吴裕雄--天生自然python机器学习:使用Logistic回归从疝气病症预测病马的死亡率

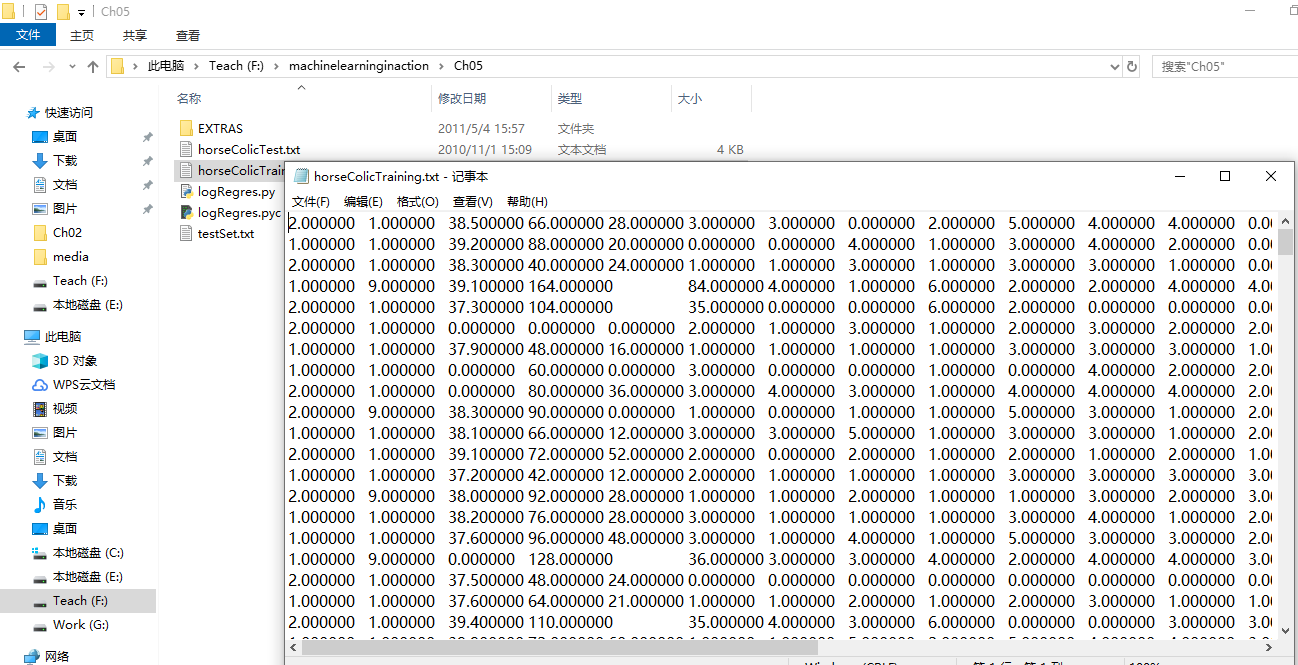
,除了部分指标主观和难以测量外,该数据还存在一个问题,数据集中有
30%的值是缺失的。下面将首先介绍如何处理数据集中的数据缺失问题,然 后 再 利 用 Logistic回 归
和随机梯度上升算法来预测病马的生死。
准备数据:处理被据中的缺失值
因为有时候数据相当昂贵,扔掉和重新获取
都是不可取的,所以必须采用一些方法来解决这个问题。
下面给出了一些可选的做法:

这里选择实数0来替换所有缺失值,恰好能适用于Logistic回归。这样做的直觉在
于 ,我们需要的是一个在更新时不会影响系数的值。回归系数的更新公式如下:

使 用 Logistic
回归方法进行分类并不需要做很多工作,所需做的只是把测试集上每个特征向量乘以最优化方法
得来的回归系数,再将该乘积结果求和,最后输人到sigmoid 函数中即可0 如果对应的sigmoid值
大于0.5就预测类别标签为1,否则为0。
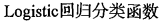
def classifyVector(inX, weights):
prob = sigmoid(sum(inX*weights))
if prob > 0.5:
return 1.0
else:
return 0.0 def colicTest():
frTrain = open('F:\\machinelearninginaction\\Ch05\\horseColicTraining.txt')
frTest = open('F:\\machinelearninginaction\\Ch05\\horseColicTest.txt')
trainingSet = []
trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr =[]
for i in range(21):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[21]))
trainWeights = stocGradAscent1(array(trainingSet), trainingLabels, 1000)
errorCount = 0; numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr =[]
for i in range(21):
lineArr.append(float(currLine[i]))
if int(classifyVector(array(lineArr), trainWeights))!= int(currLine[21]):
errorCount += 1
errorRate = (float(errorCount)/numTestVec)
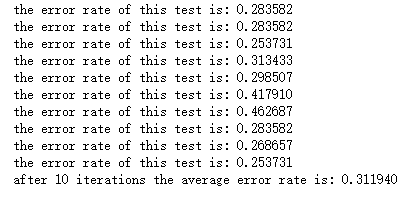
print("the error rate of this test is: %f" % errorRate)
return errorRate
def multiTest():
numTests = 10; errorSum=0.0
for k in range(numTests):
errorSum += colicTest()
print("after %d iterations the average error rate is: %f" % (numTests, errorSum/float(numTests))) multiTest()
小结:

吴裕雄--天生自然python机器学习:使用Logistic回归从疝气病症预测病马的死亡率的更多相关文章
- 吴裕雄--天生自然python机器学习:Logistic回归
假设现在有一些数据点,我们用 一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就称作回归.利用Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类 ...
- 吴裕雄--天生自然python机器学习:机器学习简介
除却一些无关紧要的情况,人们很难直接从原始数据本身获得所需信息.例如 ,对于垃圾邮 件的检测,侦测一个单词是否存在并没有太大的作用,然而当某几个特定单词同时出现时,再辅 以考察邮件长度及其他因素,人们 ...
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 吴裕雄--天生自然python机器学习:朴素贝叶斯算法
分类器有时会产生错误结果,这时可以要求分类器给出一个最优的类别猜测结果,同 时给出这个猜测的概率估计值. 概率论是许多机器学习算法的基础 在计算 特征值取某个值的概率时涉及了一些概率知识,在那里我们先 ...
- 吴裕雄--天生自然python机器学习:决策树算法
我们经常使用决策树处理分类问题’近来的调查表明决策树也是最经常使用的数据挖掘算法. 它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它 是如何工作的. K-近邻算法可 ...
- 吴裕雄--天生自然python机器学习:支持向量机SVM
基于最大间隔分隔数据 import matplotlib import matplotlib.pyplot as plt from numpy import * xcord0 = [] ycord0 ...
- 吴裕雄--天生自然python机器学习:使用K-近邻算法改进约会网站的配对效果
在约会网站使用K-近邻算法 准备数据:从文本文件中解析数据 海伦收集约会数据巳经有了一段时间,她把这些数据存放在文本文件(1如1^及抓 比加 中,每 个样本数据占据一行,总共有1000行.海伦的样本主 ...
- 吴裕雄--天生自然python机器学习:基于支持向量机SVM的手写数字识别
from numpy import * def img2vector(filename): returnVect = zeros((1,1024)) fr = open(filename) for i ...
- 吴裕雄--天生自然python机器学习:使用朴素贝叶斯过滤垃圾邮件
使用朴素贝叶斯解决一些现实生活中 的问题时,需要先从文本内容得到字符串列表,然后生成词向量. 准备数据:切分文本 测试算法:使用朴素贝叶斯进行交叉验证 文件解析及完整的垃圾邮件测试函数 def cre ...
随机推荐
- UML-异常处理
1.名词解释 缺陷(Fault):错误引起的行为.如:程序员拼写错了数据库名称 错误(Error):缺陷在运行系统中的表现.如:当使用拼写错误的名称调用数据库时,抛出数据库异常 故障(Failure) ...
- CSS样式实现两个图片平分三角
<div class='pageOption'> <a href='#' class='option' > <img src='http://imgsrc.hubbles ...
- 19 01 03 css 中 reset 模块 设置
主要就是让到时候 打入代码时候 把一些bug去除 或者 让一些固有的格式取消 /* 将标签默认的间距设为0 */ body,p,h1,h2,h3,h4,h5,h6,ul,dl,dt,form,i ...
- 18 12 2 数据库 sql 的增删改查
---恢复内容开始--- 1 开始进入MySQL 的安装 https://www.cnblogs.com/ayyl/p/5978418.html 膜拜大神的博客 2 默认安装的时候 m ...
- redis官网下载自动安装脚本
注释:使用方法为 # ./redis.sh version ----version为官网版本号 #!/bin/bashversion=$1serverurl='download. ...
- Cookie API和记录上次来访时间
1.什么是Cookie? Cookie是一种会话技术,用千将会话过程中的数据保存到用户的浏览器中,从而使浏览器和服务器可以更好地进行数据交互. 在现实生活中,当顾客在购物时,商城经常会赠送顾客一张会员 ...
- XML文件读写编码不是UTF-8的问题
FileWriter和FileReader在写.读文件时,使用系统当前默认的编码方式. 在中文win下encoding基本是GB2312,在英文win下基本是ISO-8859-1.所以要创建一个UTF ...
- HGP|VCG|UK10K|中科院职业人群队列研究计划|药物基因组学
全球性计划:表观组计划:肝计划 测1000人的变异level HGP计划三个阶段,范围逐步扩大和深化. Pilot:deep sequence---low coverage Phase 1 Phase ...
- XCOM串口助手打印不出数据
本次实验是在基于原子的战舰开发板上的做定时器捕获实验,程序源码下载到板子上运行正常.指示灯正常显示,打开XCOM识别不来串口,原因:硬件上没有插USB转串口线: 连接上USB转串口线,软件上以显示CH ...
- 通过geopandas.sjoin()函数按多边形范围分割点
最近有一批点和多变型的数据,需要将点按照多边形的区域进行分割. 经过若干尝试,终于通过geopandas的sjoin函数得以实现. 这里首先感谢博主“张da统帅”的分享,使得本人获得该实现方法的灵感, ...