hadoop开发setjar方法
屏蔽
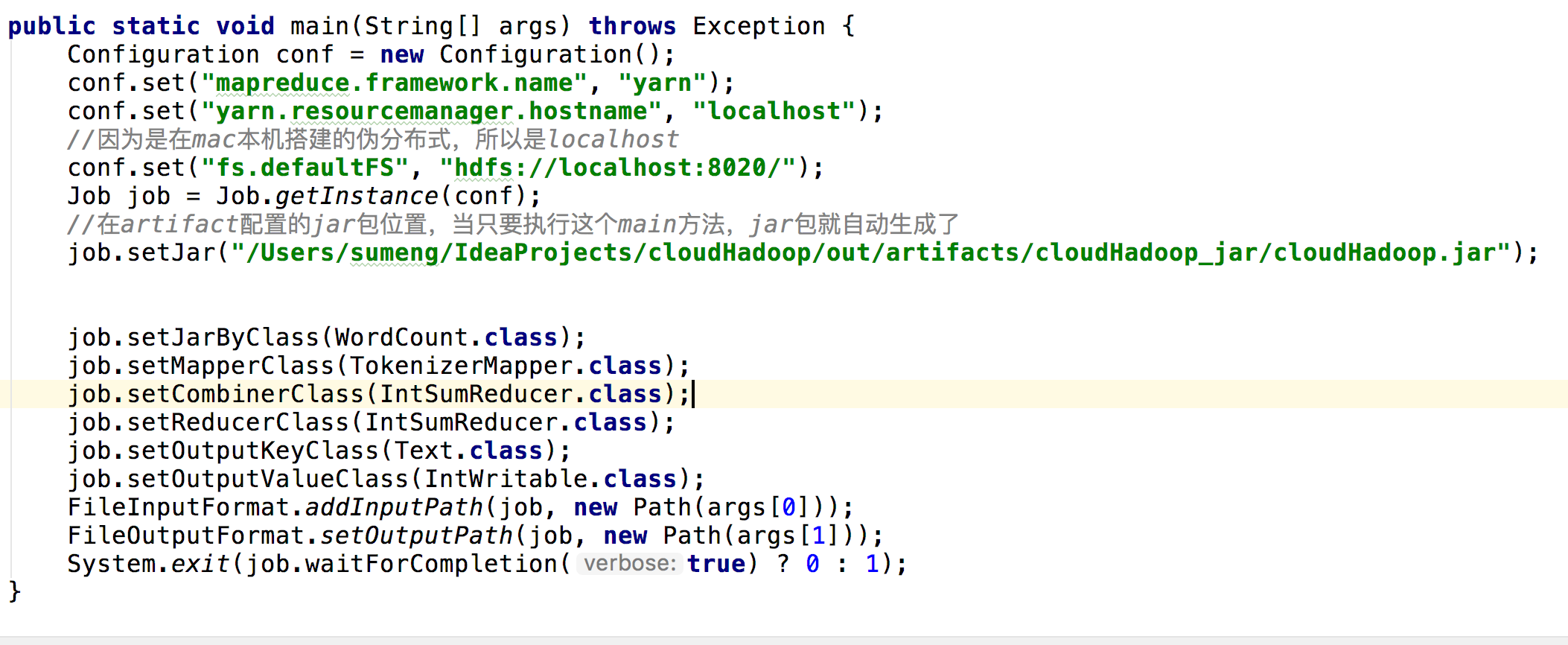
//job.setJar("/Users/sumeng/IdeaProjects/cloudHadoop/out/artifacts/cloudHadoop_jar/cloudHadoop.jar");
job.setJarByClass(WordCount.class);
报错:
Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class WordCount$TokenizerMapper not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:)
at org.apache.hadoop.mapreduce.task.JobContextImpl.getMapperClass(JobContextImpl.java:)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:)
at org.apache.hadoop.mapred.YarnChild$.run(YarnChild.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:)
Caused by: java.lang.ClassNotFoundException: Class WordCount$TokenizerMapper not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:)
... more
屏蔽
job.setJar("/Users/sumeng/IdeaProjects/cloudHadoop/out/artifacts/cloudHadoop_jar/cloudHadoop.jar");
//job.setJarByClass(WordCount.class);
不会报错
//通过Configuration对象获取job对象,该job对象会组织所有的该mapreduce的所有各种组件
Job job = Job.getInstance(conf);
//指定jar包所在路径,本地模式需要这样指定,如果不是本地,则使用setJarByClass指定所在class文件即可
//job.setJarByClass("wordcountJar/wordcount.jar")
job.setJar("wordcountJar/wordcount.jar");
---------------------
作者:夜下探戈
来源:CSDN
原文:https://blog.csdn.net/dudefu011/article/details/79586191
版权声明:本文为博主原创文章,转载请附上博文链接!
