Django 路由视图FBV/CBV
| 路由层 |
url路由层结构
from django.conf.urls import url
from django.contrib import admin
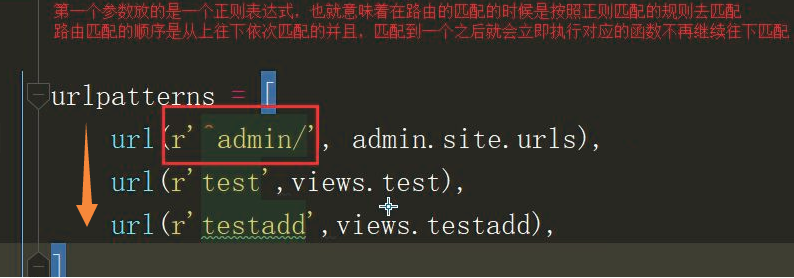
from app01 import views urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^$', views.index),
url(r'^index/', views.index, name='index'),
] url(正则表达式, views视图函数,参数,别名)
在Django1.0版本中路由层,第一个参数就是一个正则表达式,也就意味着路由在匹配的时候是按照正则表达式的规则取匹配的, 路由的匹配顺序是从上到下依次匹配,匹配到之后马上执行视图
函数,不在向下继续匹配路由。
按照正则表达式语法,就可以实现首页的路由书写方式 ,和不存在页面(错误页面404)路由的书写方式
,和不存在页面(错误页面404)路由的书写方式
 ,注意错误页面位置放到最后。
,注意错误页面位置放到最后。
匹配一个到无限个数字的路由书写方式: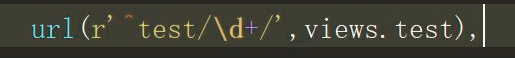
常用的解决错误匹配的方法:1 切换位置 2 换正则表达式。
Django2.0版本中url 变为了path,但是它也保留了正则的方式: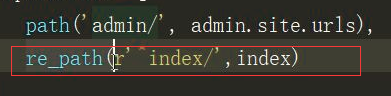
补充说明:
# 是否开启URL访问地址后面不为/跳转至带有/的路径的配置项
APPEND_SLASH=True Django settings.py配置文件中默认没有 APPEND_SLASH 这个参数,但 Django 默认这个参数为 APPEND_SLASH = True。 其作用就是自动在网址结尾加'/'。 其效果就是: 我们定义了urls.py:
from django.conf.urls import url
from app01 import views urlpatterns = [
url(r'^blog/$', views.blog),
] 访问 http://www.example.com/blog 时,默认将网址自动转换为 http://www.example/com/blog/ 。 如果在settings.py中设置了 APPEND_SLASH=False,此时我们再请求 http://www.example.com/blog 时就会提示找不到页面。
Django 1.0 与2.0 的差别
django2.0里面的path第一个参数不支持正则,你写什么就匹配,100%精准匹配 django2.0里面的re_path对应着django1.0里面的url 虽然django2.0里面的path不支持正则表达式,但是它提供五个默认的转换器 str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式
int,匹配正整数,包含0。
slug,匹配字母、数字以及横杠、下划线组成的字符串。
uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?) 自定义转换器
1.正则表达式
2.类
3.注册 # 自定义转换器
class FourDigitYearConverter:
regex = '[0-9]{4}'
def to_python(self, value):
return int(value)
def to_url(self, value):
return '%04d' % value # 占四位,不够用0填满,超了则就按超了的位数来!
register_converter(FourDigitYearConverter, 'yyyy')
PS:路由匹配到的数据默认都是字符串形式
有名分组与无名分组
分组的目的:利用正则分组手段,来实现参数的传递。例如在编辑用户的时候,我们需要获取用户的id,之前是借助 href get请求传值的方式,将用户的id传到后台。现在我们有了更专业的手段。
分组分类:
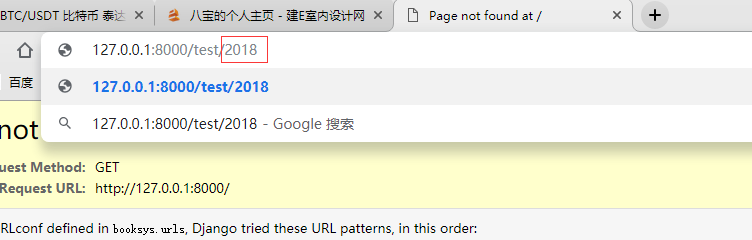
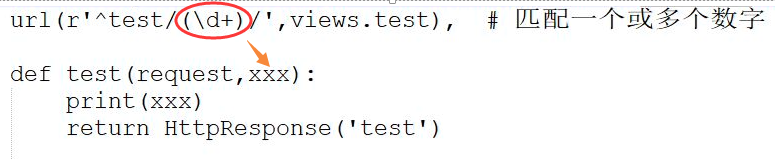
有名分组,我将其理解为位置参数的传值方式,使用方式如下图,浏览器用户输入的网址中,test/ 后方的2018,在url.py 中利用正则分组的方式,将其作为位置参数,传给view层的test函数的xxx。
这样就完成了前端对后端的参数传递,和之前利用a标签在get模式下的传参方式如出一辙。获取到这个参数之后,就可以进行新的一通骚操作了。
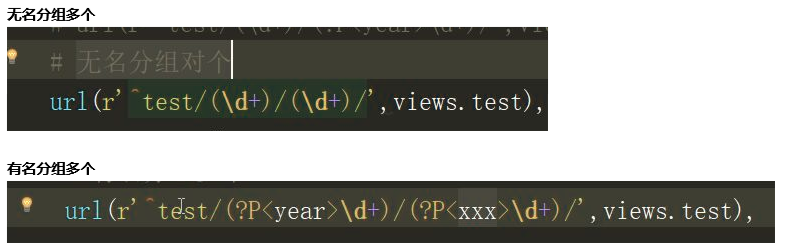
无名分组,我将其理解为关键字参数的传值方式,和无名分组大差不差,就是参数前面指定了一个名称,这个名称有指定的作用,和函数的位置与关键字传参如出一辙。使用方式如下图:
?P<year> 就是固定的书写格式,year就是参数名称,所以对应于view层中的函数也必须有year这个形参来接收。


