入门大数据---Kafka简介
一、简介
ApacheKafka 是一个分布式的流处理平台。它具有以下特点:
- 支持消息的发布和订阅,类似于 RabbtMQ、ActiveMQ 等消息队列;
- 支持数据实时处理;
- 能保证消息的可靠性投递;
- 支持消息的持久化存储,并通过多副本分布式的存储方案来保证消息的容错;
- 高吞吐率,单 Broker 可以轻松处理数千个分区以及每秒百万级的消息量。
二、基本概念
2.1 Messages And Batches
Kafka 的基本数据单元被称为 message(消息),为减少网络开销,提高效率,多个消息会被放入同一批次 (Batch) 中后再写入。
2.2 Topics And Partitions
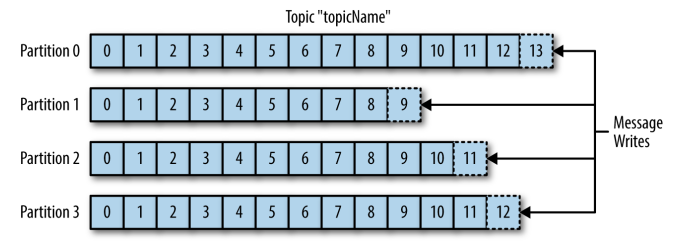
Kafka 的消息通过 Topics(主题) 进行分类,一个主题可以被分为若干个 Partitions(分区),一个分区就是一个提交日志 (commit log)。消息以追加的方式写入分区,然后以先入先出的顺序读取。Kafka 通过分区来实现数据的冗余和伸缩性,分区可以分布在不同的服务器上,这意味着一个 Topic 可以横跨多个服务器,以提供比单个服务器更强大的性能。
由于一个 Topic 包含多个分区,因此无法在整个 Topic 范围内保证消息的顺序性,但可以保证消息在单个分区内的顺序性。
2.3 Producers And Consumers
1. 生产者
生产者负责创建消息。一般情况下,生产者在把消息均衡地分布到在主题的所有分区上,而并不关心消息会被写到哪个分区。如果我们想要把消息写到指定的分区,可以通过自定义分区器来实现。
2. 消费者
消费者是消费者群组的一部分,消费者负责消费消息。消费者可以订阅一个或者多个主题,并按照消息生成的顺序来读取它们。消费者通过检查消息的偏移量 (offset) 来区分读取过的消息。偏移量是一个不断递增的数值,在创建消息时,Kafka 会把它添加到其中,在给定的分区里,每个消息的偏移量都是唯一的。消费者把每个分区最后读取的偏移量保存在 Zookeeper 或 Kafka 上,如果消费者关闭或者重启,它还可以重新获取该偏移量,以保证读取状态不会丢失。
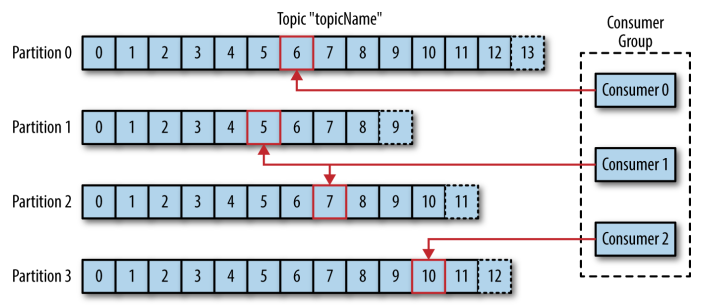
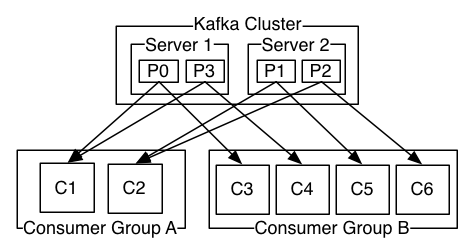
一个分区只能被同一个消费者群组里面的一个消费者读取,但可以被不同消费者群组中所组成的多个消费者共同读取。多个消费者群组中消费者共同读取同一个主题时,彼此之间互不影响。
2.4 Brokers And Clusters
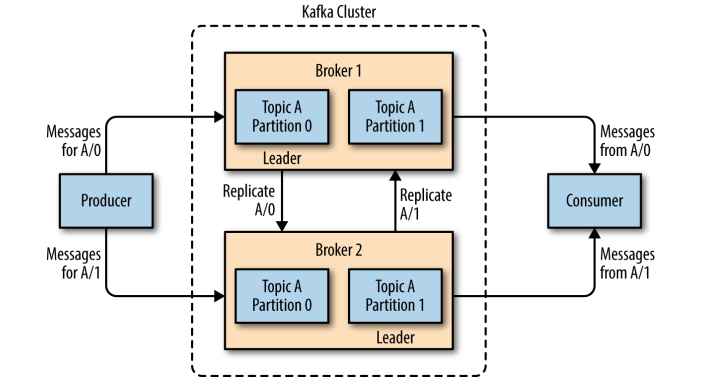
一个独立的 Kafka 服务器被称为 Broker。Broker 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。Broker 为消费者提供服务,对读取分区的请求做出响应,返回已经提交到磁盘的消息。
Broker 是集群 (Cluster) 的组成部分。每一个集群都会选举出一个 Broker 作为集群控制器 (Controller),集群控制器负责管理工作,包括将分区分配给 Broker 和监控 Broker。
在集群中,一个分区 (Partition) 从属一个 Broker,该 Broker 被称为分区的首领 (Leader)。一个分区可以分配给多个 Brokers,这个时候会发生分区复制。这种复制机制为分区提供了消息冗余,如果有一个 Broker 失效,其他 Broker 可以接管领导权。
参考资料
入门大数据---Kafka简介的更多相关文章
- 入门大数据---Flume 简介及基本使用
一.Flume简介 Apache Flume 是一个分布式,高可用的数据收集系统.它可以从不同的数据源收集数据,经过聚合后发送到存储系统中,通常用于日志数据的收集.Flume 分为 NG 和 OG ( ...
