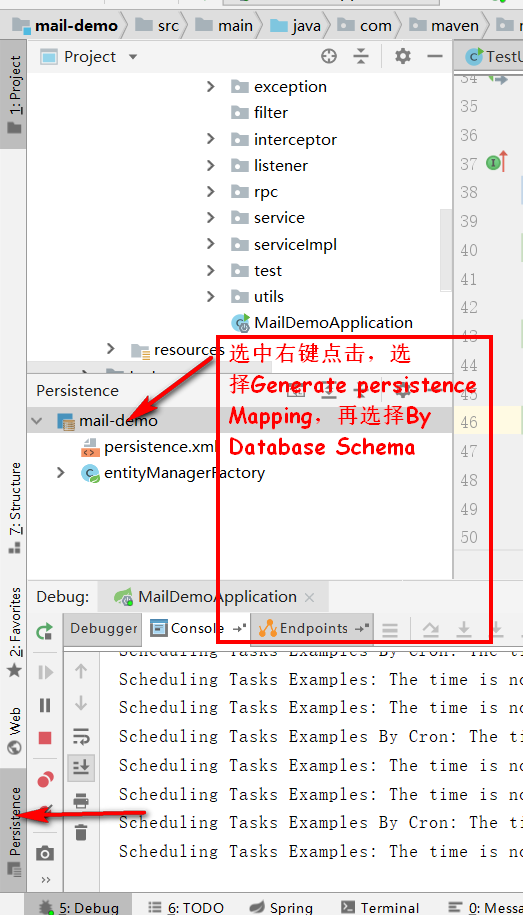
选中右键点击,选择Generate persistence Mapping,再选择By Database Schema,选中数据库的表,再选择生成实体的包位置,最后点击ok就能生成到指定位置了,生成后我们再加以修改一下实体,大体是这个样子。
import lombok.Data;
import javax.persistence.*;
import java.math.BigDecimal;
@Data
@Entity
@Table(name = "subjects")
public class Subjects {
@Id
private String id;//id
private String title;//标题
private BigDecimal rate;//豆瓣评分
private String url;//观影地址
private Boolean playable;//是否能够观看
private String cover;//封面图片URL
@Transient
private Integer cover_x;
@Transient
private Integer cover_y;
@Transient
private Boolean is_new;
}
在此说明一下,之所以将cover_x,cover_y,is_new三个字段也添加进实体了,是为了防止接下来json数组转化List<Subjects>时发生异常,我已经在这三个字段上加了@Transient注解,因此三个字段不会映射数据库。
2.3 编写向指定网址抓取json数据的工具类
import org.springframework.boot.configurationprocessor.json.JSONObject;
import org.springframework.stereotype.Component;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
@Component
public class GetJson {
public JSONObject getHttpJson(String url){
try {
URL realUrl = new URL(url);
HttpURLConnection connection = (HttpURLConnection) realUrl.openConnection();
//设置HTTP的请求头(参考材料准备截图的请求头信息)
connection.setRequestProperty("Accept", "*/*");//设置浏览器可以接收的媒体类型
connection.setRequestProperty("Connection", "keep-alive");//网页打开,建立连接
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3928.4 Safari/537.36");//客户端使用的操作系统和浏览器的名称和版本
// 建立实际的连接
connection.connect();
//请求成功
if (connection.getResponseCode() == 200) {
InputStream is = connection.getInputStream();
