OCR技术浅探: 语言模型和综合评估(4)
语言模型
由于图像质量等原因,性能再好的识别模型,都会有识别错误的可能性,为了减少识别错误率,可以将识别问题跟统计语言模型结合起来,通过动态规划的方法给出最优的识别结果。这是改进OCR识别效果的重要方法之一。
转移概率
在我们分析实验结果的过程中,有出现这一案例。由于图像不清晰等可能的原因,导致“电视”一词被识别为“电柳”,仅用图像模型是不能很好地解决这个问题的,因为从图像模型来看,识别为“电柳”是最优的选择。但是语言模型却可以很巧妙地解决这个问题。原因很简单,基于大量的文本数据我们可以统计“电视”一词和“电柳”一词的概率,可以发现“电视”一词的概率远远大于“电柳”,因此我们会认为这个词是“电视”而不是“电柳”。
从概率的角度来看,就是对于第一个字的区域的识别结果s1,我们前面的卷积神经网络给出了“电”、“宙”两个候选字(仅仅选了前两个,后面的概率太小),每个候选字的概率W(s1)分别为0.99996、0.00004;第二个字的区域的识别结果s2,我们前面的卷积神经网络给出了“柳”、“视”、“规”(仅仅选了前三个,后面的概率太小),每个候选字的概率W(s2)分别为0.87838、0.12148、0.00012,因此,它们事实上有六种组合:“电柳”、“电视”、“电规”、“宙柳”、“宙视”、“宙规”。
下面考虑它们的迁移概率。所谓迁移概率,其实就是条件概率P(s1|s2),即当s1出现时后面接s2的概率。通过10万微信文本,我们统计出,“电”字出现的次数为145001,而“电柳”、“电视“、”电规“出现的次数为0、12426、7;“宙”字出现的次数为1980次,而“宙柳”、“宙视”、“宙规”出现的次数为0、0、18,因此,可以算出

结果如下图:
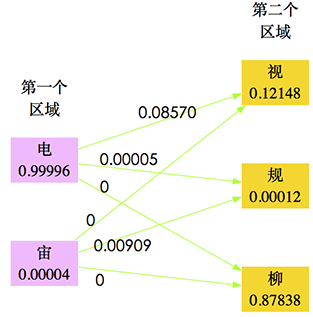
图20 考虑转移概率
从统计的角度来看,最优的s1,s2组合,应该使得式(14)取最大值:
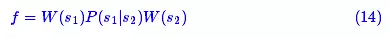
因此,可以算得s1,s2的最佳组合应该是“电视”而不是“电柳”。这时我们成功地通过统计的方法得到了正确结果,从而提高了正确率。
动态规划
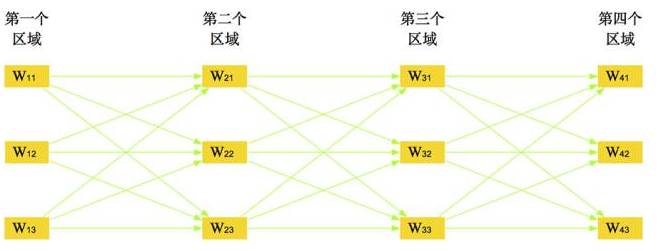
图21 多字图片的规划问题
类似地,如图21,如果一个单行文字图片有n个字 需要确定,那么应当使得
需要确定,那么应当使得
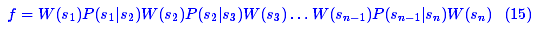
取得最大值,这就是统计语言模型的思想,自然语言处理的很多领域,比如中文分词、语音识别、图像识别等,都用到了同样的方法[6]。这里需要解决两个主要的问题:(1)各个 的估计;(2)给定各个
的估计;(2)给定各个 后如何求解f的最大值。
后如何求解f的最大值。
转移概率矩阵
对于第一个问题,只需要从大的语料库中统计si的出现次数#si,以及si,si+1相接地出现的次数#(si,si+1),然后认为

即可,本质上没有什么困难。本文的识别对象有3062个,理论上来说,应该生成一个3062×3062的矩阵,这是非常庞大的。当然,这个矩阵是非常稀疏的,我们可以只保存那些有价值的元素。
现在要着重考虑当#(si,si+1)=0的情况。在前一节我们就直接当P(si|si+1)=0,但事实上是不合理的。没有出现不能说明不会出现,只能说明概率很小,因此,即便是对于#(si,si+1)=0,也应该赋予一个小概率而不是0。这在统计上称为数据的平滑问题。
一个简单的平滑方法是在所有项的频数(包括频数为0的项)后面都加上一个正的小常数α(比如1),然后重新统计总数并计算频率,这样每个项目都得到了一个正的概率。这种思路有可能降低高频数的项的概率,但由于这里的概率只具有相对意义,因此这个影响是不明显的(一个更合理的思路是当频数小于某个阈值T时才加上常数,其他不加。)。按照这种思路,从数十万微信文章中,我们计算得到了160万的邻接汉字的转移概率矩阵。
Viterbi算法
对于第二个问题,求解最优组合 是属于动态规划中求最优路径的问题,其中最有效的方法是Viterbi算法[6]。