- 入门大数据---Kafka生产者详解
一.生产者发送消息的过程 首先介绍一下 Kafka 生产者发送消息的过程: Kafka 会将发送消息包装为 ProducerRecord 对象, ProducerRecord 对象包含了目标主题和要发 ...
- 入门大数据---Kafka消费者详解
一.消费者和消费者群组 在 Kafka 中,消费者通常是消费者群组的一部分,多个消费者群组共同读取同一个主题时,彼此之间互不影响.Kafka 之所以要引入消费者群组这个概念是因为 Kafka 消费者经 ...
- 入门大数据---Kafka深入理解分区副本机制
一.Kafka集群 Kafka 使用 Zookeeper 来维护集群成员 (brokers) 的信息.每个 broker 都有一个唯一标识 broker.id,用于标识自己在集群中的身份,可以在配置文 ...
- 入门大数据---Kafka的搭建与应用
前言 上一章介绍了Kafka是什么,这章就讲讲怎么搭建以及如何使用. 快速开始 Step 1:Download the code Download the 2.4.1 release and un-t ...
- 入门大数据---Spark简介
一.简介 Spark 于 2009 年诞生于加州大学伯克利分校 AMPLab,2013 年被捐赠给 Apache 软件基金会,2014 年 2 月成为 Apache 的顶级项目.相对于 MapRedu ...
- 入门大数据---Sqoop简介与安装
一.Sqoop 简介 Sqoop 是一个常用的数据迁移工具,主要用于在不同存储系统之间实现数据的导入与导出: 导入数据:从 MySQL,Oracle 等关系型数据库中导入数据到 HDFS.Hive.H ...
- 入门大数据---Flume整合Kafka
一.背景 先说一下,为什么要使用 Flume + Kafka? 以实时流处理项目为例,由于采集的数据量可能存在峰值和峰谷,假设是一个电商项目,那么峰值通常出现在秒杀时,这时如果直接将 Flume 聚合 ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
随机推荐
- cocos2dx 入门 环境配置
本人立志走游戏开发这条路,很早之前就准备学习cocos2dx,今天终于忙里偷闲入了一下门,把环境配置好了,创建了自己的第一个cocos项目! 一.环境配置 1.下载cocos https://coco ...
- 【算法】单元最短路径之Bellman-Ford算法和SPFA算法
SPFA是经过对列优化的bellman-Ford算法,因此,在学习SPFA算法之前,先学习下bellman-Ford算法. bellman-Ford算法是一种通过松弛操作计算最短路的算法. 适用条件 ...
- Rocket - debug - TLDebugModuleInner - innerCtrl
https://mp.weixin.qq.com/s/7UY99gEJ8QpVBJIohdqKhA 简单介绍TLDebugModuleInner中innerCtrl相关的寄存器. 1. innerCt ...
- ASP.NET MVC 数据传递 视图向控制器传递
视图向控制器传递 MVC 视图向控制器传递,就是获取用户输入的数据,在去进行操作 好了,我们不多说直接进行我们的案例. 在HomeController类中添加下来方法 [HttpPost] publi ...
- Java实现 LeetCode 98 验证二叉搜索树
98. 验证二叉搜索树 给定一个二叉树,判断其是否是一个有效的二叉搜索树. 假设一个二叉搜索树具有如下特征: 节点的左子树只包含小于当前节点的数. 节点的右子树只包含大于当前节点的数. 所有左子树和右 ...
- Java实现 LeetCode 72 编辑距离
72. 编辑距离 给定两个单词 word1 和 word2,计算出将 word1 转换成 word2 所使用的最少操作数 . 你可以对一个单词进行如下三种操作: 插入一个字符 删除一个字符 替换一个字 ...
- java实现汉诺塔计数
** 汉诺塔计数** 汉诺塔(又称河内塔)问题是源于印度一个古老传说的益智玩具. 大梵天创造世界的时候做了三根金刚石柱子,在一根柱子上从下往上按照大小顺序摞着64片黄金圆盘.大梵天命令婆罗门把圆盘从下 ...
- 链家网 + gevent
import gevent from gevent import monkey monkey.patch_all() from gevent.queue import Queue import tim ...
- DedeCms 首页、列表页调用文章body内容的方法
[第一种方法] arclist标签使用如下: {dede:arclist row='1' typeid='1' addfields='body' idlist='1' channelid='1'} [ ...
- 关于前端JS走马灯(marquee)总结
方案一: <marquee width="360" scrolldelay="20" scrollamount="2" onclick ...