Python基础——爬虫以及简单的数据分析
目标:使用Python编写爬虫,获取链家青岛站的房产信息,然后对爬取的房产信息进行分析。
环境:win10+python3.8+pycharm
Python库:
import requests
import bs4
from bs4 import BeautifulSoup
import lxml
import re
import xlrd
import xlwt
import xlutils.copy
import time
目标分析:
1、编写爬虫爬取链家青岛站的房产信息
①分析目标链接
第一页:https://qd.fang.lianjia.com/loupan/pg/pg1
第二页:https://qd.fang.lianjia.com/loupan/pg/pg2
由上面的链接可以看出来,不同网页是使用最后的pgx来进行变化的
所以将链接分为两部分,使用字符串拼接获得所有的房产网页链接
WebDiZhi = []
for i in range(1,85):
UrlHTML = Url + str(i)
WebDiZhi.append(UrlHTML)
使用遍历获得所有的链接并保存为列表
②分析网页结构
#获取目标网页的html代码并进行解析
Xu = 0
Shuliang = len(WebDiZhi)
while Xu in range(Shuliang):#循环整个列表 Web = requests.get(WebDiZhi[Xu])
WebText = Web.text #第一步、粗筛选目标信息所在的html代码,去除大部分无效信息代码
soup_One = BeautifulSoup(WebText,'html.parser')
XinXi_One = soup_One.find_all(class_="resblock-list-wrapper") #第二步、进一步筛选目标信息所在html代码,去除无效信息代码
soup_Two = BeautifulSoup(str(XinXi_One),'lxml')
XinXi_Two = soup_Two.find_all(class_="resblock-desc-wrapper")
通过两步简单的筛选将房产信息所对应的html代码筛选出来
方便进一步分析html网页标签获取不同的房产信息
③针对不同的房产信息定义不同的函数,通过调用函数来获取不同的房产信息并保存到目标文件中
print("-----------------开始写入第{}页-------------".format(Xu))
Name = GetName(XinXi_Two) # 获取小区名称
Write_File(Name, 0,Xu)
print("---------小区名称写入成功---------")
time.sleep(3) #延时
Nature = NatureHouse(XinXi_Two) # 获取小区住宅性质(住宅、商业性)
Write_File(Nature, 1,Xu)
print("---------小区性质写入成功---------")
time.sleep(3)
Status = StatusHouse(XinXi_Two) # 获取小区状态(在售)
Write_File(Status, 2,Xu)
print("---------小区状态写入成功---------")
time.sleep(3)
Address = AddressHouse(XinXi_Two) # 获取小区地址
Write_File(Address, 3,Xu)
print("---------小区地址写入成功---------")
time.sleep(3)
Area = AreaHouse(XinXi_Two) # 获取小区房屋面积
Write_File(Area, 4,Xu)
print("---------小区面积写入成功---------")
time.sleep(3)
Average = AveragePriceHouse(XinXi_Two) # 均价
Write_File(Average, 5,Xu)
print("---------小区均价写入成功---------")
time.sleep(3)
Total = TotalPriceHouse(XinXi_Two) # 总价
Write_File(Total, 6,Xu)
print("---------小区总价写入成功---------")
time.sleep(3)
各房产信息函数
def Write_File(Data, lei,Hang):
data = xlrd.open_workbook(r"F:\实例\Python实例\爬虫\111.xls")
ws = xlutils.copy.copy(data)
table = ws.get_sheet(0)
Shu = Hang * 10
for i in range(len(Data)):
table.write(i + 1 + Shu, lei, Data[i])
print("----第{}项写入成功----".format(i))
ws.save(r"F:\实例\Python实例\爬虫\111.xls") def GetName(XinXi):
"""
@param XinXi: 传入GetHTML函数第二步中筛选出的div标签下的html代码以及目标信息
@return: 返回小区名称,列表类型
"""
Nmae_list = []
# 获取小区名称
Obtain_Name_One = BeautifulSoup(str(XinXi), 'lxml')
Name_One = Obtain_Name_One.findAll(class_="name")
for i in Name_One:
Get_A = BeautifulSoup(str(i), 'lxml')
Nmae_list.append(Get_A.string)
return Nmae_list """
代码以及目标信息均已获取,通过不同函数将html代码在对应函数中逐一进行解析获取函数对应信息并保存即可
以下为部分函数,其他函数未定义 """
def NatureHouse(Nature):
"""房屋性质"""
Nature_list = []
Obtain_Nature = BeautifulSoup(str(Nature), 'lxml')
Nature_one = Obtain_Nature.find_all(class_='resblock-type')
