SVM多核学习方法简介
作者:Walker
SVM是机器学习有监督学习的一种方法,常用于解决分类问题,其基本原理是:在特征空间里寻找一个超平面,以最小的错分率把正负样本分开。因为SVM既能达到工业界的要求,机器学习研究者又能知道其背后的原理,所以SVM有着举足轻重的地位。
但是我们之前接触过的SVM都是单核的,即它是基于单个特征空间的。在实际应用中往往需要根据我们的经验来选择不同的核函数(如:高斯核函数、多项式核函数等)、指定不同的参数,这样不仅不方便而且当数据集的特征是异构时,效果也没有那么好。正是基于SVM单核学习存在的上述问题,同时利用多个核函数进行映射的多核学习模型(MKL)应用而生。
多核模型比单个核函数具有更高的灵活性。在多核映射的背景下,高维空间成为由多个特征空间组合而成的组合空间。由于组合空间充分发挥了各个基本核的不同特征映射能力,能够将异构数据的不同特征分量分别通过相应的核函数得到解决。目前主流的多核学习方法主要包括合成核方法、多尺度核方法和无限核方法。其具体流程如图1所示:
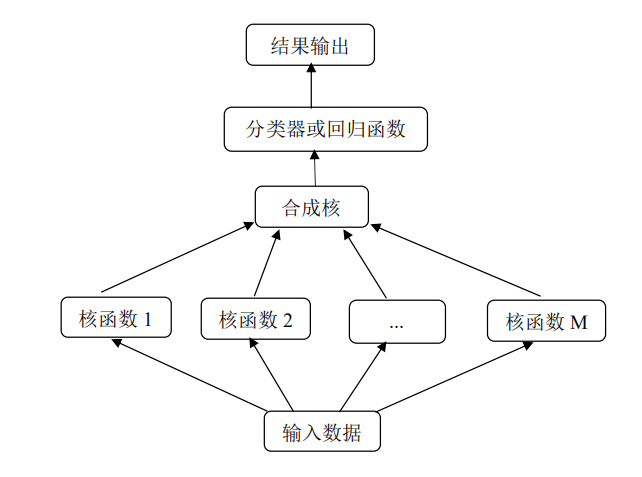
图1 多核学习流程图
接下来我们以二分类问题为例,为大家简单介绍多核学习方法。令训练数据集为X={(x1,y1),(x2,y2),(x3,y3)…(xn,yn)},其中Xi是输入特征,且Xi∈Rd,i= 1,2, …, N,Yi∈{+1, −1}是类标签。SVM 算法目标在于最大化间隔,其模型的原始问题可以表示为:
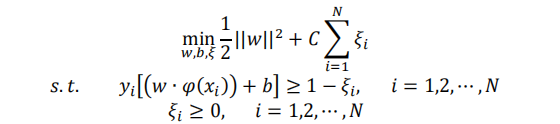
其中,w是待求的权重向量,ζi与C分别是松弛变量和惩罚系数。根据拉格朗日对偶性以及 KKT 条件,引入核函数K( Xi , Xj): Rn×Rn → R,原始问题也可以转换成如下最优化的形式:
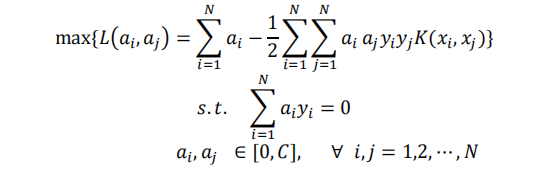
其中,ai与aj为拉格朗日乘子,核函数K( Xi, Xj)=φ(xi) xφ(xj)。核方法的思想就是,在学习与预测中不显示地定义映射函数φ(xi) ,只定义核函数K( Xi, Xj),直接在原低维空间中计算高维空间中的向量内积,既实现低维样本空间到高维特征空间的映射,又不增加计算复杂量。
多核学习方法是单核 SVM 的拓展,其目标是确定 M 个个核函数的最优组合,使得间距最大,可以用如下优化问题表示:
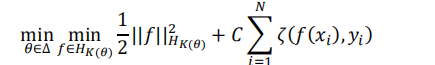
其中∆= {θ∈ ℝ+|θTeM=1},表示 M 个核函数的凸组合的系数,eM是一个向量,M个元素全是 1,K(θ)=∑Mj=1θjkj(∙,∙)代表最终的核函数,其中kj(∙,∙)是第j个核函数。与单核 SVM 一样,可以将上式如下转化:
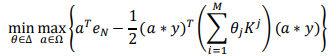
其中Kj∈ RNxN,Ω={a|a∈[0,C]N},“∗”被定义为向量的点积,即(1,0)∗(2,3) = (1 ×2 ,0×3)=(2,0)。通过对比 MKL 与单核 SVM 所对应的优化问题形式,求解多核学习问题的计算复杂度与难度会远大于单核 SVM,所以研究出一种高效且稳定的算法来解决传统多核学习中的优化难题,仍然很具有挑战性。
综上所示,尽管多核学习在解决一些异构数据集问题上表现出了非常优秀的性能,但不得不说效率是多核学习发展的最大瓶颈。首先,空间方面,多核学习算法由于需要计算各个核矩阵对应的核组合系数,需要多个核矩阵共同参加运算。也就是说,多个核矩阵需要同时存储在内存中,如果样本的个数过多,那么核矩阵的维数也会非常大,如果核的个数也很多,这无疑会占用很大的内存空间。其次,时间方面,传统的求解核组合参数的方法即是转化为SDP优化问题求解,而求解SDP问题需要使用内点法,非常耗费时间,尽管后续的一些改进算法能在耗费的时间上有所减少,但依然不能有效的降低时间复杂度。高耗的时间和空间复杂度是导致多核学习算法不能广泛应用的一个重要原因。
下篇预告:不同核学习方法的研究。
参考文献:Research on Multiple Kernel Boosting Learning Algorithm
Fast Multiple Kernel Learning for Classification and Application
Research on Multiple Kernel Learning Algorithms and Their Applications
SVM多核学习方法简介的更多相关文章
- 【转】SVM入门(一)SVM的八股简介
(一)SVM的八股简介 支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本.非线性及高维模式识别中表现出许多特有的优势,并能够 ...