注意:有名分组于无名分组不要混着用,这是规定,没有为什么!当然相同类型也可以传多个参数。
反向解析
随着功能的增加会出现更多的视图,可能之前配置的正则表达式不够准确,于是就要修改正则表达式,但是正则表达式一旦修改了,之前所有对应的超链接都要修改,真是一件麻烦的事情,而且可能还会漏掉一些超链接忘记修改,有办法让链接根据正则表达式动态生成吗? 就是用反向解析的办法。
应用范围:
1 模板中的超链接
2 视图中的重定向
正如上面所说,如果我们时不时的更改正则表达式,此时我们就要改很多的地方,那有没有一种方式能够不那么麻烦,也能随意的改正则表达式呢,答案就是给这个url 命名。
 如图所示,在函数名后面加一个 name= ’名称‘ 的方式,为该url贴个名字,有了这
如图所示,在函数名后面加一个 name= ’名称‘ 的方式,为该url贴个名字,有了这
个名字之后,前端后端下次再只需要通过这个名字取匹配相应的url ,此时无论你怎样去改动url中的正则表达式都无所谓,因为它们以及换成了 名字 来链接彼此了。此时要注意,这个
名字是一定不能重复的。 既然说是用名字来替代前面的url,那具体如何使用呢:
前端使用方式:
 标准的模板语法。
标准的模板语法。
后端使用方式,先解释,后端是想通过这个名字反向得到 名字所代表 url的正则表达式,以达到无论正则表达式怎么变,我只要后端名字和url保持一致,就能拿到这个url中的正则表达式。
通常这里是结合(redirect)重定向来使用,也就是你前面url正则随意变,我重定向永远能匹配到你。这里就使用到了reverse 模块。
首先是导入 reverse 然后如图操作
结论:有了反向解析之后,我们就不用再担心,改了url的正则表达式之后,又得改view 和 html中的正则表达式,有了名字之后,就省事多了。但是此时又有了新的问题,上面所说的有名分组和无名分组
的参数要怎么结合着使用呢?


路由分发
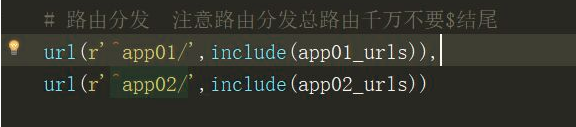
项目中的urls层作为一个大组长,每个app就是一个个体,路由来了先由大组长分发到每个个体中的urls.py中,来做匹配。这样的好处在于,大组长里不需要把所有的路由都写下来,
结构更加清晰,适合一个项目中有多个app的场景。注意分发总路由千万不要写$结尾
伪静态码(seo搜索引擎优化)
作用:提升网页颗粒度,让搜索引擎更容易搜索到,因为搜索引擎会优先记录以html结尾的静态页面。