//创建字节数组输出流对象
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
//10MB的缓存
byte[] buffer = new byte[10485760];
int len = 0;
while ((len = is.read(buffer))!= -1) {
byteArrayOutputStream.write(buffer, 0, len);
}
String jsonString = byteArrayOutputStream.toString();
byteArrayOutputStream.close();
is.close();
//转换成json数据返回
return new JSONObject(jsonString);
}
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
注意一点,设置连接对象的请求头信息的时候,要将我们在豆瓣上拿到的那几个参数设置成一样的,防止抓取数据失败,具体那几个参数是什么,已经在代码注释上加以说明了。
2.4 完整业务代码糅合实现
(1).在application.properties配置文件中加入以下代码
#豆瓣网址
douban_url= https://movie.douban.com/j/search_subjects
(2) dao层加入类
import com.maven.maildemo.entity.Subjects;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
import org.springframework.data.repository.CrudRepository; public interface SubjectsDao extends CrudRepository<Subjects, String>, JpaSpecificationExecutor<Subjects> { }
(3) service,serviceImpl,controller层代码
import com.maven.maildemo.entity.Subjects;
import java.util.List; public interface SubjectsService {
/**
* 在豆瓣网页上抓取电视剧信息保存并返回
* @author zae
* @param pageNumber 页码
*/
List<Subjects> getAndSaveSubjectsList(Integer pageNumber) throws Exception;
}
import com.alibaba.fastjson.JSON;
import com.maven.maildemo.dao.SubjectsDao;
import com.maven.maildemo.entity.Subjects;
import com.maven.maildemo.service.SubjectsService;
import com.maven.maildemo.utils.GetJson;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.configurationprocessor.json.JSONArray;