可以确定的是,
情况一:如果采用打成jar包,在hadoop集群中通过hadoop jar命令运行,则只需要写job.setJarByClass
情况二:本地idea开发mapreduce程序提交到hadoop集群执行,参考https://blog.csdn.net/dream_an/article/details/84342770
https://www.jianshu.com/p/2c9c22130225也是把jar包设置到了本机
https://blog.csdn.net/shirukai/article/details/81021872讲解了打成jar包的过程
还是不是很明白setjar 与 setJarbyClass 的区别和意义
https://www.codetd.com/article/664330
https://my.oschina.net/zhzhenqin/blog/163158
hadoop开发setjar方法的更多相关文章
- Hadoop开发环境简介(转)
1.Hadoop开发环境简介 1.1 Hadoop集群简介 Java版本:jdk-6u31-linux-i586.bin Linux系统:CentOS6.0 Hadoop版本:hadoop-1.0.0 ...
- 基于Eclipse搭建hadoop开发环境
一.基础环境准备 1.Eclipse 下载地址:http://pan.baidu.com/s/1slArxAP 2.JDK1.8 下载地址:http://pan.baidu.com/s/1i5iNy ...
- Hadoop开发相关问题
总结自己在Hadoop开发中遇到的问题,主要在mapreduce代码执行方面.大部分来自日常代码执行错误的解决方法,还有一些是对Java.Hadoop剖析.对于问题,通过查询stackoverflow ...
- 在ubuntu下使用Eclipse搭建Hadoop开发环境
一.安装准备1.JDK版本:jdk1.7.0(jdk-7-linux-i586.tar.gz)2.hadoop版本:hadoop-1.1.1(hadoop-1.1.1.tar.gz)3.eclipse ...
- Mac OS X上搭建伪分布式CDH版本Hadoop开发环境
最近在研究数据挖掘相关的东西,在本地 Mac 环境搭建了一套伪分布式的 hadoop 开发环境,采用CDH发行版本,省时省心. 参考来源 How-to: Install CDH on Mac OSX ...
- Windows下搭建Spark+Hadoop开发环境
Windows下搭建Spark+Hadoop开发环境需要一些工具支持. 只需要确保您的电脑已装好Java环境,那么就可以开始了. 一. 准备工作 1. 下载Hadoop2.7.1版本(写Spark和H ...
- Ubuntu环境下eclipse的hadoop开发
在安装好hadoop伪分布式后,开始搭建eclipse的hadoop开发环境 我的版本信息如下: Ubuntu 版本 12.10 Hadoop版本 1.2.1 Java版本 1.6.0_31(命令j ...
- Hadoop开发环境搭建
hadoop是一个分布式系统基础架构,由Apache基金会所开发. 用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力高速运算和存储. Hadoop实现了一个分布式文件系统 ...
- 基于Hadoop开发网络云盘系统客户端界面设计初稿
基于Hadoop开发网络云盘系统客户端界面设计初稿 前言: 本文是<基于Hadoop开发网络云盘系统架构设计方案>的第二篇,针对界面原型原本考虑有两个方案:1.类windows模式,文件夹 ...
随机推荐
- bootstrap基础学习八篇
bootstrap辅助类 a.对于文本颜色 以下不同的类展示了不同的文本颜色.如果文本是个链接鼠标移动到文本上会变暗: 类 描述 .text-muted "text-muted" ...
- 多线程编程(三)--创建线程之Thread VS Runnable
前面写过一篇基础的创建多线程的博文: 那么本篇博文主要来对照一下这两种创建线程的差别. 继承Thread类: 还拿上篇博客的样例来说: 四个线程各自卖各自的票,说明四个线程之间没有共享,是独立的线程. ...
- request Dispatch
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletExcepti ...
- TArray<uint8>转FString
void ARamaUDPReceiver::Recv(const FArrayReaderPtr& ArrayReaderPtr, const FIPv4Endpoint& EndP ...
- NData转化
NSdata 与 NSString,Byte数组,UIImage 的相互转换---ios开发 Objective-C 1. NSData 与 NSStringNSData-> NSStringN ...
- Eclipse 安装更多版本SDK
暂时记下,实在没时间测试了... 安卓应用开发之查eclipse版本号和添加ADT.SDK https://jingyan.baidu.com/article/b0b63dbfc5f49b4a4830 ...
- jfinal如何调用存储过程?
存储过程用一下 Db.execute(ICallback) 这个方法,在其中用一下:connection.prepareCall(sql).execute();就可以调用存储过程了,并且还可以自由控制 ...
- LeetCode-Lowest Common Ancestor of a Binary Tre
Given a binary tree, find the lowest common ancestor (LCA) of two given nodes in the tree. According ...
- LeetCode 笔记系列九 Search in Rotated Sorted Array
题目: Suppose a sorted array is rotated at some pivot unknown to you beforehand. (i.e., 0 1 2 4 5 6 7 ...
- 160601、Websocet服务端实现
今天是六一儿童节,祝愿小朋友们节日快乐!大朋友们事事顺心! Websocet服务端实现 WebSocketConfig.Java ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ...