Hibernate学习9—检索策略
本章,采用Class和Student —— 1 对 多的关系;
Student.java:
package com.cy.model;
public class Student {
private int id;
private String name;
private Class c;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Class getC() {
return c;
}
public void setC(Class c) {
this.c = c;
}
}
Class.java:
package com.cy.model; import java.util.HashSet;
import java.util.Set; public class Class {
private int id;
private String name;
private Set<Student> students = new HashSet<Student>(); public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Set<Student> getStudents() {
return students;
}
public void setStudents(Set<Student> students) {
this.students = students;
} }
Student.hbm.xml:
<hibernate-mapping package="com.cy.model">
<class name="Student" table="t_student">
<id name="id" column="stuId">
<generator class="native"></generator>
</id>
<property name="name" column="stuName"></property>
<many-to-one name="c" column="classId" class="com.cy.model.Class" cascade="save-update" lazy="proxy"></many-to-one>
</class>
</hibernate-mapping>
Class.hbm.xml:
<hibernate-mapping package="com.cy.model">
<class name="Class" table="t_class">
<id name="id" column="classId">
<generator class="native"></generator>
</id>
<property name="name" column="className"></property>
<set name="students" cascade="save-update" inverse="true" lazy="false" batch-size="3" fetch="join">
<key column="classId"></key>
<one-to-many class="com.cy.model.Student" />
</set>
</class>
</hibernate-mapping>
第一节:检索策略属性Lazy

Lazy:true:默认延迟检索:用到才加载
@Test
public void testLazy1(){
//因为在class.hbm中set端,一对多,配置的是lazy=true,加载class的时候,默认是不加载学生的。
Class c = (Class) session.get(Class.class, 1); //等到什么时候会查询学生数据?——等到他用的时候
//等到用到的时候才去检索,这就是延迟检索
Set<Student> students = c.getStudents(); System.out.println(students.size()); // Iterator it = students.iterator(); }


@Test
public void testLazy2(){
//many to one端,默认lazy - proxy。取出的student中的Class是一个代理类。没有实际数据
Student student = (Student) session.get(Student.class, 1); //等到用到class的名字的时候,代理类才去发出sql查询数据。
student.getC().getName();
}
第二节:检索策略属性batch-size
1,批量延迟检索;
对应的class.hbm配置:lazy="true" batch-size="3"
/**
* 批量延迟检索,lazy=true
*/
@Test
public void testBatch1(){
List<Class> classList = session.createQuery("from Class").list();
Iterator<Class> it = classList.iterator();
Class c1 = it.next();
Class c2 = it.next();
Class c3 = it.next();
c1.getStudents().iterator();
c2.getStudents().iterator();
c3.getStudents().iterator(); //先取出所有class,因为set students端配置了lazy=false
//等到c1、c2、c3用到student的时候,才去查找。每个发出一条sql语句。
//假如classList很多很多的话,遍历每个class,然后取每个class下面的students,每个都发出一条sql,这样效率就很低了。
//所以,引入了batch-size,批量检索。batch-size的值为批量的值 //在class.hbm. set studens端,配置batch-size=3,发出的sql就是这样了:
/**
* SELECT
t_student.classId ,
t_student.stuId ,
t_student.stuName
FROM t_student
WHERE t_student.classId IN (1, 2, 3)
*/
}
而未设置批量检索batch-size,发出的sql是下面这样,一条一条的查:

设置了批量检索,batch-size=3后,查询student信息时,一次查3条;
2,批量立即检索;
@Test
public void testBatch2(){
List<Class> classList = session.createQuery("from Class").list();
//这里class.hbm.xml set students中配置lazy=false,batch-size=3,就是批量立即检索了.
//发出的批量sql和上面一样。 }
第三节:检索策略属性Fetch
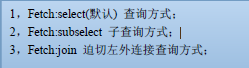
@Test
public void testFetch1(){
List<Class> classList = session.createQuery("from Class").list();
Iterator<Class> it = classList.iterator();
Class c1 = it.next();
Class c2 = it.next();
Class c3 = it.next();
c1.getStudents().iterator();
c2.getStudents().iterator();
c3.getStudents().iterator();
/**
* class.hbm set students 配置fetch="select",是默认的,发出的sql:
* SELECT
t_student.classId ,
t_student.stuId ,
t_student.stuName
FROM t_student
WHERE t_student.classId IN (1, 2, 3) 现在改为fetch=subselect:sql变成了:
SELECT
t_student.classId ,
t_student.stuId ,
t_student.stuName
FROM t_student
WHERE t_student.classId IN
(SELECT classId FROM t_class )
*
*/
}
fetch:join:
@Test
public void testFetch2(){
Class c = (Class) session.get(Class.class, 1);
/**
* 这里class.hbm配置:<set name="students" lazy="false" fetch="join">
* 查询班级的时候,把属于这个班级的学生也一起查出来,这里fetch=join,sql中left outer join:
* 发出的sql:
* SELECT
t_class.classId,
t_class.className,
t_student.stuId,
t_student.stuName,
t_student.classId
FROM t_class
LEFT OUTER JOIN t_student ON t_class.classId = t_student.classId
WHERE t_class.classId = 1 * 可以看到只发出一条sql语句了,t_class表和t_student表关联,将class信息和student信息一起取了出来;
*
* 而如果fetch为select,是先取班级信息;再取student信息
*/
}
Hibernate学习9—检索策略的更多相关文章
- Hibernate学习之检索策略
一.类级别的检索策略 类级别可选的检索策略包括立即检索和延迟检索, 默认为延迟检索 –立即检索: 立即加载检索方法指定的对象 –延迟检索: 延迟加载检索方法指定的对象,在使用具体的属性时,再进行加载 ...
- Hibernate学习总汇
Hibernate的基础知识 什么是框架? 什么是Hibernate框架? |--1.应用在javaee三层结构中的dao层 |--2.在dao层里面做对数据库进行crud操作,使用hibernate ...
- [原创]java WEB学习笔记88:Hibernate学习之路-- -Hibernate检索策略(立即检索,延迟检索,迫切左外连接检索)
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- [原创]java WEB学习笔记91:Hibernate学习之路-- -HQL 迫切左外连接,左外连接,迫切内连接,内连接,关联级别运行时的检索策略 比较。理论,在于理解
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- Hibernate学习(八)———— Hibernate检索策略(类级别,关联级别,批量检索)详解
序言 很多看起来很难的东西其实并不难,关键是看自己是否花费了时间和精力去看,如果一个东西你能看得懂,同样的,别人也能看得懂,体现不出和别人的差距,所以当你觉得自己看了很多书或者学了很多东西的时候,你要 ...
- Hibernate —— 检索策略
一.Hibernate 的检索策略本质上是为了优化 Hibernate 性能. 二.Hibernate 检索策略包括类级别的检索策略.和关联级别的检索策略(<set> 元素) 三.类级别的 ...
- hibernate学习(6)——加载策略(优化)
1. 检索方式 1 立即检索:立即查询,在执行查询语句时,立即查询所有的数据. 2 延迟检索:延迟查询,在执行查询语句之后,在需要时在查询.(懒加载) 2. 检查策略 1 类级别检索:当前的类的 ...
- hibernate(八) Hibernate检索策略(类级别,关联级别,批量检索)详解
序言 很多看起来很难的东西其实并不难,关键是看自己是否花费了时间和精力去看,如果一个东西你能看得懂,同样的,别人也能看得懂,体现不出和别人的差距,所以当你觉得自己看了很多书或者学了很多东西的时候,你要 ...
- 攻城狮在路上(壹) Hibernate(十二)--- Hibernate的检索策略
本文依旧以Customer类和Order类进行说明.一.引言: Hibernate检索Customer对象时立即检索与之关联的Order对象,这种检索策略为立即检索策略.立即检索策略存在两大不足: A ...
随机推荐
- C++11_Type Traits
版权声明:本文为博主原创文章,未经博主允许不得转载. 识别变量的type id,返回true或false,举一个简单使用的例子 template <typename T> void typ ...
- 为什么叫金拱门- golden arch
不要再纠结为什么叫这么难理解的名字了.因为从golden arch直译过来的撒.金色的拱门.就叫金拱门咯. 关于M的商标的历史来源如下: "McDonald's logo" red ...
- 【跟着stackoverflow学Pandas】How to iterate over rows in a DataFrame in Pandas-DataFrame按行迭代
最近做一个系列博客,跟着stackoverflow学Pandas. 以 pandas作为关键词,在stackoverflow中进行搜索,随后安照 votes 数目进行排序: https://stack ...
- EasyPlayerPro安卓流媒体播放器实现Android H.265硬解码流程
本文转自EasyDarwin团队成员John的博客:http://blog.csdn.net/jyt0551/article/details/74502627 H.265编码算法作为新一代视频编码标准 ...
- Android内存优化(三)避免可控的内存泄漏
相关文章 Android性能优化系列 Java虚拟机系列 前言 内存泄漏向来都是内存优化的重点,它如同幽灵一般存于我们的应用当中,有时它不会现身,但一旦现身就会让你头疼不已.因此,如何避免.发现和解决 ...
- gulp使用 实现文件修改实时刷新
gulp例子:https://github.com/Aquarius1993/gulpDemo 淘宝镜像:$ npm install -g cnpm --registry=https://regist ...
- python2 之 pyh2
1.功能 pyh作爲基於python的簡易html生成庫,收到了廣大python愛好者(比如說我,當然其他人沒有調查過)的深切喜愛. 簡潔的行文風格繼承了python一貫的作風,可以讓你用簡單的Pyt ...
- 实战:向GitHub提交代码时触发Jenkins自动构建
当我们提交代码到GitHub后,可以在Jenkins上执行构建,但是每次都要动手去执行略显麻烦,今天我们就来实战Jenkins的自动构建功能,每次提交代码到GitHub后,Jenkins会进行自动构建 ...
- Failed to instantiate the default view controller for UIMainStoryboardFile 'Main' - perhaps the designated entry point is not set?
- SPOJ Favorite Dice(数学期望)
BuggyD loves to carry his favorite die around. Perhaps you wonder why it's his favorite? Well, his d ...