for i in Nature_one:
Get_Span = BeautifulSoup(str(i), 'lxml')
Nature_list.append(Get_Span.string)
return Nature_list def StatusHouse(Status):
"""房屋状态"""
Status_list = []
Obtain_Nature = BeautifulSoup(str(Status), 'lxml')
Status_one = Obtain_Nature.find_all(class_='sale-status')
for i in Status_one:
Get_Span = BeautifulSoup(str(i), 'lxml')
Status_list.append(Get_Span.string)
return Status_list def AddressHouse(Area):
""" @param Area:传入GetHTML函数第二步中筛选出的div标签下的html代码以及目标信息
@return:
Analysis_Label_xxx:分析标签,xxx:代表第几次分析
Target_Information_xxx:目标信息,xxx:代表第几个信息部分,总共分为两部分,以及一个整体信息存储列表Target_Information_list
"""
#获取标签
Target_Information_list = []
Analysis_Label_One = BeautifulSoup(str(Area), 'lxml')
# 获取div标签,calss=resblock-location
Get_label_One = Analysis_Label_One.find_all(class_='resblock-location')
#解析标签并获得span标签
Analysis_Label_Two = BeautifulSoup(str(Get_label_One), 'lxml')
Get_label_Two = Analysis_Label_Two.find_all(name='span') #获取span标签里面的文字内容并保存在列表内 #第一个
Target_Information_One = []
for i in Get_label_Two:
#使用正则表达式取出内部信息并保存在列表中
Information_Str = re.sub(r'<.*?>','',str(i))
Target_Information_One.append(Information_Str)
#将列表内相同小区的地址进行合并,使用循环嵌套获取内容、合并最后保存在列表内
i = 1
a = 0 #第二个,第二个信息是在第一个信息的基础上合并列表内的元素得来
Target_Information_Two = []
while i <= len(Target_Information_One):
while a < i:
#将Target_Information_One中每两项进行合并
Information_Two = Target_Information_One[a]
Information_One = Target_Information_One[i]
Information_Three = Information_One + Information_Two Target_Information_Two.append(Information_Three)
a += 2
i += 2 #获取详细地址 #第三个
Target_Information_Three = []
Span_html_One = Analysis_Label_Two.find_all(name='a')
for c in Span_html_One:
Area_Str_1 = re.sub(r'<.*?>', '', str(c))
Target_Information_Three.append(Area_Str_1) # 将Target_Information_Two和Target_Information_Three两个列表中的各项元素分别进行合并并保存在Area_list列表中
A = min(len(Target_Information_Two),len(Target_Information_Three))
for i in range(A):
Target_Information_list.append(Target_Information_Two[i] + Target_Information_Three[i]) return Target_Information_list def AreaHouse(Area):
""" @param Area: 传入GetHTML函数第二步中筛选出的div标签下的html代码以及目标信息
@return: 返回房屋房间数量以及房屋总面积
"""
Area_list = []
#筛选目标信息的父标签
Obtain_Area_One = BeautifulSoup(str(Area), 'lxml')
Area_one = Obtain_Area_One.find_all(class_='resblock-room') #通过正则表达式去除多余的html标签信息
Get_Area_One = []
for c in Area_one:
Area_Str_1 = re.sub(r'<.*?>', '', str(c))
Get_Area_One.append(Area_Str_1) #通过正则表达式去除多余的换行符
Get_Area_Two = []
for i in Get_Area_One:
Area_Str_2 = re.sub(r'\s+','',str(i))
Get_Area_Two.append(Area_Str_2) #开始获取房屋总面积
Obtain_Area_Two = BeautifulSoup(str(Area),'lxml')
Area_two = Obtain_Area_Two.find_all(class_='resblock-area')
#通过正则表达式去除多余的html标签信息
Get_Area_Three = []
for a in Area_two:
Area_Str_3 = re.sub(r'<.*?>', '', str(a))