import org.springframework.boot.configurationprocessor.json.JSONObject;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.ArrayList;
import java.util.List; @Slf4j
@Service
@Transactional
public class SubjectsServiceImpl implements SubjectsService { @Value("${douban_url}")
private String doubanUrl; @Autowired
private GetJson getJson; private final String DOUBAN_PARM = "?type=tv&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start="; @Autowired
private SubjectsDao subjectsDao; @Override
public List<Subjects> getAndSaveSubjectsList(Integer pageNumber) throws Exception {
if(pageNumber>=0 && pageNumber <= 10000){
String address = doubanUrl+DOUBAN_PARM+pageNumber;
//获取json对象数据
JSONObject httpJson = getJson.getHttpJson(address);
if(httpJson != null){
//取出json数据数组
JSONArray subjectsArray = httpJson.getJSONArray("subjects");
if(subjectsArray!=null){
//将json数组转化为List
List<Subjects> subjectsList = JSON.parseArray(subjectsArray.toString(),Subjects.class);
for(Subjects subjects:subjectsList){
//爬出数据后,保存在数据库中
subjectsDao.save(subjects);
}
return subjectsList;
}else{
return new ArrayList<>();
}
}else{
return new ArrayList<>();
}
}
return new ArrayList<>();
}
}
import com.alibaba.fastjson.JSON;
import com.maven.maildemo.entity.Subjects;
import com.maven.maildemo.service.SubjectsService;
import io.swagger.annotations.Api;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.List; @RestController
@RequestMapping("subjects")
@Api(description = "豆瓣")
