Hadoop序列化与Writable接口(一)
Hadoop序列化与Writable接口(一)
序列化
序列化(serialization)是指将结构化的对象转化为字节流,以便在网络上传输或者写入到硬盘进行永久存储;相对的反序列化(deserialization)是指将字节流转回到结构化对象的过程。
在分布式系统中进程将对象序列化为字节流,通过网络传输到另一进程,另一进程接收到字节流,通过反序列化转回到结构化对象,以达到进程间通信。在Hadoop中,Mapper,Combiner,Reducer等阶段之间的通信都需要使用序列化与反序列化技术。举例来说,Mapper产生的中间结果(<key: value1, value2...>)需要写入到本地硬盘,这是序列化过程(将结构化对象转化为字节流,并写入硬盘),而Reducer阶段读取Mapper的中间结果的过程则是一个反序列化过程(读取硬盘上存储的字节流文件,并转回为结构化对象),需要注意的是,能够在网络上传输的只能是字节流,Mapper的中间结果在不同主机间洗牌时,对象将经历序列化和反序列化两个过程。
序列化是Hadoop核心的一部分,在Hadoop中,位于org.apache.hadoop.io包中的Writable接口是Hadoop序列化格式的实现。
Writable接口
Hadoop Writable接口是基于DataInput和DataOutput实现的序列化协议,紧凑(高效使用存储空间),快速(读写数据、序列化与反序列化的开销小)。Hadoop中的键(key)和值(value)必须是实现了Writable接口的对象(键还必须实现WritableComparable,以便进行排序)。
以下是Hadoop(使用的是Hadoop 1.1.2)中Writable接口的声明:
1 |
|
Writable类
Hadoop自身提供了多种具体的Writable类,包含了常见的Java基本类型(boolean、byte、short、int、float、long和double等)和集合类型(BytesWritable、ArrayWritable和MapWritable等)。这些类型都位于org.apache.hadoop.io包中。
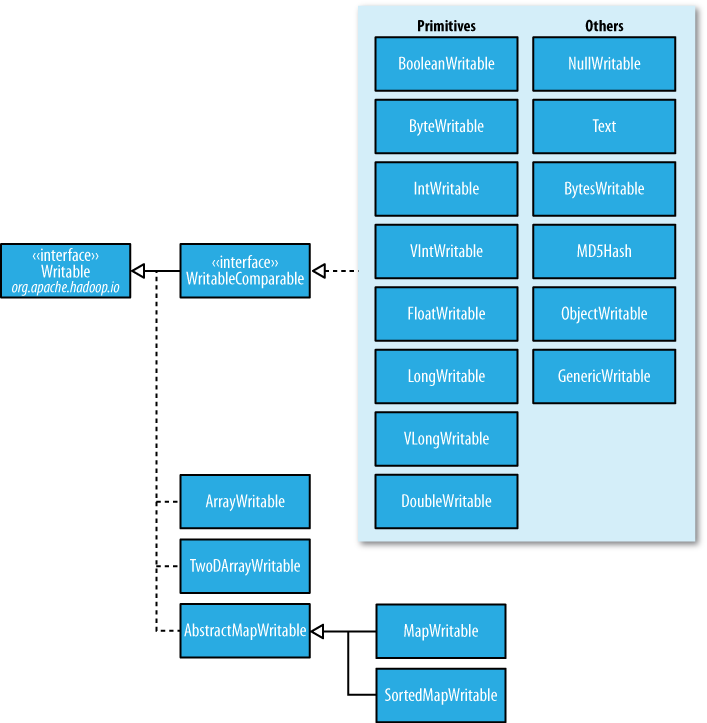
(图片来源:safaribooksonline.com)
定制Writable类
虽然Hadoop内建了多种Writable类提供用户选择,Hadoop对Java基本类型的包装Writable类实现的RawComparable接口,使得这些对象不需要反序列化过程,便可以在字节流层面进行排序,从而大大缩短了比较的时间开销,但是当我们需要更加复杂的对象时,Hadoop的内建Writable类就不能满足我们的需求了(需要注意的是Hadoop提供的Writable集合类型并没有实现RawComparable接口,因此也不满足我们的需要),这时我们就需要定制自己的Writable类,特别将其作为键(key)的时候更应该如此,以求达到更高效的存储和快速的比较。
下面的实例展示了如何定制一个Writable类,一个定制的Writable类首先必须实现Writable或者WritableComparable接口,然后为定制的Writable类编写write(DataOutput out)和readFields(DataInput in)方法,来控制定制的Writable类如何转化为字节流(write方法)和如何从字节流转回为Writable对象。
1 |
|
未完待续,下一篇中将介绍Writable对象序列化为字节流时占用的字节长度以及其字节序列的构成。
参考资料
Tom White, Hadoop: The Definitive Guide, 3rd Edition
---To Be Continued---
Hadoop序列化与Writable接口(一)的更多相关文章
- Hadoop序列化与Writable接口(二)
Hadoop序列化与Writable接口(二) 上一篇文章Hadoop序列化与Writable接口(一)介绍了Hadoop序列化,Hadoop Writable接口以及如何定制自己的Writable类 ...