是属于动态规划中求最优路径的问题,其中最有效的方法是Viterbi算法[6]。
Viterbi算法是一个简单高效的算法,用Python实现也就十来行的代码。它的核心思想是:如果最终的最优路径经过某个si−1,那么从初始节点到si−1点的路径必然也是一个最优路径——因为每一个节点si只会影响前后两个P(si−1|si)和P(si|si+1)。
根据这个思想,可以通过递推的方法,在考虑每个si时只需要求出所有经过各si−1的候选点的最优路径,然后再与当前的si结合比较。这样每步只需要算不超过 次,就可以逐步找出最优路径。Viterbi算法的效率是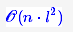 ,l 是候选数目最多的节点si的候选数目,它正比于n,这是非常高效率的。
,l 是候选数目最多的节点si的候选数目,它正比于n,这是非常高效率的。
提升效果
实验表明,结合统计语言模型进行动态规划能够很好地解决部分形近字识别错误的情况。在我们的测试中,它能修正一些错误如下:

通过统计语言模型的动态规划能修正不少识别错误
由于用来生成转移矩阵的语料库不够大,因此修正的效果还有很大的提升空间。不管怎么说,由于Viterbi算法的简单高效,这是一个性价比很高的步骤。
综合评估
1、数据验证
尽管在测试环境下模型工作良好,但是实践是检验真理的唯一标准。在本节中,我们通过自己的模型,与京东的测试数据进行比较验证。
衡量OCR系统的好坏有两部分内容:(1)是否成功地圈出了文字;(2)对于圈出来的文字,有没有成功识别。我们采用评分的方法,对每一张图片的识别效果进行评分。评分规则如下:
如果圈出的文字区域能够跟京东提供的检测样本的box文件中匹配,那么加1分,如果正确识别出文字来,另外加1分,最后每张图片的分数是前面总分除以文字总数。
按照这个规则,每张图片的评分最多是2分,最少是0分。如果评分超过1,说明识别效果比较好了。经过京东的测试数据比较,我们的模型平均评分大约是0.84,效果差强人意。
2、模型综述
在本文中,我们的目标是建立一个完整的OCR系统,经过一系列的工作,我们也基本完成了这一目标。
在设计算法时,我们紧密地结合基本假设,从模拟人肉眼的识别思路出发,希望能够以最少的步骤来实现目标,这种想法在特征提取和文字定位这两部分得到充分体现。
同样地,由于崇尚简洁和模拟人工,在光学字符识别方面,我们选择了卷积神经网络模型,得到了较高的正确率;最后结合语言模型,通过动态规划用较简单的思路提升了效果。
经过测试,我们的系统对印刷文字的识别有着不错的效果,可以作为电商、微信等平台的图片文字识别工具。其中明显的特点是,我们的系统可以将整张文字图片输入,并且在分辨率不高的情况下能够获得较好的效果。
3、结果反思
在本文所涉及到的算法中,一个很大的不足之处就是有很多的“经验参数”,比如聚类时h参数的选择、低密度区定义中密度的阈值、卷积神经网络中的卷积核数据、隐藏层节点数目等。由于并没有足够多的标签样本进行研究,因此,这些参数都只能是凭借着经验和少量的样本推算得出。我们期待会有更多的标签数据来得到这些参数的最优值。
还有,在识别文字区域方面,还有很多值得改进的地方。虽然我们仅仅是经过几个步骤就去掉了大部分的文字区域,但是这些步骤还是欠直观,亟待简化。我们认为,一个良好的模型应该是基于简单的假设和步骤就能得到不错的效果,因此,值得努力的工作之一就是简化假设,缩减流程。
此外,在文本切割方面,事实上不存在一种能够应对任何情况的自动切割算法,因此这一步还有很大的提升空间。据相关文献,可以通过CNN+LSTM模型,直接对单行文本进行识别,但这需要大量的训练样本和高性能的训练机器,估计只有大型企业才能做到这一点。
显然,还有很多工作都需要更深入地研究。
OCR技术浅探: 语言模型和综合评估(4)的更多相关文章
- OCR技术浅探:基于深度学习和语言模型的印刷文字OCR系统
作者: 苏剑林 系列博文: 科学空间 OCR技术浅探:1. 全文简述 OCR技术浅探:2. 背景与假设 OCR技术浅探:3. 特征提取(1) OCR技术浅探:3. 特征提取(2) OCR技术浅探:4. ...