Get_Area_Three.append(Area_Str_3) # 通过正则表达式去除多余的换行符
Get_Area_Four = []
for r in Get_Area_Three:
Area_Str_4 = re.sub(r'\s+', '', str(r))
Get_Area_Four.append(Area_Str_4) # 将Get_Area_Two和Get_Area_Four两个列表中的各项元素分别进行合并并保存在Area_list列表中
A = min(len(Get_Area_Two), len(Get_Area_Four))
for i in range(A):
Area_list.append(Get_Area_Two[i] + Get_Area_Four[i]) return Area_list def AveragePriceHouse(Average):
"""
房屋均价
@param Average:
@return:
"""
Average_list = []
Obtain_Average = BeautifulSoup(str(Average), 'lxml')
Average_one = Obtain_Average.find_all(class_='number')
for i in Average_one:
Get_Span = BeautifulSoup(str(i), 'lxml')
Average_list.append(Get_Span.string) return Average_list def TotalPriceHouse(Total):
"""
房屋总价 @param Total:
@return:
"""
Total_list = []
Obtain_Total = BeautifulSoup(str(Total), 'lxml')
Total_one = Obtain_Total.fjind_all(class_='second')
for i in Total_one:
Get_Span = BeautifulSoup(str(i), 'lxml')
Get_Span_one = Get_Span.string
Get_Span_two = Get_Span_one.lstrip('总价')
Total_list.append(Get_Span_two) return Total_list
创建存储文件
def Create_File():
name = ['名称','性质','状态','地址','面积','均价','总价',]
workbook = xlwt.Workbook(encoding='utf-8', style_compression=0)
sheet = workbook.add_sheet('shett1', cell_overwrite_ok=True)
for i in range(len(name)):
sheet.write(0, i, name[i])
workbook.save(r'F:\实例\Python实例\爬虫\111.xls')
print("文件创建成功")
2、简单的数据分析并使用饼状图表示房产均价比例
所用到的库:
import pandas as pd
import xlrd
import re
import xlutils.copy
import matplotlib.pyplot as plt
①数据清洗----删除空值行
def ExceptNull():
"""
数据清洗第一步:去除表中空值
@param df: 传入读取的xls表格数据
@return: 保存数据后返回,
"""
df = pd.DataFrame(pd.read_excel(r'F:\实例\Python实例\爬虫\111.xls'))
#查找面积列空值,使用99999填充空缺值后删除所在行
print(df['面积'].isnull().value_counts())
df["面积"] = df["面积"].fillna('')
NullKey = df[(df.面积 == '')].index.tolist()
print(NullKey)
df = df.drop(NullKey)
print("*"*30)
print(df['面积'].isnull().value_counts()) print("*"*30)
#查找总价列空值,使用99999填充空缺值后删除所在行
print(df['总价'].isnull().value_counts())
df["总价"] = df["总价"].fillna('')
NullKey1 = df[(df.总价 == '')].index.tolist()
print(NullKey1)
df = df.drop(NullKey1)
print("*"*30)
print(df['总价'].isnull().value_counts())
df.to_excel('111.xls',index=False,encoding='uf-8') print("修改后数据保存成功")
②数据预处理----将数据转换成易处理格式
def LeiChuli():
Data = xlrd.open_workbook(r"F:\实例\Python实例\爬虫\111.xls")
ws = xlutils.copy.copy(Data)
Table = Data.sheet_by_name("Sheet1")
Nrows = Table.nrows
list_A = []
for i in range(1,Nrows):
A = Table.cell_value(i,6)
A_Str = re.sub('/套','',A,Nrows)
list_A.append(A_Str)
Replace = []
for i in range(len(list_A)):
Price_Str = list_A[i]
Last_Str = Price_Str[-1]
if Last_Str == '万':
A_Str = re.sub('万', '', Price_Str, 1)
Replace.append(A_Str)
else:
Replace.append(Price_Str)
table = ws.get_sheet(0)
for i in range(len(Replace)):
table.write(i + 1, 6, Replace[i])
print("------>开始写入修改后数据<------")
print("---->第{}项写入成功<----".format(i))
ws.save(r"F:\实例\Python实例\爬虫\111.xls")
print("------>数据写入完成<------")
③对处理后的数据进行分析并绘制饼状图
def Data_Analysis_One():
Data = xlrd.open_workbook(r"F:\实例\Python实例\爬虫\111.xls")
ws = xlutils.copy.copy(Data)
Table = Data.sheet_by_name("Sheet1")
Nrows = Table.nrows
a,b,c,d,e,f = 0,0,0,0,0,0 for i in range(1, Nrows):
A = Table.cell_value(i, 5)
if A == "价格待定":
f += 1
else:
if int(A) <= 5000:
a += 1
elif int(A) <= 10000:
b += 1
elif int(A) <= 15000:
c += 1
elif int(A) <= 20000:
d += 1
else:
e += 1 # 开始准备绘制饼状图 #价格区间数据准备
sizes = []
Percentage_a = (a / Nrows) * 100
sizes.append(int(Percentage_a))
Percentage_b = (b / Nrows) * 100
sizes.append(int(Percentage_b))
Percentage_c = (c / Nrows) * 100
sizes.append(int(Percentage_c))
Percentage_d = (d / Nrows) * 100
sizes.append(int(Percentage_d))
Percentage_e = (e / Nrows) * 100
sizes.append(int(Percentage_e))
Percentage_f = (f / Nrows) * 100
sizes.append(int(Percentage_f))
#设置占比说明
labels = '0-5000','5001-10000','10001-15000','15001-20000','20000-','Undetermined'
explode = (0,0,0.1,0,0,0)
#开始绘制
plt.pie(sizes,explode=explode,labels=labels,autopct='%1.1f%%',shadow=True,startangle=90)
plt.axis('equal')
plt.show()
ws.save(r"F:\实例\Python实例\爬虫\111.xls")
最后附上效果图。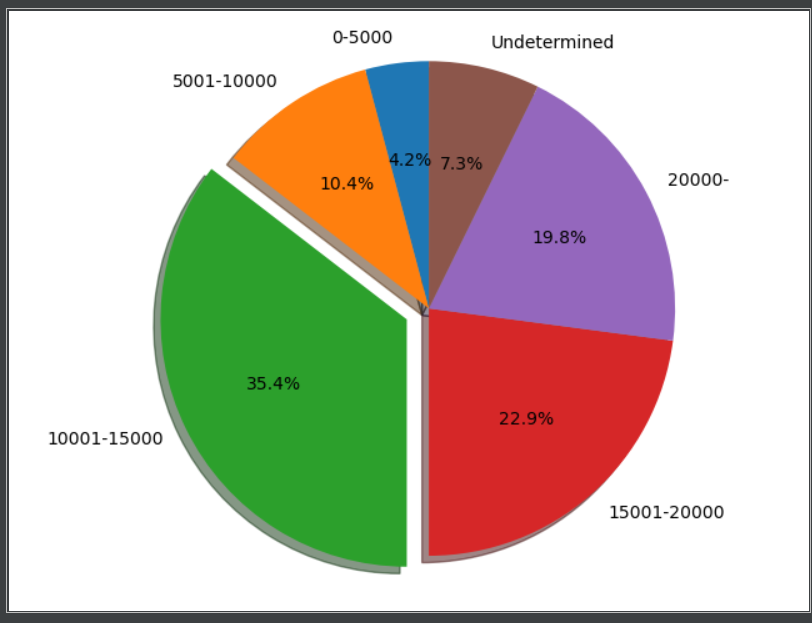
最后附上完整代码:
1、爬虫代码
import requests
import bs4
from bs4 import BeautifulSoup
import lxml
import re
# import LianJia_QD_DataProcessing
import xlrd
import xlwt
import xlutils.copy
import time def GetHTML(Url):
"""
1、通过传入url组合,获取所有网页地址的url
2、获取目标网页的html代码并进行解析
3、解析后将目标信息分别写入字典类型的变量并返回 @param Url: 目标网址的不变链接
@return: 网站目标信息 """ #通过传入url组合,获取所有网页地址的url
WebDiZhi = []
for i in range(1,85):
UrlHTML = Url + str(i)
WebDiZhi.append(UrlHTML) print("共计{}页".format(len(WebDiZhi)))
# Create_File()
#获取目标网页的html代码并进行解析
Xu = 0
Shuliang = len(WebDiZhi)
while Xu in range(Shuliang):#range(len(WebDiZhi))--循环整个列表 Web = requests.get(WebDiZhi[Xu])
WebText = Web.text #第一步、粗筛选目标信息所在的html代码,去除大部分无效信息代码
soup_One = BeautifulSoup(WebText,'html.parser')
XinXi_One = soup_One.find_all(class_="resblock-list-wrapper") #第二步、进一步筛选目标信息所在html代码,去除无效信息代码
soup_Two = BeautifulSoup(str(XinXi_One),'lxml')
XinXi_Two = soup_Two.find_all(class_="resblock-desc-wrapper") print("-----------------第{}页爬取成功------------".format(Xu))
# Html.append(XinXi_Two)
# time.sleep(1)
# return Html print("-----------------开始写入第{}页-------------".format(Xu))
Name = GetName(XinXi_Two) # 获取小区名称
Write_File(Name, 0,Xu)
print("---------小区名称写入成功---------")
time.sleep(3)
Nature = NatureHouse(XinXi_Two) # 获取小区住宅性质(住宅、商业性)
Write_File(Nature, 1,Xu)
print("---------小区性质写入成功---------")
time.sleep(3)
Status = StatusHouse(XinXi_Two) # 获取小区状态(在售)
Write_File(Status, 2,Xu)
print("---------小区状态写入成功---------")
time.sleep(3)
Address = AddressHouse(XinXi_Two) # 获取小区地址
Write_File(Address, 3,Xu)
print("---------小区地址写入成功---------")
time.sleep(3)
Area = AreaHouse(XinXi_Two) # 获取小区房屋面积
Write_File(Area, 4,Xu)
print("---------小区面积写入成功---------")
time.sleep(3)
Average = AveragePriceHouse(XinXi_Two) # 均价
Write_File(Average, 5,Xu)
print("---------小区均价写入成功---------")
time.sleep(3)
Total = TotalPriceHouse(XinXi_Two) # 总价
Write_File(Total, 6,Xu)
print("---------小区总价写入成功---------")
time.sleep(3) Xu += 1 # 调用不同函数获取不同信息 def Write_File(Data, lei,Hang):
data = xlrd.open_workbook(r"F:\实例\Python实例\爬虫\111.xls")
ws = xlutils.copy.copy(data)
table = ws.get_sheet(0)
Shu = Hang * 10
for i in range(len(Data)):
table.write(i + 1 + Shu, lei, Data[i])
print("----第{}项写入成功----".format(i))
ws.save(r"F:\实例\Python实例\爬虫\111.xls") def GetName(XinXi):
"""
@param XinXi: 传入GetHTML函数第二步中筛选出的div标签下的html代码以及目标信息
@return: 返回小区名称,列表类型
"""
Nmae_list = []
# 获取小区名称
Obtain_Name_One = BeautifulSoup(str(XinXi), 'lxml')
Name_One = Obtain_Name_One.findAll(class_="name")
for i in Name_One:
Get_A = BeautifulSoup(str(i), 'lxml')
Nmae_list.append(Get_A.string)
return Nmae_list """
代码以及目标信息均已获取,通过不同函数将html代码在对应函数中逐一进行解析获取函数对应信息并保存即可
以下为部分函数,其他函数未定义 """
def NatureHouse(Nature):
"""房屋性质"""
Nature_list = []
Obtain_Nature = BeautifulSoup(str(Nature), 'lxml')
Nature_one = Obtain_Nature.find_all(class_='resblock-type')
for i in Nature_one:
Get_Span = BeautifulSoup(str(i), 'lxml')
Nature_list.append(Get_Span.string)
return Nature_list def StatusHouse(Status):
"""房屋状态"""
Status_list = []
Obtain_Nature = BeautifulSoup(str(Status), 'lxml')
Status_one = Obtain_Nature.find_all(class_='sale-status')
for i in Status_one:
Get_Span = BeautifulSoup(str(i), 'lxml')
Status_list.append(Get_Span.string)
return Status_list def AddressHouse(Area):
""" @param Area:传入GetHTML函数第二步中筛选出的div标签下的html代码以及目标信息
@return:
Analysis_Label_xxx:分析标签,xxx:代表第几次分析
Target_Information_xxx:目标信息,xxx:代表第几个信息部分,总共分为两部分,以及一个整体信息存储列表Target_Information_list
"""
#获取标签
Target_Information_list = []
Analysis_Label_One = BeautifulSoup(str(Area), 'lxml')
# 获取div标签,calss=resblock-location
Get_label_One = Analysis_Label_One.find_all(class_='resblock-location')
#解析标签并获得span标签
Analysis_Label_Two = BeautifulSoup(str(Get_label_One), 'lxml')
Get_label_Two = Analysis_Label_Two.find_all(name='span') #获取span标签里面的文字内容并保存在列表内 #第一个
Target_Information_One = []
for i in Get_label_Two:
#使用正则表达式取出内部信息并保存在列表中
Information_Str = re.sub(r'<.*?>','',str(i))
Target_Information_One.append(Information_Str)
#将列表内相同小区的地址进行合并,使用循环嵌套获取内容、合并最后保存在列表内
i = 1
a = 0 #第二个,第二个信息是在第一个信息的基础上合并列表内的元素得来
Target_Information_Two = []
while i <= len(Target_Information_One):
while a < i:
#将Target_Information_One中每两项进行合并
Information_Two = Target_Information_One[a]
Information_One = Target_Information_One[i]
Information_Three = Information_One + Information_Two Target_Information_Two.append(Information_Three)
a += 2
i += 2 #获取详细地址 #第三个
Target_Information_Three = []
Span_html_One = Analysis_Label_Two.find_all(name='a')
for c in Span_html_One:
Area_Str_1 = re.sub(r'<.*?>', '', str(c))
Target_Information_Three.append(Area_Str_1) # 将Target_Information_Two和Target_Information_Three两个列表中的各项元素分别进行合并并保存在Area_list列表中
A = min(len(Target_Information_Two),len(Target_Information_Three))
for i in range(A):
Target_Information_list.append(Target_Information_Two[i] + Target_Information_Three[i]) return Target_Information_list def AreaHouse(Area):
""" @param Area: 传入GetHTML函数第二步中筛选出的div标签下的html代码以及目标信息
@return: 返回房屋房间数量以及房屋总面积
"""
Area_list = []
#筛选目标信息的父标签
Obtain_Area_One = BeautifulSoup(str(Area), 'lxml')
Area_one = Obtain_Area_One.find_all(class_='resblock-room') #通过正则表达式去除多余的html标签信息
Get_Area_One = []
for c in Area_one:
Area_Str_1 = re.sub(r'<.*?>', '', str(c))
Get_Area_One.append(Area_Str_1) #通过正则表达式去除多余的换行符
Get_Area_Two = []
for i in Get_Area_One:
Area_Str_2 = re.sub(r'\s+','',str(i))
Get_Area_Two.append(Area_Str_2) #开始获取房屋总面积
Obtain_Area_Two = BeautifulSoup(str(Area),'lxml')
Area_two = Obtain_Area_Two.find_all(class_='resblock-area')
#通过正则表达式去除多余的html标签信息
Get_Area_Three = []
for a in Area_two:
Area_Str_3 = re.sub(r'<.*?>', '', str(a))
Get_Area_Three.append(Area_Str_3) # 通过正则表达式去除多余的换行符
Get_Area_Four = []
for r in Get_Area_Three:
Area_Str_4 = re.sub(r'\s+', '', str(r))
Get_Area_Four.append(Area_Str_4) # 将Get_Area_Two和Get_Area_Four两个列表中的各项元素分别进行合并并保存在Area_list列表中
A = min(len(Get_Area_Two), len(Get_Area_Four))
for i in range(A):
Area_list.append(Get_Area_Two[i] + Get_Area_Four[i]) return Area_list def AveragePriceHouse(Average):
"""
房屋均价
@param Average:
@return:
"""
Average_list = []
Obtain_Average = BeautifulSoup(str(Average), 'lxml')
Average_one = Obtain_Average.find_all(class_='number')
for i in Average_one:
Get_Span = BeautifulSoup(str(i), 'lxml')
Average_list.append(Get_Span.string) return Average_list def TotalPriceHouse(Total):
"""
房屋总价 @param Total:
@return:
"""
Total_list = []
Obtain_Total = BeautifulSoup(str(Total), 'lxml')
Total_one = Obtain_Total.fjind_all(class_='second')
for i in Total_one:
Get_Span = BeautifulSoup(str(i), 'lxml')
Get_Span_one = Get_Span.string
Get_Span_two = Get_Span_one.lstrip('总价')
Total_list.append(Get_Span_two) return Total_list def Create_File():
name = ['名称','性质','状态','地址','面积','均价','总价',]
workbook = xlwt.Workbook(encoding='utf-8', style_compression=0)
sheet = workbook.add_sheet('shett1', cell_overwrite_ok=True)
for i in range(len(name)):
sheet.write(0, i, name[i])
workbook.save(r'F:\实例\Python实例\爬虫\111.xls')
print("文件创建成功") if __name__ == '__main__':
url = "https://qd.fang.lianjia.com/loupan/pg"
Create_File()
DataHtml = GetHTML(url) print("全部房产信息写入成功")
2、数据处理代码
import pandas as pd
import xlrd
import re
import xlutils.copy
