Python爬虫入门(基础实战)—— 模拟登录知乎
模拟登录知乎
这几天在研究模拟登录, 以知乎 - 与世界分享你的知识、经验和见解为例。实现过程遇到不少疑问,借鉴了知乎xchaoinfo的代码,万分感激!
知乎登录分为邮箱登录和手机登录两种方式,通过浏览器的开发者工具查看,我们通过不同方式登录时,网址是不一样的。邮箱登录的地址email_url = 'https://www.zhihu.com/login/email',手机登录网址是phone_url = 'http://www.zhihu.com/login/phone_num'。
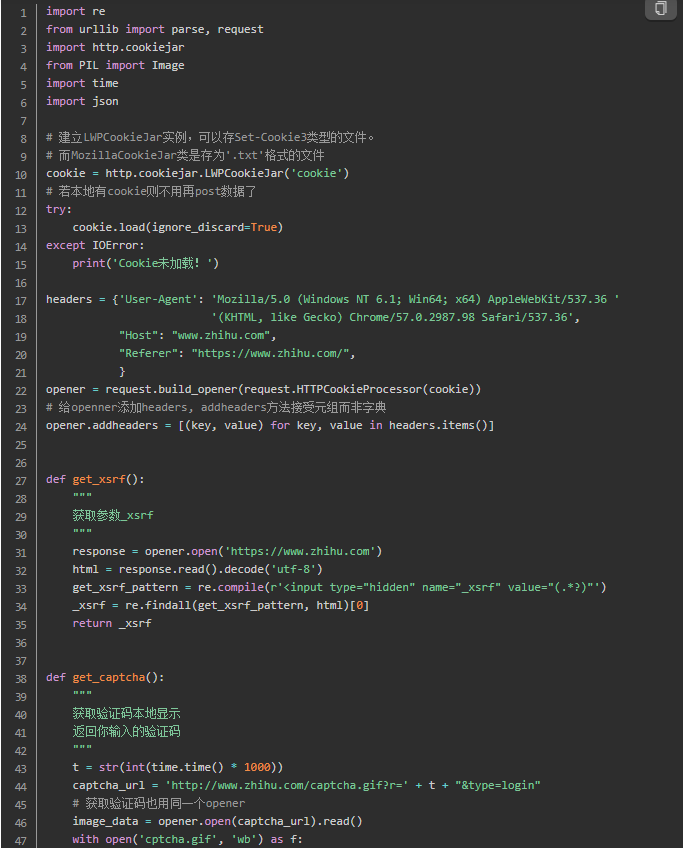
1. 建立一个可以传Cookie的opener
Cookie用来跟踪用户是否已经登录的状态信息。一旦网站认证了我们的登录,就会将cookie存到浏览器中,里面包含了服务器生成的令牌、登录有效时长、状态跟踪信息。当登陆有效时长达到,我们的登录状态就被清空,想要访问其他需要登录后才能访问的页面也就不能成功了。意思就是我们能保持登录状态不掉线,是因为服务器端核对了我们访问时携带的cookie,核对成功后服务器端就认为我们时“已经登录了”的状态。urllib.requst.urlopen()可传入的参数中,都不能携带cookie信息。http.cookiejar的FileCookieJar可以帮到我们,FileCookieJar可以将cookie存到本地文件中。 其中FileCookieJar的子类LWPCookieJar,可以存Set-Cookie3类型的文件,而MozillaCookieJar子类是存为.txt格式的文件。这里我使用LWPCookieJar。