模拟环境
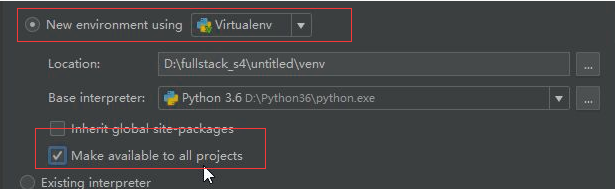
为啥要用虚拟环境:一个项目中需要的模块是有限的,虚拟环境可以避免导入一些无用的模块,需要什么模块就导入什么模块。本质上就是下载了一个新的pycham,一个纯净的环境。

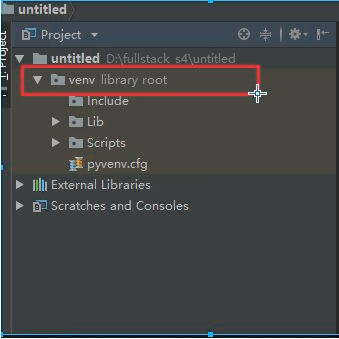
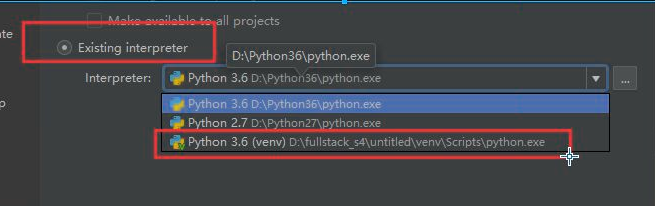
换源的方法:百度搜索pip源,复制清华源的url 在项目中添加,双击任意一个现有模块,删除之前的源,添加新源url。

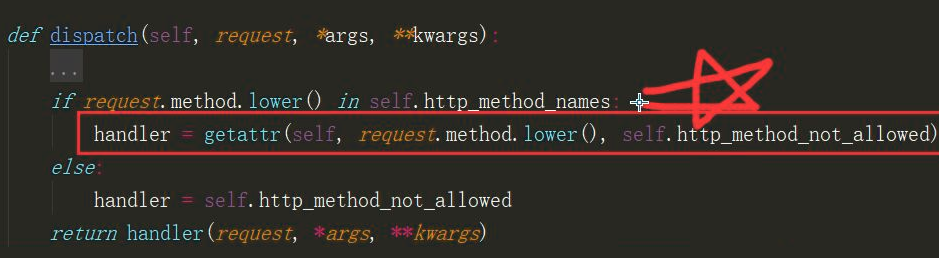
| FBV/CBV |
FBV fouction base view,基于函数的视图
CBV class base view 基于函数的视图

class MyCls(View):
def get(self,request):
return render(request,'index.html')
def post(self,request):
return HttpResponse('post')


使用JSON实现前后端分离

dumps 内部加入ensure——ascii之后 序列化的字符串中中午不会在自动编码。Django自带的方式,
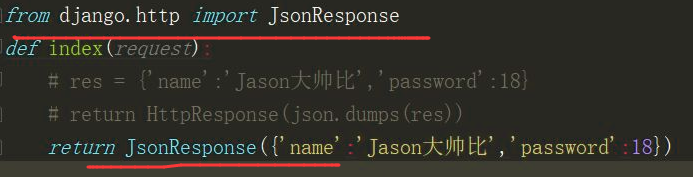
JsonResponse(将相应的数据自动转换成json格式,然后直接发送回浏览器)
导入模块
from django.http import JsonResponse
import json 原始方法:
def index(request):
res = {'name':'sgt','password':18}
return HttpResponse(json.dumps(res)) JsonResponse方法:
def index(request):
return JsonResponse(
{'name':'sgt','password':''},
json_dumps_params={'ensure_ascii':False}
) 注意:json_dumps_params={'ensure_ascii':False}这个的作用是,将Django默认转码功能取消,这样就能显示汉字了。
文件上传
1 注意form表单数据提交的方式

2 请求通过点 FILES方法可以获取文件字典对象,通过get()方法可以获取字典中的值
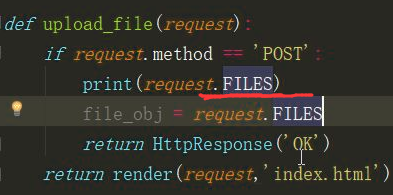
3 get(‘my_file’)可以获取FILES请求中的文件数据。
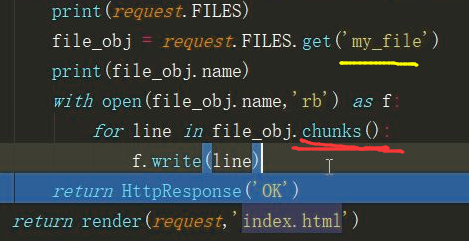
request.path 与 request.get_full_path 区别:get_full_path可以获取用户输入的完整路径。