- Hadoop阅读笔记(六)——洞悉Hadoop序列化机制Writable
酒,是个好东西,前提要适量.今天参加了公司的年会,主题就是吃.喝.吹,除了那些天生话唠外,大部分人需要加点酒来作催化剂,让一个平时沉默寡言的码农也能成为一个喷子!在大家推杯换盏之际,难免一些画面浮现脑 ...
- hadoop中的序列化与Writable接口
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable-interface.html,转载请注明源地址. 简介 序列化和反序列化就是结构化对象 ...
- Hadoop中序列化与Writable接口
学习笔记,整理自<Hadoop权威指南 第3版> 一.序列化 序列化:序列化是将 内存 中的结构化数据 转化为 能在网络上传输 或 磁盘中进行永久保存的二进制流的过程:反序列化:序列化的逆 ...
- Hadoop序列化
遗留问题: Hadoop序列化可以复用对象,是在哪里复用的? 介绍Hadoop序列化机制 Hadoop序列化机制详解 Hadoop序列化的核心 Hadoop序列化的比较接口 ObjectWrita ...
- Hadoop基础-序列化与反序列化(实现Writable接口)
Hadoop基础-序列化与反序列化(实现Writable接口) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.序列化简介 1>.什么是序列化 序列化也称串行化,是将结构化 ...
- Hadoop Serialization hadoop序列化详解(最新版) (1)【java和hadoop序列化比较和writable接口】
初学java的人肯定对java序列化记忆犹新.最开始很多人并不会一下子理解序列化的意义所在.这样子是因为很多人还是对java最底层的特性不是特别理解,当你经验丰富,对java理解更加深刻之后,你就会发 ...
- 为什么hadoop中用到的序列化不是java的serilaziable接口去序列化而是使用Writable序列化框架
继上一个模块之后,此次分析的内容是来到了Hadoop IO相关的模块了,IO系统的模块可谓是一个比较大的模块,在Hadoop Common中的io,主要包括2个大的子模块构成,1个是以Writable ...
- eclipse 提交作业到JobTracker Hadoop的数据类型要求必须实现Writable接口
问:在eclipse中的写的代码如何提交作业到JobTracker中的哪?答:(1)在eclipse中调用的job.waitForCompletion(true)实际上执行如下方法 connect() ...
随机推荐
- 4666 Hyperspace stl
当时自己做的时候没有这么想,想的是每个象限去找一个无穷值来作为比较点.但是很麻烦 代码: #include <stdio.h> #include <string.h> #inc ...
- ansible入门三(Ansible的基础元素和YAML介绍)
Ansible的基础元素和YAML介绍 本节内容: YAML Ansible常用的数据类型 Ansible基础元素 一.YAML 1. YAML介绍 YAML是一个可读性高的用来表达资料序列的格式 ...
- Spark安装和简单示例
spark的安装 先到官网下载安装包 注意第二项要选择和自己hadoop版本相匹配的spark版本,然后在第4项点击下载.若无图形界面,可用windows系统下载完成后传送到centos中. 本例中安 ...
- 让nodejs在iis上运行
node在IIS上运行的好处: Tomasz的回答是我见过最棒的: 使用iisnode模块在IIS中托管node.js应用程序来取代自托管node.exe进程的优势在于: · 进程管理. Iisnod ...
- java与mysql时间类型对应的问题
项目中遇到一个问题,从后台给出的json字符串中取得的时间,之后通过方法转换成 yyyy-MM-dd hh:mm:ss 的时候,转换后的得到的竟然是1969年...之后排查问题: 发现了在mayba ...
- 6个变态的C语言程序
转载自 陈浩 coolshell.cn 下面的六个程序片段主要完成这些事情: 输出Hello, World 混乱C语言的源代码 下面的所有程序都可以在GCC下编译通过,只有最后一个需要动用C++的编译 ...
- mac下iterm2快捷方式
mac下iterm2,一些技巧,做个记录,大部分参考别人的加上自己的补充: 其中option + 左右键来跳转单词还是有问题,结果变为[D[C,等我摸索好了再来补充. 窗口 新建tab:⌘ + t 切 ...
- [置顶]
普通程序员如何入门AI
毫无疑问,人工智能是目前整个互联网领域最火的行业,随着AlphaGo战胜世界围棋冠军,以及各种无人驾驶.智能家居项目的布道,人们已经意识到了AI就是下一个风口.当然,程序员是我见过对于新技术最敏感的一 ...
- Postfix常用命令和邮件队列管理(queue)
本文主要介绍一下postfix的常用命令及邮件队列的管理: Postfix有以下四种邮件队列,均由管理队列的进程统一进行管理: maildrop:本地邮件放置在maildrop中,同时也被拷贝到inc ...
- autoburn eMMC hacking
#!/bin/sh # autoburn eMMC hacking # 说明: # 看一下富林的自动烧录的执行脚本原理. # # -- 深圳 龙华樟坑村 曾剑锋 # 创建sd卡挂载目录 if [ ! ...