load()可以从本地加载已存的cookie数据,这样我们就可以携带着cookie(相当于带了一块令牌)访问服务器,服务器核对成功后,就可以访问那些登录后才能访问的页面。
其中参数
ignore_discard=True表示即使cookies将被丢弃也把它保存下来,它还有另外一个参数igonre_expires表示当前数据覆盖(overwritten)原文件。
现在建立一个可以处理cookie的opener。
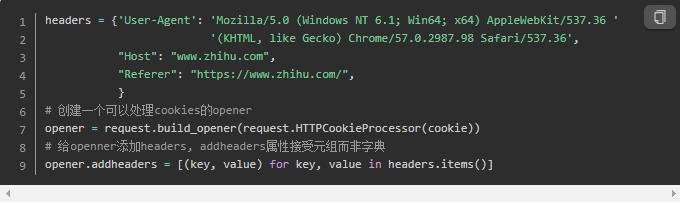
接下来我们可以使用opener.open()来传入url和data了。
2. 获取登录所需关键参数
模拟登录知乎,除了要POST自己的账号密码,还有两个动态生成的参数,一个是_xsrf,还有一个就是讨厌的验证码了。我们输入账号密码后,通过开发者工具找到一个名为email的json文件,请求方法是POST,可以看到其域名是https://www.zhihu.com/login/email.我用火狐的开发者工具,点开这个文件看到里面的参数。
与chrome对应的好像是Headers下面的Form Data,在Network里面勾选preserve log就可以看到。
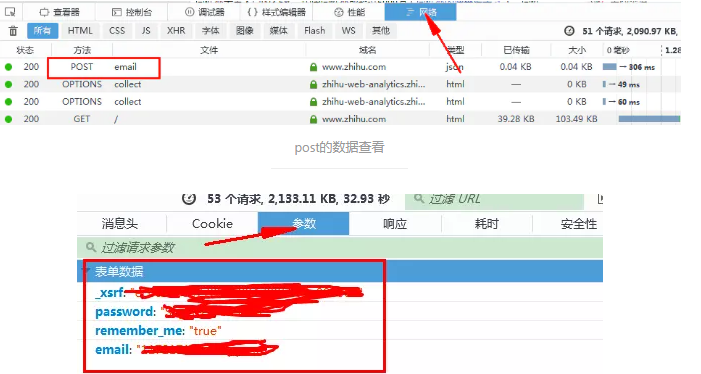
这里就把本人邮箱和密码的给打码了哈
获取_xsrf
这个参数是动态变化了,所以不能获取一次后就一劳永逸。从html的body里面搜索下_xsrf,然后用正则表达式匹配出来就行。

获取验证码
知乎登录一般需要填入验证码,如果没有post这个参数过去,是不能成功登录的。
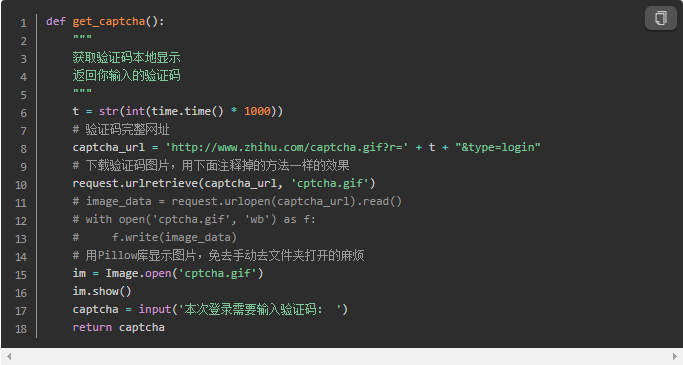
