ES[7.6.x]学习笔记(十一)与SpringBoot结合
在前面的章节中,我们把ES的基本功能都给大家介绍完了,从ES的搭建、创建索引、分词器、到数据的查询,大家发现,我们都是通过ES的API去进行调用,那么,我们在项目当中怎么去使用ES呢?这一节,我们就看看ES如何与我们的SpringBoot项目结合。
版本依赖
SpringBoot默认是有ElasticSearch的Starter,但是它依赖的ES客户端的版本比较低,跟不上ES的更新速度,所以我们在SpringBoot项目中要指定ES的最新版本,如下:
<properties>
<elasticsearch.version>7.6.1</elasticsearch.version>
</properties>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
我们在项目中指定ES客户端的版本为7.6.1。
配置文件
然后我们在SpringBoot的配置文件application.properties当中,配置ES集群的地址,如下:
spring.elasticsearch.rest.uris=http://192.168.73.130:9200,http://192.168.73.131:9200,http://192.168.73.132:9200
多个地址之间我们使用,隔开即可。
与ES交互
所有配置的东西都准备好了,下面我们看看在程序当中如何交互,还记得前面咱们提到的动态映射吗?这个东西是非常的好用的,简化了我们不少的工作量。在这里我们还用前面的索引ik_index举例,我们先看看目前ik_index索引中有哪些字段,
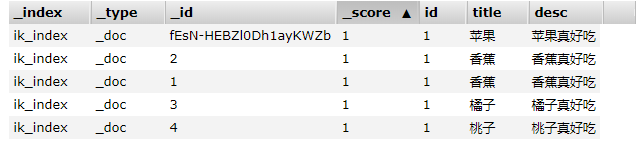
在索引中只有3个字段,id、title和desc。接下来我们在创建索引ik_index对应的实体类,内容也很简单,具体如下:
@Setter@Getter
public class IkIndex {
private Long id;
private String title;
private String desc;
private String category;
}
在实体类中,我们新添加了一个字段category表示分类,我们可以联想一下,category字段动态映射到ES当中会是什么类型?对了,就是text类型,我们再深入想一步,text类型会用到全文索引,会用到分词器,而在索引ik_index当中,我们配置了默认的分词器是IK中文分词器。能够想到这里,我觉得你对ES了解的比较深入了。
接下来,我们就要编写service了,并向ik_index索引中添加一条新的数据,如下:
@Service
public class EService {
@Autowired
private RestHighLevelClient client;
/**
* 添加索引数据
* @throws IOException
*/
public void insertIkIndex() throws IOException {
IkIndex ikIndex = new IkIndex();
ikIndex.setId(10l);
ikIndex.setTitle("足球");
ikIndex.setDesc("足球是世界第一运动");
ikIndex.setCategory("体育");
IndexRequest request = new IndexRequest("ik_index");
// request.id("1");
request.source(JSON.toJSONString(ikIndex), XContentType.JSON);
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.status());
System.out.println(indexResponse.toString());
}
}
首先,我们要引入ES的高等级的客户端RestHighLevelClient,由于我们在配置文件中配置了ES集群的地址,所以SpringBoot自动为我们创建了RestHighLevelClient的实例,我们直接自动注入就可以了。然后在添加索引数据的方法中,我们先把索引对应的实体创建好,并设置对应的值。
接下来我们就要构建索引的请求了,在IndexRequest的构造函数中,我们指定了索引的名称ik_index,索引的id被我们注释掉了,ES会给我们默认生成id,当然自己指定也可以。大家需要注意的是,这个id和IkIndex类里的id不是一个id,这个id是数据在ES索引里的唯一标识,而IkIndex实体类中的id只是一个数据而已,大家一定要区分开。然后我们使用request.source方法将实体类转化为JSON对象并封装到request当中,最后我们调用client的index方法完成数据的插入。我们看看执行结果吧。
CREATED
IndexResponse[index=ik_index,type=_doc,id=f20EVHIBK8kOanEwfXbW,version=1,result=created,seqNo=9,primaryTerm=6,shards={"total":2,"successful":2,"failed":0}]
status返回的值是CREATED,说明数据添加成功,而后面的响应信息中,包含了很多具体的信息,像每个分片是否成功都已经返回了。我们再用elasticsearch-head插件查询一下,结果如下:
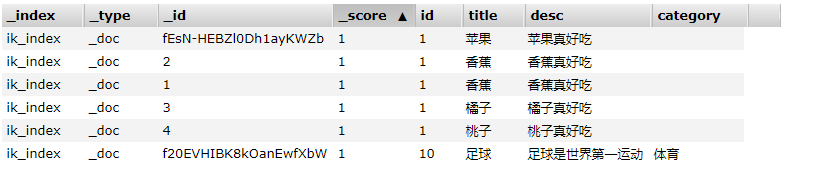
数据插入成功,并且新添加的字段category也有了对应的值,这是我们期望的结果。下面我们再看看查询怎么使用。代码如下:
public void searchIndex() throws IOException {
SearchRequest searchRequest = new SearchRequest("ik_index");
SearchSourceBuilder ssb = new SearchSourceBuilder();
QueryBuilder qb = new MatchQueryBuilder("desc","香蕉好吃");
ssb.query(qb);
searchRequest.source(ssb);
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] hits = response.getHits().getHits();
for (SearchHit hit : hits) {
String record = hit.getSourceAsString();
System.out.println(record);
}
}
- 我们先创建一个查询请求,并指定索引为
ik_index; - 然后我们创建一个请求体
SearchSourceBuilder,再构建我们的查询请求QueryBuilder,QueryBuilder是一个接口,它的实现类有很多,对应着ES中的不同种类的查询,比如咱们前面介绍的bool和boosting查询,都有对应的实现类。在这里,咱们使用MatchQueryBuilder并查询desc包含香蕉好吃的数据,这个查询咱们在前面通过API的方式也查询过。 - 最后我们封装好请求,并通过
client.search方法进行查询,返回的结构是SearchResponse。 - 在返回的结果中,我们获取对应的数据,咦?这个为什么调用了两次Hits方法?咱们可以从API的返回值看出端倪,如下:

我们可以看到返回的结果中确实有两个hits,第一个hits中包含了数据的条数,第二个hits中才是我们想要的查询结果,所以在程序中,我们调用了两次hits。
在每一个hit当中,我们调用
getSourceAsString方法,获取JSON格式的结果,我们可以用这个字符串通过JSON工具映射为实体。
我们看看程序运行的结果吧,
{"id":1,"title":"香蕉","desc":"香蕉真好吃"}
{"id":1,"title":"香蕉","desc":"香蕉真好吃"}
{"id":1,"title":"橘子","desc":"橘子真好吃"}
{"id":1,"title":"桃子","desc":"桃子真好吃"}
{"id":1,"title":"苹果","desc":"苹果真好吃"}
查询出了5条数据,和我们的预期是一样的,由于使用IK中文分词器,所以desc中包含好吃的都被查询了出来,而我们新添加的足球数据并没有查询出来,这也是符合预期的。我们再来看看聚合查询怎么用,
public void searchAggregation() throws IOException {
SearchRequest searchRequest = new SearchRequest("ik_index");
SearchSourceBuilder ssb = new SearchSourceBuilder();
TermsAggregationBuilder category = AggregationBuilders.terms("category").field("category.keyword");
ssb.aggregation(category);
searchRequest.source(ssb);
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
Terms terms = response.getAggregations().get("category");
for (Terms.Bucket bucket : terms.getBuckets()) {
System.out.println(bucket.getKey());
System.out.println(bucket.getDocCount());
}
}
- 同样,我们创建一个
SearchRequest,然后再创建一个TermsAggregationBuilder,TermsAggregationBuilder我们指定了name叫做category,这个name对应着上一节中的那个自定义的名称,大家还有印象吗? - 后面的
field是我们要聚合的字段,注意这里因为category字段是text类型,默认是不能够做聚合查询的,我们指定的是category.keyword,还记得这个keyword类型吗?它是不使用分词器的,我们使用这个keyword类型是可以的。 - 最后把
AggregationBuilder封装到查询请求中,进行查询。 - 查询后,我们怎么去取这个
aggregation呢?取查询结果我们是通过hits,取聚合查询,我们要使用aggregation了,然后再get我们的自定义名称response.getAggregations().get("category")。至于前面的类型,它是和AggregationBuilder对应的,在咱们的例子中使用的是TermsAggregationBuilder,那么我们在取结果时就要用Terms;如果查询时使用的是AvgAggregationBuilder,取结果时就要用Avg。 - 在取得
Terms后,我们可以获取里边的值了。运行一下,看看结果。
体育
1
key是体育,doc_count是1,说明分类体育的数据只有1条。完全符合我们的预期,这个聚合查询的功能非常重要,在电商平台中,商品搜索页通常列出所有的商品类目,并且每个类目后面都有这个商品的数量,这个功能就是基于聚合查询实现的。
好了,到这里,ES已经结合到我们的SpringBoot项目中了,并且最基础的功能也已经实现了,大家放心的使用吧~
ES[7.6.x]学习笔记(十一)与SpringBoot结合的更多相关文章
- python3.4学习笔记(十一) 列表、数组实例
python3.4学习笔记(十一) 列表.数组实例 #python列表,数组类型要相同,python不需要指定数据类型,可以把各种类型打包进去#python列表可以包含整数,浮点数,字符串,对象#创建 ...
- Go语言学习笔记十一: 切片(slice)
Go语言学习笔记十一: 切片(slice) 切片这个概念我是从python语言中学到的,当时感觉这个东西真的比较好用.不像java语言写起来就比较繁琐.不过我觉得未来java语法也会支持的. 定义切片 ...
- springboot学习笔记:9.springboot+mybatis+通用mapper+多数据源
本文承接上一篇文章:springboot学习笔记:8. springboot+druid+mysql+mybatis+通用mapper+pagehelper+mybatis-generator+fre ...
- CAS学习笔记五:SpringBoot自动/手动配置方式集成CAS单点登出
本文目标 基于SpringBoot + Maven 分别使用自动配置与手动配置过滤器方式实现CAS客户端登出及单点登出. 本文基于<CAS学习笔记三:SpringBoot自动/手动配置方式集成C ...
- JavaScript权威设计--JavaScript函数(简要学习笔记十一)
1.函数调用的四种方式 第三种:构造函数调用 如果构造函数调用在圆括号内包含一组实参列表,先计算这些实参表达式,然后传入函数内.这和函数调用和方法调用是一致的.但如果构造函数没有形参,JavaScri ...
- SharpGL学习笔记(十一) 光源创建的综合例子:光源参数可调节的测试场景
灯光的测试例子:光源参数可以调节的测试场景 先看一下测试场景和效果. 场景中可以切换视图, 以方便观察三维体和灯光的位置.环境光,漫射光,镜面反射光都可以在四种颜色间切换. 灯光位置和摄像机位置(Lo ...
- java jvm学习笔记十一(访问控制器)
欢迎装载请说明出处: http://blog.csdn.net/yfqnihao/article/details/8271665 这一节,我们要学习的是访问控制器,在阅读本节之前,如果没有前面几节的 ...
- ES[7.6.x]学习笔记(八)数据的增删改
在前面几节的内容中,我们学习索引.字段映射.分析器等,这些都是使用ES的基础,就像在数据库中创建表一样,基础工作做好以后,我们就要真正的使用它了,这一节我们要看看怎么向索引里写入数据.修改数据.删除数 ...
- ES[7.6.x]学习笔记(十二)高亮 和 搜索建议
ES当中大部分的内容都已经学习完了,今天呢算是对前面内容的查漏补缺,把ES中非常实用的功能整理一下,在以后的项目开发中,这些功能肯定是对你的项目加分的,我们来看看吧. 高亮 高亮在搜索功能中是十分重要 ...
随机推荐
- Mac查看与修改系统默认shell
Mac查看与修改系统默认shell 查看所有shell cat /etc/shells 输出: # List of acceptable shells for chpass(1). # Ftpd wi ...
- 数据结构--顺序栈--C++实现
#include <iostream> #define MaxSize 5000 using namespace std; template <typename T> clas ...
- P2480 [SDOI2010]古代猪文
P2480 [SDOI2010]古代猪文 比较综合的一题 前置:Lucas 定理,crt 求的是: \[g^x\bmod 999911659,\text{其中}x=\sum_{d\mid n}\tbi ...
- Linux服务器有大量的TIME_WAIT状态
我们经常会遇到在服务器上看到大量的TIME_WAIT,它们占用进程不释放,最后会导致所有进程数被耗完,服务器负载增高等生产事故,具体是什么原因导致的呢?我们先来看看TCP的三次握手四次挥手都是怎样的一 ...
- (1).Mybatis的创建。配置。映射。dao映射
https://www.cnblogs.com/zxdup/ 一.Mybatis的创建 1.创建一个新的项目,建议选 Empty Project(空项目), 之后回跳转到Project Structu ...
- (三)Redis &分布式锁
1 Redis使用中的常见问题和解决办法 1.1 缓存穿透 定义:缓存系统都是按照key去缓存查询,如果不存在对应的value,就应该去DB查找.一些恶意的请求会故意查询不存在的key,请求量很大,就 ...
- c#一些常用知识点
UID自动生成随机数 UID.Text = Guid.NewGuid().ToString(); GridView中常用格式化公式 <asp:BoundField DataField=" ...
- x86软路由虚拟化openwrt-koolshare-mod-v2.33联通双拨IPV6教程(第二篇)
续第一篇:https://www.cnblogs.com/zlAurora/p/12433296.html 4 设置多拨 (1)连入OpenWrt Web界面,默认为192.168.1.1,在“网 ...
- 新创建的项目AndroidManifast报App is not indexable by Google Search;
原错误提示:App is not indexable by Google Search; consider adding at least one Activity with an ACTION-VI ...
- PCB规则