- OCR技术浅探(转)
网址:https://spaces.ac.cn/archives/3785 OCR技术浅探 作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步进行文字定位和第三步进行 ...
- OCR技术浅探:特征提取(1)
研究背景 关于光学字符识别(Optical Character Recognition, 下面都简称OCR),是指将图像上的文字转化为计算机可编辑的文字内容,众多的研究人员对相关的技术研究已久,也有不 ...
- OCR技术浅探: 语言模型(4)
由于图像质量等原因,性能再好的识别模型,都会有识别错误的可能性,为了减少识别错误率,可以将识别问题跟统计语言模型结合起来,通过动态规划的方法给出最优的识别结果.这是改进OCR识别效果的重要方法之一. ...
- OCR技术浅探:Python示例(5)
文件说明: 1. image.py——图像处理函数,主要是特征提取: 2. model_training.py——训练CNN单字识别模型(需要较高性能的服务器,最好有GPU加速,否则真是慢得要死): ...
- OCR技术浅探: 光学识别(3)
经过前面的文字定位和文本切割,我们已经能够找出图像中单个文字的区域,接下来可以建立相应的模型对单字进行识别. 模型选择 在模型方面,我们选择了深度学习中的卷积神经网络模型,通过多层卷积神经网络,构建了 ...
- OCR技术浅探 : 文字定位和文本切割(2)
文字定位 经过前面的特征提取,我们已经较好地提取了图像的文本特征,下面进行文字定位. 主要过程分两步: 1.邻近搜索,目的是圈出单行文字: 2.文本切割,目的是将单行文本切割为单字. 邻近搜索 我们可 ...
- OCR技术浅析-无代码篇(1)
图像识别中最贴近我们生活的可能就是 OCR 技术了. OCR 的定义:OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打 ...
- font and face, 浅探Emacs字体选择机制及部分记录
缘起 最近因为仰慕org-mode,从vim迁移到了Emacs.偶然发现org-mode中调出的calendar第一行居然没有对齐,排查一下发现是字体的问题.刚好也想改改Emacs的字体,于是我就开始 ...
随机推荐
- C++ const关键字修饰引用
//const修饰引用的两种用法 #include<iostream> using namespace std; struct Teacher{ ]; int age; }; void S ...
- 27Mybatis_一级缓存的实际应用场景
正式开发,是将mybatis和spring进行整合开发,事务控制在service中. 一个service方法中包括 很多mapper方法调用. service{ //开始执行时,开启事务,创建SqlS ...
- 第二百五十七节,Tornado框架-路由映射,逻辑处理,文件归类配置
Tornado框架-路由映射,逻辑处理,文件归类配置 Tornado框架 Tornado 是 FriendFeed 使用的可扩展的非阻塞式 web 服务器及其相关工具的开源版本.这个 Web 框架看起 ...
- Android studio 添加admob googgle play services
Android studio 添加admob googgle play services MainActivity import com.google.android.gms.ads.AdReques ...
- CImage类提供了GetBits()函数原理及实现
CImage类提供了GetBits()函数来读取数据区,GetBits()函数返回的是图片最后一行第一个像素的地址,网上有人说返回指针的起始位置是不同的,有些图片返回的是左上角像素的地址,有些是左下角 ...
- sqlserver 安全
1.将数据库的用户名和密码加密保存,使用加密传输.2.将数据库里面的用户除了这个用户所有的用户都禁用,把该用户的密码改的很复杂,很难破解那种3.设置数据库的可连接方式(所有的方式的设置).4.删除数据 ...
- Vim相关优化和配置
升级pythonwget https://www.python.org/ftp/python/3.6.5/Python-3.6.5.tgztar -xvf Python-3.6.5.tgzcd Pyt ...
- C语言条件运算符
如果希望获得两个数中最大的一个,可以使用 if 语句,例如: if(a>b){ max = a; }else{ max = b; } 不过,C语言提供了一种更加简单的方法,叫做条件运算符,语法格 ...
- NSUserDefaults设置bool值重启后bool只设置丢失问题
本文转载至 http://blog.csdn.net/cerastes/article/details/38036875 NSUserDefaultsbool同步synchronize无效 今天使 ...
- IDEA破解后无法启动
在网上找了破解IDEA的方法 原文:https://blog.csdn.net/qq_38637558/article/details/78914772 ①到这个地方下载 IntelliJ IDEA ...