知乎的验证码开始把我给坑了,在html内容的页面里搜索能看到验证码图片的网址,但是实际用xxx.read().decode('utf-8')获取到的网页内容是没有这个网址的,它被隐藏了!好狡诈。研究无果只好搜索,从知乎上这个问题xchaoinfo的回答找到答案,结果是这个图片网址中的一串数字就是时间戳。

时间戳是指格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月01日08时00分00秒)起至现在的总秒数。
通过time.time()可以查看当前时间戳。比如我当前是1471771678.5400066,看是不是和上面红框中的很接近!通过过换算关系t = time.time() * 1000可以得到图片链接的关键部分,其余部分都是不变的。验证码的完整地址为captcha_url = 'http://www.zhihu.com/captcha.gif?r=' + t + "&type=login"。好了,链接知道了,下载下来查看并手动输入就行了。再把这个post过去应该就可以登录成功了,好激动。
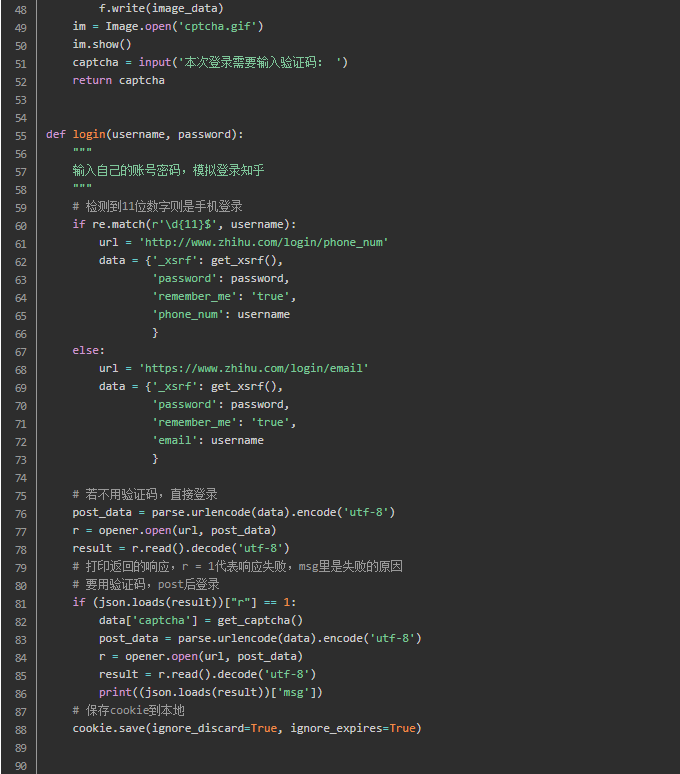
3. 尝试模拟登录知乎
关键的两个东西我们都获取到了,现在登录一下试试吧!要将登录方式考虑进去,如果检测到用于输入手机号,则我们应该访问手机登录网址;否则就是邮箱登录。
def login(username, password):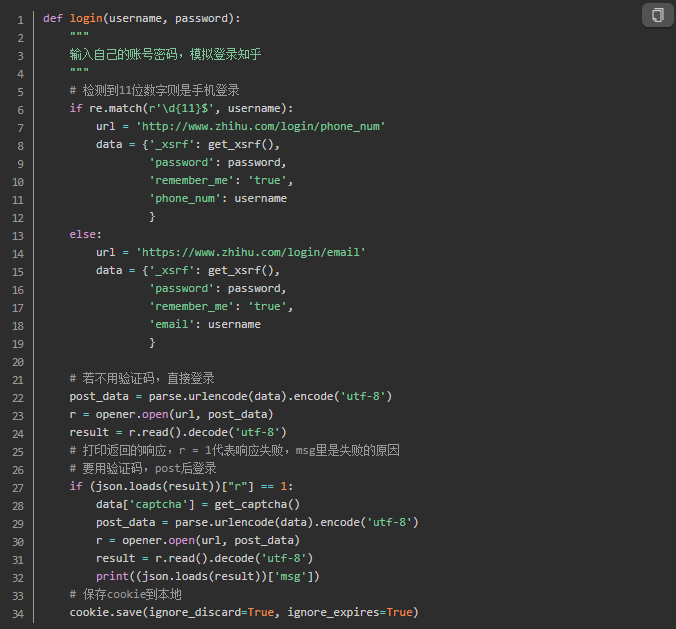
关于那句print((json.loads(result))['msg']) ,opener携带数据post过去,请求网址得到的响应会返回登录信息,该数据是json类型,刚开始我一直是登录失败的,返回这样的玩意儿!
{
"r": 1,
"errcode": 1991829,"data": {"captcha":"\u9a8c\u8bc1\u7801\u9519\u8bef"},
"msg": "\u9a8c\u8bc1\u7801\u9519\u8bef"
}
r为1表示登录失败,0表示登录成功。msg里反映的是登录失败的原因是”验证码会话失效“。
这里一定注意,登录是一个连贯的过程。这个过程我们总共有三次访问网址,一定保证包括获取动态参数,获取验证码、最终模拟登陆都使用同一个opener。这也是登录失败的原因之一,因为刚开始获取_xsrf和验证码时用的是urlopen()。urllib标准库并不很强大,可以尝试requests库,会让这个过程变得简单。
看下结果吧。如果显示登录成功,可以访问以下个人资料的网址,这个如果登录失败了是不能查看的,会返回到登录界面的网址。

好了,这次模拟登录感觉与前两次学习比起来难度加深了,好多问题还得靠搜索才能解决。加油吧。
这里贴上全部代码。

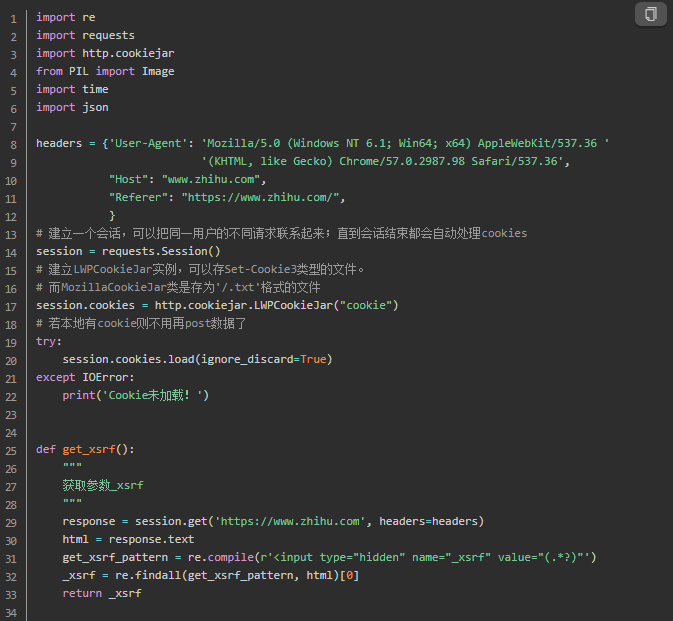
更新: 使用requests库重写程序
今天翻看了下requests的文档,学了点
urllib库再看这个不算很难。我用requests最基本的函数重新实现以上功能,当然大部分代码是重复的。
requests.get()类似urllib.request.urlopen()。如其名是以get方式请求的,接收url,字典形式的headers,timeout,allow_redirects等参数,当然还有requests.post(),可以传入data参数,不像urllib一样需要对字典形式的data进行编码,requests它会自动处理并且data可以传入json数据。
allow_redirects这是参数可选True、False,默认True,若选False则表示禁止重定向,按我的理解即禁止自动跳转。
看下两个库的区别,返回来的response可选text和content,其中text以文本形式返回,content以二进制数据形式返回,比如我们请求的网址是图片,就返回content,便可以以wb方式写入文件了。看下这两个库在实现返回网页内容的区别。对了返回的对象如response还有一个属性是status_code访问成功了当然就返回的200啦。

requests.Session()或者requests.session(),两种写法都可以。类型都是一个class 'requests.sessions.Session',看下源码其实session返回的就是一个Session对象。requests.Session()会新建一个会话,可以把同一用户的不同请求联系起来,直到会话结束都会自动处理cookies,这比urllib方便多了。如果只使用requests.get()或者requests.post()每次访问网页都是独立进行的,并没有把当前用户的多次访问关联起来,故而模拟登录需要用到requests.Session()。然后再用新建的session使用post(),get()等函数。如下。
这只是requests的冰山一角!它强大着呢。号称是HTTP FOR HUMAN。不过掌握以上基本的东西,足够重写模拟登录知乎的程序。进一步学习请看requests文档,那里有详细介绍。
再放requests版本的。


以上使用到的浏览器UA都是电脑端的,现在知乎出了倒立文字验证码。如果因此而导致登录失败,可以将浏览器UA改成Android端或者IOS端。
企鹅  一起交流,资料分享,共同学习
一起交流,资料分享,共同学习
Python爬虫入门(基础实战)—— 模拟登录知乎的更多相关文章
- 【爬虫】python requests模拟登录知乎
需求:模拟登录知乎,因为知乎首页需要登录才可以查看,所以想爬知乎上的内容首先需要登录,那么问题来了,怎么用python进行模拟登录以及会遇到哪些问题? 前期准备: 环境:ubuntu,python2. ...
- Python爬虫初学(三)—— 模拟登录知乎
模拟登录知乎 这几天在研究模拟登录, 以知乎 - 与世界分享你的知识.经验和见解为例.实现过程遇到不少疑问,借鉴了知乎xchaoinfo的代码,万分感激! 知乎登录分为邮箱登录和手机登录两种方式,通过 ...
- Python爬虫入门有哪些基础知识点
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- 2.Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- 转 Python爬虫入门二之爬虫基础了解
静觅 » Python爬虫入门二之爬虫基础了解 2.浏览网页的过程 在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以 ...
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
随机推荐
- .Net Web Api返回Json数据中原对象变量名大小写问题
这两天在工作中使用SignalR的WebSocket做数据实时传递的功能开发,在后端主动向前端广播数据以Json传递时,前端获取的Json中对应类的变量名首字母默认传递的是大写.而前端一直获取到的后台 ...
- jdk安装和配置教程
目录 jdk的下载 jdk的安装 配置环境变量 验证是否配置成功] 一些常见的错误(待更新) 一.首先是jdk的下载 链接:https://pan.baidu.com/s/1ojQDuCwiGSA7A ...
- 【故障公告】部署在 k8s 上的博客后台昨天与今天在访问高峰多次出现 502
非常抱歉,从昨天上午开始,部署在 k8s 集群上的博客后台(基于 .NET Core 3.1 + Angular 8.2 实现)出现奇怪问题,一到访问高峰就多次出现 502 ,有时能自动恢复,有时需要 ...
- Linux系统:Centos7下搭建PostgreSQL关系型数据库
本文源码:GitHub·点这里 || GitEE·点这里 一.PostgreSQL简介 1.数据库简介 PostgreSQL是一个功能强大的开源数据库系统,具有可靠性.稳定性.数据一致性等特点,且可以 ...
- 03使用Want Weapp进行路由跳转
因为这里使用的是第三方库,所以你要引入哈. 在app.json中引入哈. "usingComponents": { "van-cell": "@van ...
- Vue-cli2.0 第3节 解读Vue-cli模板
Vue-cli2.0 第3节 解读Vue-cli模板 目录 Vue-cli2.0 第3节 解读Vue-cli模板 第3节 解读Vue-cli模板 1. npm run build命令 2. main. ...
- Java第三十五天,用JDBC操作MySQL数据库(一),基础入门
一.JDBC的概念 Java DataBase Connectivity 从字面意思我们也不难理解,就是用Java语言连接数据库的意思 JDBC定义了Java语言操作所有关系型数据库的规则(接口).即 ...
- Linux服务器架设篇,Nginx服务器的架设
1.安装 nginx依赖包 (1)安装pcre yum install pcre-devel (2)安装openssl yum -y install openssl-devel (3)安装zlib y ...
- String 对象-->大小比较
1.定义和用法 规则:从左至右依次对比相同下标处的字符,当两个字符不相等时,哪个字符的ASCII值大,那就哪个字符串就大. 返回值为1,左边大于右边 返回值为-1,右边大于左边 返回值为0,则相等 举 ...
- JUC——检视阅读
JUC--检视阅读 参考资料 JUC知识图参考 JUC框架学习顺序参考 J.U.C学习总结参考,简洁直观 易百并发编程,实践操作1,不推荐阅读,不及格 JUC文章,带例子讲解,可以学习2 Doug L ...