Django 路由视图FBV/CBV的更多相关文章
- Django---view视图FBV&CBV
一:创建项目和应用: 或者用命令创建: 1:django-admin.py startproject CBV&FBV 2: cd CBV&FBV (路径切到该文件夹下) 3: pyth ...
- Django FBV/CBV、中间件、GIT使用
s5day82 内容回顾: 1. Http请求本质 Django程序:socket服务端 a. 服务端监听IP和端口 c. 接受请求 \r\n\r\n:请求头和请求体 \r\n & reque ...
- django中视图处理请求方式(FBV、CBV)
FBV FBV(function base views) 就是在视图里使用函数处理请求. 在之前django的学习中,我们一直使用的是这种方式,所以不再赘述. CBV CBV(class base v ...
- django中视图函数的FBV和CBV
1.什么是FBV和CBV FBV是指视图函数以普通函数的形式:CBV是指视图函数以类的方式. 2.普通FBV形式 def index(request): return HttpResponse('in ...
- Python菜鸟之路:Django 路由补充1:FBV和CBV - 补充2:url默认参数
一.FBV和CBV 在Python菜鸟之路:Django 路由.模板.Model(ORM)一节中,已经介绍了几种路由的写法及对应关系,那种写法可以称之为FBV: function base view ...
- django FBV +CBV 视图处理方式总结
1.FBV(function base views) 在视图里使用函数处理请求. url: re_path('fbv', views.fbv), # url(r'^fbv' ...
- Django 学习视图之FBV与CBV
一. CBV与FBV CBV:Class Based View FBV:Function Based View 我们之前写过的都是基于函数的view,就叫FBV.还可以把view写成基于类的,那就是C ...
- Django学习笔记之CBV和FBV
FBV FBV(function base views) 就是在视图里使用函数处理请求. 在之前django的学习中,我们一直使用的是这种方式,所以不再赘述. CBV CBV(class base v ...
- 【python】-- Django路由系统(网址关系映射)、视图、模板
Django路由系统(网址关系映射).视图.模板 一.路由系统(网址关系映射) 1.单一路由对应: 一个url对应一个视图函数(类) urls.py: url(r'^test', views.test ...
随机推荐
- Hibernate 之QBC
转自:http://blog.csdn.net/agromach/article/details/1932290 一.Hibernate 中聚合函数的使用 Criteria接口的Projections ...
- ELECTRON新增模块的方法
因为electron和node.js用的V8版本不一致,所以直接使用npm安装的模块可能在electron中不可用,特别是使用c.c++开发的模块.官方的说明:https://github.com/e ...
- 【Linux学习】Ubuntu下 sambaserver搭建
1.安装samba,smbfs 2.配置smb.conf文件 配置文件之前须要先备份一下须要配置的文件(养成好的习惯) 输入命令: 进入到smb.conf文件里,在文件的最后加入下列语句 保存后.退出 ...
- 保护眼睛-eclipse黑色背景设置
eclipse中java编辑器颜色改动,适合程序员人群: 长时间编码,眼睛是有非常大负担的,特别是使用eclipse,它自带的java编辑器背景色是刺眼的白色.代码颜色基本是黑色,这样一个编辑器里白色 ...
- Ubuntu14.04下Android系统与应用开发软件完整apt-get 源。
# deb cdrom:[Ubuntu 14.04.1 LTS _Trusty Tahr_ - Release amd64 (20140722.2)]/ trusty main restricted# ...
- 详略。。设计模式1——单例。。。。studying
设计模式1--单例 解决:保证了一个类在内存中仅仅能有一个对象. 怎么做才干保证这个对象是唯一的呢? 思路: 1.假设其它程序可以任意用new创建该类对象,那么就无法控制个数.因此,不让其它程序用ne ...
- DOCKER_HOST have a weird tcp
[piqiu@benjaminpro ~]$boot2docker start Waiting for VM and Docker daemon to start... ............... ...
- linux 启动两个tomcat
按照下面的步骤操作即可部署成功:一些具体操作命令就不详细说了,直接说有用的:1.在 /usr/local 下部署两个Tomcat,tomcat的文件夹重命名为:tomcat6-1 . tomcat ...
- 在Win7中修改 系统盘中 “系统” - “用户” 的环境变量映射关系
1.在此列表中,选中对应登录帐号 HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\ProfileList 2.将Prof ...
- luogu1993 小K的农场
题目大意 小K在MC里面建立很多很多的农场,总共n个,以至于他自己都忘记了每个农场中种植作物的具体数量了,他只记得一些含糊的信息(共m个),以下列三种形式描述: 农场a比农场b至少多种植了c个单位的作 ...