public class SubjectsController {
@Autowired
private SubjectsService subjectsService; /**
* 在豆瓣网页上抓取电视剧信息保存并返回
* @param pageNumber 页码
* @author zae
* @return
*/
@GetMapping(value = "/getAndSaveSubjectsList")
String getAndSaveSubjectsList(@RequestParam Integer pageNumber){
try {
List<Subjects> subjectsList = subjectsService.getAndSaveSubjectsList(pageNumber);
return subjectsList==null?null: JSON.toJSONString(subjectsList);
} catch (Exception e) {
return "爬取数据信息发生异常"+e.getMessage();
}
}
}
业务代码没啥复杂的,基本上都加注释了,看一下就好了。
3.测试
启动项目,打开swaager,找到刚刚写的接口,输入参数点击进行测试。
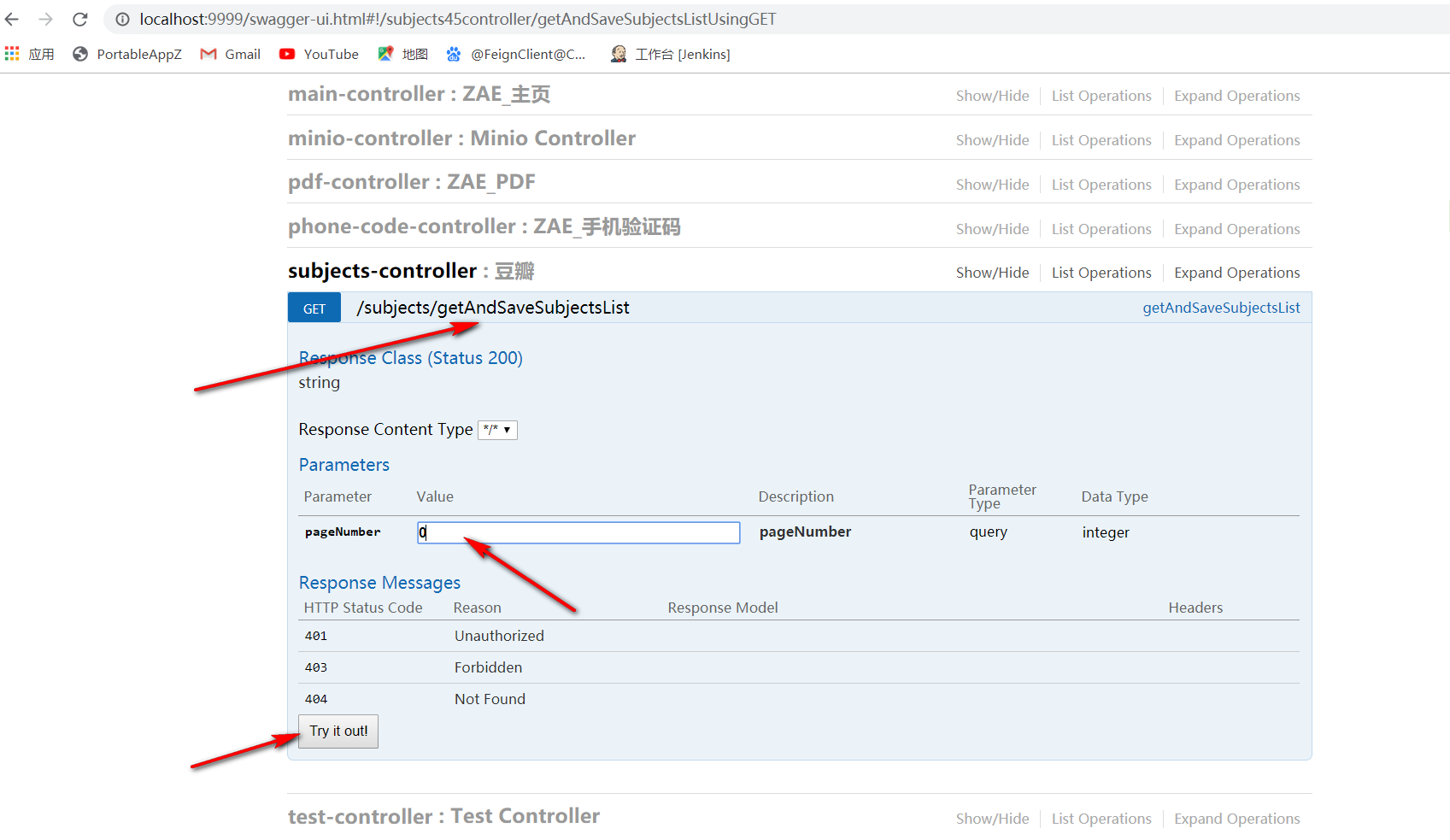
此时不出意外应该是执行成功了,打开数据库,看一下库里有没有我们爬下来的数据。
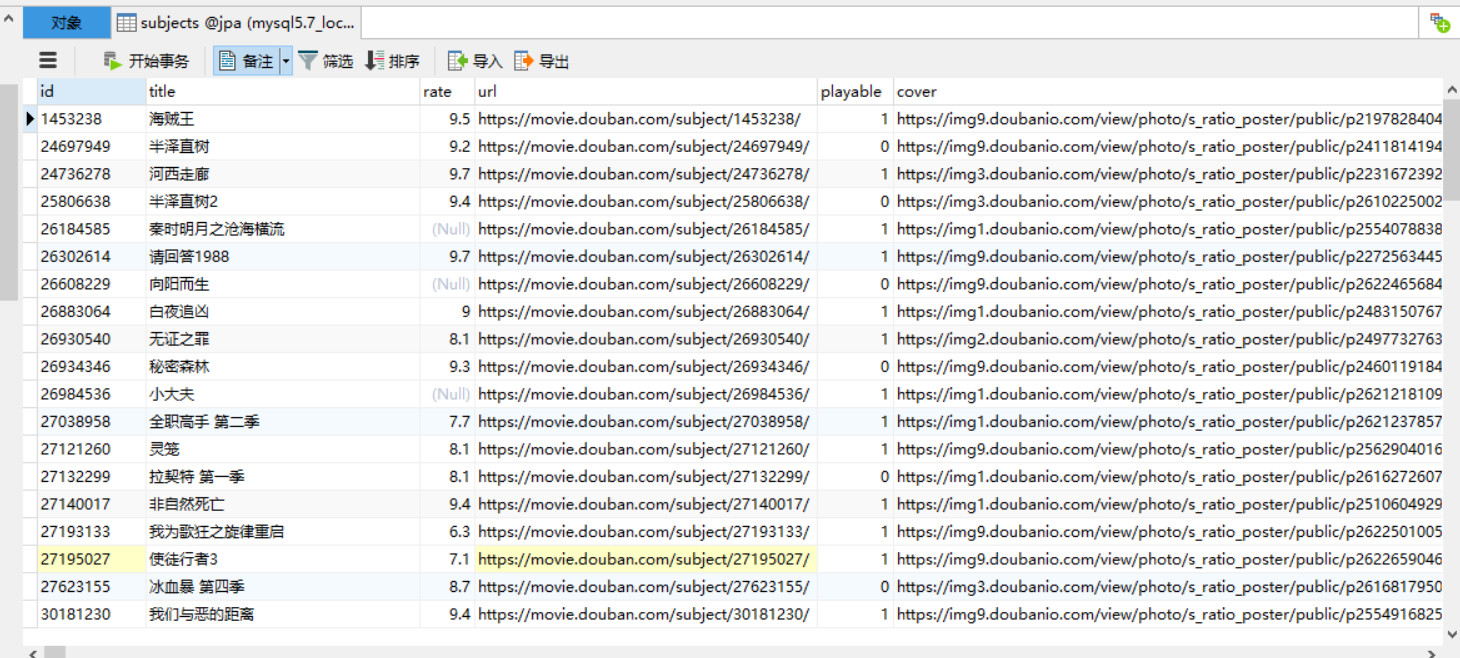
发现库里有值,说明我们已经成功的将数据爬下来了。不仅仅豆瓣如此,其他网页数据也是类似的实现。
本人java爬虫学习借鉴博客:https://blog.csdn.net/qwe86314/article/details/91450098 博主是使用的mybatis结合实现,而我的是结合springboot+jpa的项目使用的。
如有问题,多多评论指教,文章编写不易,期待您的推荐和赞,
Springboot+JPA下实现简易爬虫:豆瓣电视剧数据的更多相关文章
- Python3.5爬取豆瓣电视剧数据并且同步到mysql中
#!/usr/local/bin/python # -*- coding: utf-8 -*- # Python: 3.5 # Author: zhenghai.zhang@xxx.com # Pro ...
- 放养的小爬虫--豆瓣电影入门级爬虫(mongodb使用教程~)
放养的小爬虫--豆瓣电影入门级爬虫(mongodb使用教程~) 笔者声明:只用于学习交流,不用于其他途径.源代码已上传github.githu地址:https://github.com/Erma-Wa ...
- 使用 HttpClient 和 HtmlParser 实现简易爬虫
这篇文章介绍了 HtmlParser 开源包和 HttpClient 开源包的使用,在此基础上实现了一个简易的网络爬虫 (Crawler),来说明如何使用 HtmlParser 根据需要处理 Inte ...
- php+phpquery简易爬虫抓取京东商品分类
这是一个简单的php加phpquery实现抓取京东商品分类页内容的简易爬虫.phpquery可以非常简单地帮助你抽取想要的html内容,phpquery和jquery非常类似,可以说是几乎一样:如果你 ...
- [转]使用 HttpClient 和 HtmlParser 实现简易爬虫
http://www.ibm.com/developerworks/cn/opensource/os-cn-crawler/ http://blog.csdn.net/dancen/article/d ...
- 补习系列(19)-springboot JPA + PostGreSQL
目录 SpringBoot 整合 PostGreSQL 一.PostGreSQL简介 二.关于 SpringDataJPA 三.整合 PostGreSQL A. 依赖包 B. 配置文件 C. 模型定义 ...
- 【原】无脑操作:IDEA + maven + Shiro + SpringBoot + JPA + Thymeleaf实现基础授权权限
上一篇<[原]无脑操作:IDEA + maven + Shiro + SpringBoot + JPA + Thymeleaf实现基础认证权限>介绍了实现Shiro的基础认证.本篇谈谈实现 ...
- 【原】无脑操作:IDEA + maven + Shiro + SpringBoot + JPA + Thymeleaf实现基础认证权限
开发环境搭建参见<[原]无脑操作:IDEA + maven + SpringBoot + JPA + Thymeleaf实现CRUD及分页> 需求: ① 除了登录页面,在地址栏直接访问其他 ...
- 带着新人学springboot的应用08(springboot+jpa的整合)
这一节的内容比较简单,是springboot和jpa的简单整合,jpa默认使用hibernate,所以本质就是springboot和hibernate的整合. 说实话,听别人都说spring data ...
随机推荐
- vue-cli3项目配置eslint代码规范
前言 最近接手了一个项目,由于之前为了快速开发,没有做代码检查.为了使得代码更加规范以及更易读,所以就要eslint上场了. 安装依赖 安装依赖有两种方法: 1. 在cmd中打上把相应的依赖加到dev ...
- vue安装pubsub-js 库的命令
1.查看pubsub-js 库是否已经存在该库命令: npm info pubsub-js 2.若不存在,则先安装pubsub-js 库,命令如下: npm install --save pubsub ...
- Life is not the amount of breath you take.
It's the moments that take you breath away.
- leetcode刷题-95/96/98
题目95题 给定一个整数 n,生成所有由 1 ... n 为节点所组成的 二叉搜索树 . 示例: 输入:3输出:[ [1,null,3,2], [3,2,null,1], [3,1,null,n ...
- leetcode刷题-86分隔链表
题目 给定一个链表和一个特定值 x,对链表进行分隔,使得所有小于 x 的节点都在大于或等于 x 的节点之前. 你应当保留两个分区中每个节点的初始相对位置. 示例: 输入: head = 1->4 ...
- leetcode刷题-56合并区间
题目 给出一个区间的集合,请合并所有重叠的区间. 示例 1: 输入: [[1,3],[2,6],[8,10],[15,18]]输出: [[1,6],[8,10],[15,18]] 思路 通过设置一个移 ...
- Java知识点JUC总结
JUC:java.util.concurrent (Java并发编程工具类) 一般面试提问:面向对象和高级语法.Java集合类.Java多线程.JUC 和高并发.Java IO和 NIO 获取多线程的 ...
- Docker数据卷Volume实现文件共享、数据迁移备份(三)
数据卷volume功能特性 数据卷 是一个可供一个或多个容器使用的特殊目录,实现让容器中的一个目录和宿主机中的一个文件或者目录进行绑定.数据卷 是被设计用来持久化数据的对于数据卷你可以理解为NFS中的 ...
- java 泛型学习随笔
对于java 泛型 编译时处理,运行时擦除的特点理解 对于编译时处理 在使用泛型相关的类或方法时,如果声明时的类型和具体使用时的类型不一致则直接会编译不通过 对于运行时擦除 当在运行时对两个相同类型但 ...
- shiro 退出过滤器 logout ---退出清除HTTPSession数据
重写LogouFilter类 import org.apache.shiro.web.filter.authc.LogoutFilter; public class ShiroLogoutFilter ...