第三篇:CUDA 标准编程模式
前言
本文将介绍 CUDA 编程的基本模式,所有 CUDA 程序都基于此模式编写,即使是调用库,库的底层也是这个模式实现的。
模式描述
1. 定义需要在 device 端执行的核函数。( 函数声明前加 _golbal_ 关键字 )
2. 在显存中为待运算的数据以及需要存放结果的变量开辟显存空间。( cudaMalloc 函数实现 )
3. 将待运算的数据传输进显存。( cudaMemcpy,cublasSetVector 等函数实现 )
4. 调用 device 端函数,同时要将需要为 device 端函数创建的块数线程数等参数传递进 <<<>>>。( 注: <<<>>>下方编译器可能显示语法错误,不用管 )
5. 从显存中获取结果变量。( cudaMemcpy,cublasGetVector 等函数实现 )
6. 释放申请的显存空间。( cudaFree 实现 )
PS:每个 device 端函数在被调用时都能获取到调用它的具体块号,线程号,从而实现并行( 获取方法请参考下面的编程规范说明以及代码示例 )。
编程规范说明
在 CUDA 标准编程模式中,增加了一些编程规范,在这里简要说明:
函数声明关键字:
1. __device__
表明此函数只能在 GPU 中被调用,在 GPU 中执行。这类函数只能被 __global__ 类型函数或 __device__ 类型函数调用。
2. __global__
表明此函数在 CPU 上调用,在 GPU 中执行。这也是以后会常提到的 "内核函数",有时为了便于理解也称 "device" 端函数。
3. __host__
表明此函数在 CPU 上调用和执行,这也是默认情况。
内核函数配置运算符 <<<>>> - 这个运算符在调用内核函数的时候使用,一般情况下传递进三个参数:
1. 块数
2. 线程数
3. 共享内存大小 (此参数默认为0 )
内核函数中的几个系统变量 - 这几个变量可以在内核函数中使用,从而控制块与线程的工作:
1. gridDim:块数
2. blockDim:块中线程数
3. blockIdx:块编号 (0 - gridDim-1)
4. threadIdx:线程编号 (0 - blockDim-1)
知道这些已经足够编写 CUDA 程序了,更多的编程说明将在以后的文章中介绍。
代码示例
该程序采用 CUDA 并行化思想来对数组进行求和 (代码下方如果出现红色波浪线无视之):
// 相关 CUDA 库
#include "cuda_runtime.h"
#include "cuda.h"
#include "device_launch_parameters.h" #include <iostream>
#include <cstdlib> using namespace std; const int N = ; // 块数
const int BLOCK_data = ;
// 各块中的线程数
const int THREAD_data = ; // CUDA初始化函数
bool InitCUDA()
{
int deviceCount; // 获取显示设备数
cudaGetDeviceCount (&deviceCount); if (deviceCount == )
{
cout << "找不到设备" << endl;
return EXIT_FAILURE;
} int i;
for (i=; i<deviceCount; i++)
{
cudaDeviceProp prop;
if (cudaGetDeviceProperties(&prop,i)==cudaSuccess) // 获取设备属性
{
if (prop.major>=) //cuda计算能力
{
break;
}
}
} if (i==deviceCount)
{
cout << "找不到支持 CUDA 计算的设备" << endl;
return EXIT_FAILURE;
} cudaSetDevice(i); // 选定使用的显示设备 return EXIT_SUCCESS;
} // 此函数在主机端调用,设备端执行。
__global__
static void Sum (int *data,int *result)
{
// 取得线程号
const int tid = threadIdx.x;
// 获得块号
const int bid = blockIdx.x; int sum = ; // 有点像网格计算的思路
for (int i=bid*THREAD_data+tid; i<N; i+=BLOCK_data*THREAD_data)
{
sum += data[i];
} // result 数组存放各个线程的计算结果
result[bid*THREAD_data+tid] = sum;
} int main ()
{
// 初始化 CUDA 编译环境
if (InitCUDA()) {
return EXIT_FAILURE;
}
cout << "成功建立 CUDA 计算环境" << endl << endl; // 建立,初始化,打印测试数组
int *data = new int [N];
cout << "测试矩阵: " << endl;
for (int i=; i<N; i++)
{
data[i] = rand()%;
cout << data[i] << " ";
if ((i+)% == ) cout << endl;
}
cout << endl; int *gpudata, *result; // 在显存中为计算对象开辟空间
cudaMalloc ((void**)&gpudata, sizeof(int)*N);
// 在显存中为结果对象开辟空间
cudaMalloc ((void**)&result, sizeof(int)*BLOCK_data*THREAD_data); // 将数组数据传输进显存
cudaMemcpy (gpudata, data, sizeof(int)*N, cudaMemcpyHostToDevice);
// 调用 kernel 函数 - 此函数可以根据显存地址以及自身的块号,线程号处理数据。
Sum<<<BLOCK_data,THREAD_data,>>> (gpudata,result); // 在内存中为计算对象开辟空间
int *sumArray = new int[THREAD_data*BLOCK_data];
// 从显存获取处理的结果
cudaMemcpy (sumArray, result, sizeof(int)*THREAD_data*BLOCK_data, cudaMemcpyDeviceToHost); // 释放显存
cudaFree (gpudata);
cudaFree (result); // 计算 GPU 每个线程计算出来和的总和
int final_sum=;
for (int i=; i<THREAD_data*BLOCK_data; i++)
{
final_sum += sumArray[i];
} cout << "GPU 求和结果为: " << final_sum << endl; // 使用 CPU 对矩阵进行求和并将结果对照
final_sum = ;
for (int i=; i<N; i++)
{
final_sum += data[i];
}
cout << "CPU 求和结果为: " << final_sum << endl; getchar(); return ;
}
运行测试
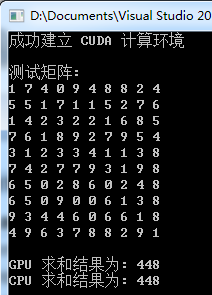
PS:矩阵元素是随机生成的
小结
1. 掌握本节知识的关键除了要掌握各个API,还要深刻理解内核函数中的块及线程变量的控制,或者说施展 :)
2. 一定要明确传递进 API 的是参数本身,还是参数的地址,这很关键。
第三篇:CUDA 标准编程模式的更多相关文章
- CUDA 标准编程模式
前言 本文将介绍 CUDA 编程的基本模式,所有 CUDA 程序都基于此模式编写,即使是调用库,库的底层也是这个模式实现的. 模式描述 1. 定义需要在 device 端执行的核函数.( 函数声明前加 ...
- C#多线程和异步(三)——一些异步编程模式
一.任务并行库 任务并行库(Task Parallel Library)是BCL中的一个类库,极大地简化了并行编程,Parallel常用的方法有For/ForEach/Invoke三个静态方法.在C# ...
- [应用篇]第三篇 JSP 标准标签库(JSTL)总结
有一种友谊叫做: "陪我去小卖部." "不去," "我请你" "走." 你想起了谁:胖先生?还有人陪你吗? JSP 标准 ...
- 【磁盘/文件系统】第三篇:标准磁盘分区流程针对parted(一般硬盘容量大于2T(但是小于2T也可以进行分区);分区数最大是支持100多个分区)
说明: 在 Linux 上可以采用 parted 来对磁盘进行分区 1.通过 fdisk -l 可以查看磁盘是否存在, 由于使用的是大磁盘(大于2T),fdisk 不能用来作为分区工具了,而应该使用 ...
- 第二篇:CUDA 并行编程简介
前言 并行就是让计算中相同或不同阶段的各个处理同时进行. 目前有很多种实现并行的手段,如多核处理器,分布式系统等,而本专题的文章将主要介绍使用 GPU 实现并行的方法. 参考本专题文章前请务必搭建好 ...
- 并发编程之第三篇(synchronized)
并发编程之第三篇(synchronized) 3. 自旋优化 4. 偏向锁 撤销-其它线程使用对象 撤销-调用wait/notify 批量重偏向 批量撤销 5. 锁消除 4.7 wait/notify ...
- 【Windows编程】系列第三篇:文本字符输出
上一篇我们展示了如何使用Windows SDK创建基本控件,本篇来讨论如何输出文本字符. 在使用Win32编程时,我们常常要输出文本到窗口上,Windows所有的文本字符或者图形输出都是通过图形设备接 ...
- Javascript编程模式(JavaScript Programming Patterns)Part 2.(高级篇)
模块编程模式的启示(Revealing Module Pattern) 客户端对象(Custom Objects) 懒函数定义(Lazy Function Definition) Christian ...
- Javascript编程模式(JavaScript Programming Patterns)Part 1.(初级篇)
JavaScript 为网站添加状态,这些状态可能是校验或者更复杂的行为像拖拽终止功能或者是异步的请求webserver (aka Ajax). 在过去的那些年里, JavaScript librar ...
随机推荐
- Android上怎样使用《贝赛尔曲线》
首先对于<赛贝尔曲线>不是很了解的童鞋,请自觉白度百科.google. 为了方便偷懒的童鞋,这里给个<贝赛尔曲线>百科地址,以及一段话简述<贝赛尔曲线>: < ...
- idea 更换编辑器背景图片
插件名称是:BackgroundImage, 安装后效果图
- MySQL查看和修改wait_timeout
1.全局查看wait_timeout值 mysql> show global variables like 'wait_timeout'; 2.修改全局wait_timeout值 set glo ...
- memcached+Mysql(主从)
昨天和守住看了下http://hi.baidu.com/156544632/blog/item/3b26527b68623ff00bd18746.html这篇文章,思路很好,但感觉就是太乱了,而且还出 ...
- 详解登录认证及授权--Shiro系列(一)
Apache Shiro 是一个强大而灵活的开源安全框架,它干净利落地处理身份认证,授权,企业会话管理和加密.Apache Shiro 的首要目标是易于使用和理解.安全有时候是很复杂的,甚至是痛苦的, ...
- CentOS Linux防火墙配置及关闭
CentOS 配置防火墙操作实例(启.停.开.闭端口): 注:防火墙的基本操作命令: 查询防火墙状态: [root@localhost ~]# service iptables status< ...
- 判断是否是IE浏览器和是否是IE11
判断是否是IE浏览器用下面这个函数, function isIE() { //ie? 是ie返回true,否则返回false if (!!window.ActiveXObject || "A ...
- android.animation(7) - android:animateLayoutChanges属性和LayoutTransition
前篇给大家讲了LayoutAnimation的知识,LayoutAnimation虽能实现ViewGroup的进入动画,但只能在创建时有效.在创建后,再往里添加控件就不会再有动画.在API 11后,又 ...
- JAVA-Word转PDF各种版本实现方式
当下做一个项目,就是各种操作office,客户的需求总是各种不按常理,来需求就得搞啊.对JAVA操作office这方面真是头大,弟弟是真滴不懂不会啊.无奈只好试啊试的.网上一大堆好使的,一大堆不好使的 ...
- php html 转义
html_entity_decode($string);htmlentities($string);htmlspecialchars($string);htmlspecialchars_decode( ...