import matplotlib.pyplot as plt def ExceptNull():
"""
数据清洗第一步:去除表中空值
@param df: 传入读取的xls表格数据
@return: 保存数据后返回,
"""
df = pd.DataFrame(pd.read_excel(r'F:\实例\Python实例\爬虫\111.xls'))
#查找面积列空值,使用99999填充空缺值后删除所在行
print(df['面积'].isnull().value_counts())
df["面积"] = df["面积"].fillna('')
NullKey = df[(df.面积 == '')].index.tolist()
print(NullKey)
df = df.drop(NullKey)
print("*"*30)
print(df['面积'].isnull().value_counts()) print("*"*30)
#查找总价列空值,使用99999填充空缺值后删除所在行
print(df['总价'].isnull().value_counts())
df["总价"] = df["总价"].fillna('')
NullKey1 = df[(df.总价 == '')].index.tolist()
print(NullKey1)
df = df.drop(NullKey1)
print("*"*30)
print(df['总价'].isnull().value_counts())
df.to_excel('111.xls',index=False,encoding='uf-8') print("修改后数据保存成功") def LeiChuli():
Data = xlrd.open_workbook(r"F:\实例\Python实例\爬虫\111.xls")
ws = xlutils.copy.copy(Data)
Table = Data.sheet_by_name("Sheet1")
Nrows = Table.nrows
list_A = []
for i in range(1,Nrows):
A = Table.cell_value(i,6)
A_Str = re.sub('/套','',A,Nrows)
list_A.append(A_Str)
Replace = []
for i in range(len(list_A)):
Price_Str = list_A[i]
Last_Str = Price_Str[-1]
if Last_Str == '万':
A_Str = re.sub('万', '', Price_Str, 1)
Replace.append(A_Str)
else:
Replace.append(Price_Str)
table = ws.get_sheet(0)
for i in range(len(Replace)):
table.write(i + 1, 6, Replace[i])
print("------>开始写入修改后数据<------")
print("---->第{}项写入成功<----".format(i))
ws.save(r"F:\实例\Python实例\爬虫\111.xls")
print("------>数据写入完成<------") def Data_Analysis_One():
Data = xlrd.open_workbook(r"F:\实例\Python实例\爬虫\111.xls")
ws = xlutils.copy.copy(Data)
Table = Data.sheet_by_name("Sheet1")
Nrows = Table.nrows
a,b,c,d,e,f = 0,0,0,0,0,0 for i in range(1, Nrows):
A = Table.cell_value(i, 5)
if A == "价格待定":
f += 1
else:
if int(A) <= 5000:
a += 1
elif int(A) <= 10000:
b += 1
elif int(A) <= 15000:
c += 1
elif int(A) <= 20000:
d += 1
else:
e += 1 # 开始准备绘制饼状图 #价格区间数据准备
sizes = []
Percentage_a = (a / Nrows) * 100
sizes.append(int(Percentage_a))
Percentage_b = (b / Nrows) * 100
sizes.append(int(Percentage_b))
Percentage_c = (c / Nrows) * 100
sizes.append(int(Percentage_c))
Percentage_d = (d / Nrows) * 100
sizes.append(int(Percentage_d))
Percentage_e = (e / Nrows) * 100
sizes.append(int(Percentage_e))
Percentage_f = (f / Nrows) * 100
sizes.append(int(Percentage_f))
#设置占比说明
labels = '0-5000','5001-10000','10001-15000','15001-20000','20000-','Undetermined'
explode = (0,0,0.1,0,0,0)
#开始绘制
plt.pie(sizes,explode=explode,labels=labels,autopct='%1.1f%%',shadow=True,startangle=90)
plt.axis('equal')
plt.show()
ws.save(r"F:\实例\Python实例\爬虫\111.xls") if __name__ == '__main__':
# ExceptNull()
# LeiChuli()
Data_Analysis_One()
数据来源于链家青岛站部分数据,因为一些原因爬取结果可能不是完全符合预期。
转发请注明出处、欢迎指教、私信。
Python基础——爬虫以及简单的数据分析的更多相关文章
- 初学Python之爬虫的简单入门
初学Python之爬虫的简单入门 一.什么是爬虫? 1.简单介绍爬虫 爬虫的全称为网络爬虫,简称爬虫,别名有网络机器人,网络蜘蛛等等. 网络爬虫是一种自动获取网页内容的程序,为搜索引擎提供了重要的 ...
- Python基础+爬虫基础
Python基础+爬虫基础 一.python的安装: 1.建议安装Anaconda,会自己安装一些Python的类库以及自动的配置环境变量,比较方便. 二.基础介绍 1.什么是命名空间:x=1,1存在 ...
- Python基础简介与简单使用
Python介绍 Python发展史 1989年,为了打发圣诞节假期,Guido开始写Python语言的编译器.Python这个名字,来自Guido所挚爱的电视剧Monty Python’s Flyi ...
- 零python基础--爬虫实践总结
网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本. 爬虫主要应对的问题:1.http请求 2.解析html源码 3.应对反爬机制. 觉得爬虫挺有意思的,恰好看到知乎有人分享的一个爬虫 ...
- Python基础爬虫
搭建环境: win10,Python3.6,pycharm,未设虚拟环境 之前写的爬虫并没有架构的思想,且不具备面向对象的特征,现在写一个基础爬虫架构,爬取百度百科,首先介绍一下基础爬虫框架的五大模块 ...
- Python 基础爬虫架构
基础爬虫框架主要包括五大模块,分别为爬虫调度器.url管理器.HTML下载器.HTML解析器.数据存储器. 1:爬虫调度器主要负责统筹其他四个模块的协调工作 2: URL管理器负责管理URL连接,维护 ...
- python基础爬虫,翻译爬虫,小说爬虫
基础爬虫: # -*- coding: utf-8 -*- import requests url = 'https://www.baidu.com' # 注释1 headers = { # 注释2 ...
- 计算机基础,Python基础--变量以及简单的循环
一.计算机基础 1.CPU 相当于人体的大脑,用于计算处理数据. 2.内存 用于存储数据,CPU从内存调用数据处理计算,运算速度很快. PS:问:既然在内存里的数据CPU运算速度快,为什么计算机不全 ...
- python 基础-爬虫-数据处理,全部方法
生成时间戳 1. time.time() 输出 1515137389.69163 ===================== 生成格式化的时间字符串 1. time.ctime() 输出 Fri Ja ...
随机推荐
- POJ-2488 国际象棋马的走法 (深度优先搜索和回溯)
#include <stdio.h> #define MAX 27 void dfs(int i, int j); int dx[8] = {-1, 1, -2, 2, -2, 2, -1 ...
- 强连通 反向建图 hdu3639
Hawk-and-Chicken Time Limit: 6000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) ...
- poj2914无向图的最小割
http://blog.csdn.net/vsooda/article/details/7397449 //算法理论 http://www.cnblogs.com/ylfdrib/archive/20 ...
- CentOS上安装配置Python3.7
一.安装依赖包,这个具体的作用我也不清楚,感觉好像是在安装的时候会要用到的工具. yum install zlib-devel bzip2-devel openssl-devel ncurses-de ...
- 【C++】常量
注意:以下内容摘自文献[1],修改了部分内容. 1.常量:常量的值是不能改变的,一般从其字面形式即可判别是否为常量. 2.常量包括数值型常量(即常数)和字符型常量. 3.常量无unsigned型.但一 ...
- 题解 P6509 【[CRCI2007-2008] JEDNAKOST】
洛谷题目传送门!! 洛谷博客!! 这道题感觉是一个很另类的DP 至少我的做法是这样的. 重要前置思想:把A存成字符串!!! (应该也没人会想着存成int和long long 吧) 首先,我们定义状态 ...
- 公有继承中派生类Student对基类Person成员的访问 代码参考
#include <iostream> #include <cstring> using namespace std; class Person { private: char ...
- eclipse 界面复原
Windows-----Perspective-----Reset perspective
- 可以Postman,也可以cURL.进来领略下cURL的独门绝技
文章已经收录在 Github.com/niumoo/JavaNotes ,更有 Java 程序员所需要掌握的核心知识,欢迎Star和指教. 欢迎关注我的公众号,文章每周更新. cURL 是一个开源免费 ...
- Java实现 LeetCode 326 3的幂
326. 3的幂 给定一个整数,写一个函数来判断它是否是 3 的幂次方. 示例 1: 输入: 27 输出: true 示例 2: 输入: 0 输出: false 示例 3: 输入: 9 输出: tru ...