- 不平衡数据下的机器学习方法简介 imbalanced time series classification
imbalanced time series classification http://www.vipzhuanli.com/pat/books/201510229367.5/2.html?page ...
- 模式识别之svm()---支持向量机svm 简介1995
转自:http://www.blogjava.net/zhenandaci/archive/2009/02/13/254519.html 作者:Jasper 出自:http://www.blogjav ...
- 支撑向量机(SVM)
转载自http://blog.csdn.net/passball/article/details/7661887,写的很好,虽然那人也是转了别人的做了整理(最原始文章来自http://www.blog ...
- Spark机器学习系列之13: 支持向量机SVM
Spark 优缺点分析 以下翻译自Scikit. The advantages of support vector machines are: (1)Effective in high dimensi ...
- SVM原理 (转载)
1. 线性分类SVM面临的问题 有时候本来数据的确是可分的,也就是说可以用 线性分类SVM的学习方法来求解,但是却因为混入了异常点,导致不能线性可分,比如下图,本来数据是可以按下面的实线来做超平面分离 ...
- 5. 支持向量机(SVM)软间隔
1. 感知机原理(Perceptron) 2. 感知机(Perceptron)基本形式和对偶形式实现 3. 支持向量机(SVM)拉格朗日对偶性(KKT) 4. 支持向量机(SVM)原理 5. 支持向量 ...
- 4. 支持向量机(SVM)原理
1. 感知机原理(Perceptron) 2. 感知机(Perceptron)基本形式和对偶形式实现 3. 支持向量机(SVM)拉格朗日对偶性(KKT) 4. 支持向量机(SVM)原理 5. 支持向量 ...
- 机器学习——支持向量机SVM
前言 学习本章节前需要先学习: <机器学习--最优化问题:拉格朗日乘子法.KKT条件以及对偶问题> <机器学习--感知机> 1 摘要: 支持向量机(SVM)是一种二类分类模型, ...
随机推荐
- python中excel数据分组处理
1.场景描述 因文本相似性热度统计(python版)需求中要根据故障类型进行分组统计,需要对excel进行分组后再分词统计,简单记录下,有需要的朋友可以直接拿走,不客气! 2.解决方案 采用panda ...
- html/css系列-图片上下居中
本文详情:http://www.zymseo.com/276.html图片上下居中的问题常用的几种方法:图片已知大小和未知大小,自行理解 .main{ width: 400px;height: 400 ...
- Codeforces Round #626 (Div. 2, based on Moscow Open Olympiad in Informatics)
A. Even Subset Sum Problem 题意 给出一串数,找到其中的一些数使得他们的和为偶数 题解 水题,找到一个偶数或者两个奇数就好了 代码 #include<iostream& ...
- 适合MCU用的C语言快速互转HEX(16进制)和原始字符串/数组方法
缘由 这个起因是昨晚群里有人在讨论怎么把字符串转成HEX方法最佳,讨论到最后变成哪种方法效率最优了.毕竟这代码是要在MCU上面跑的,要同时考虑到时间和空间的最优解. 当然讨论的是有结果的,具体实现的方 ...
- 分享一个快速审查js操作Dom的css
第一步 打开开发者工具第二步 打开 Sources 面板第三步 执行用户操作让对象可见(例如鼠标悬停)第四步 在元素可见的时候按下 F8(与“暂停脚本执行”按钮相同)第五步 点击开发者工具左上角的“选 ...
- WEB渗透 - XSS
听说这个时间点是人类这种生物很重要的一个节点 cross-site scripting 跨站脚本漏洞 类型 存储型(持久) 反射型(非持久) DOM型 利用 先检测,看我们输入的内容是否有返回以及有无 ...
- Falsk 路由简析
添加路由 我们熟知添加路由的方式是装饰器: @app.route('/') def hello_world(): return 'Hello World!' #访问web得到 'Hello World ...
- drf(请求封装/认证/权限/节流)
1.请求的封装 class HttpRequest(object): def __init__(self): pass @propery def GET(self): pass @propery de ...
- Upload-labs 测试笔记
Upload-labs 测试笔记 By:Mirror王宇阳 2019年11月~ 文件上传解析学习 环境要求 若要自己亲自搭建环境,请按照以下配置环境,方可正常运行每个Pass. 配置 项 配置 描述 ...
- js小数计算引起的精度误差问题
我记得刚开始学js的时候学到浮点有举例0.1+0.2 它的计算结果是: 0.1+0.20.30000000000000004 很神奇的一个计算,js是弱语言,在精度上没做处理: 我就自己定义了加减乘除 ...