LIMIT语句解析及本章简单回顾(二十九)

一、LIMIT
限制查询结果返回的数量
[LIMIT {[offset,] row_count | row_count OFFSET offset}]

select * from user;
除了可以对记录进行排序,还可以限制记录返回的数量,我们使用limit关键词,比如我们要查找user表中的前3条记录。操作命令及结果如下:
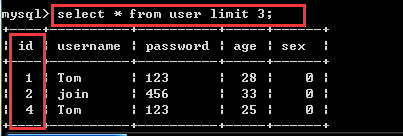
select * from user limit 3;
3表示我们限制查询3条记录,从结果可以看出,查询出了前3条记录。跟id号是没有关系的。假设我们要查找第3、4条记录我们该怎么办呢,那么指定一个参数就不够了,我们可以输入两个参数,第一个参数表示从第几条返回,第二个参数表示返回几条。
下面我们来试一下,操作命令及结果如下:
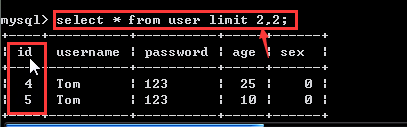
select * from user limit 2,2;
原因是select语句中的记录是从0开始编号的,也就是说如果我们要查找第3,4条记录,我们需要输入limit 2,2;除此之外,我们的id号和结果的排列顺序并没有任何的直接关系。这一点希望大家注意一下。
第一个参数表示从第几条开始返回。
第二个参数表示返回几条。
如果我们要查找第4,5条记录,我们需要输入limit 3,2。
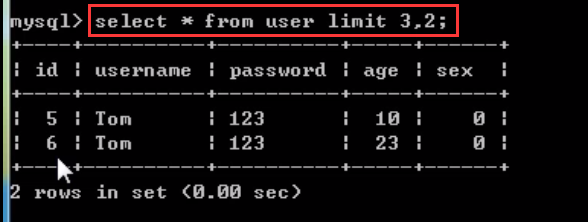
select * from user limit 3,2;
第一个参数表示从第几条开始返回。
第二个参数表示返回几条。
二、INSERT SELECT语句
既然我们现在已经明白了select语句,现在我们就返回到之前我们提到过的insert select语句,他的意思就是把我们查找的结果插入到指定的表中,我们先来新建一张test数据表,操作命令及结果如下:
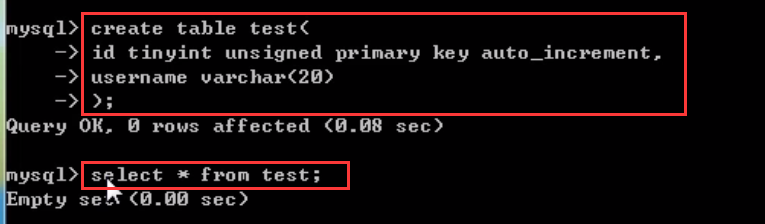
create table test(
id tinyint unsigned primary key auto_increment,
username varchar(20)
); select * from test;
现在我们把user表中年龄>30的记录导入到test表中,这里需要注意一点,因为test里只有一个username字段需要插入数据,所以我们从user表里select的时候就选择select username字段,操作命令及结果如下:
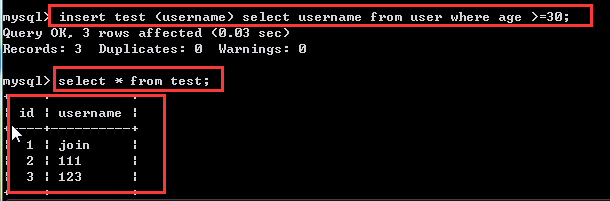
insert test (username) select username from user where age>=30; select * from test;
我们发现记录已经写入到test数据表中,希望大家多练习一下。
三、本章回顾
本章我们主要学习了记录的增删改查四个基本操作。
第一个,insert,我们可以通过3种方法进行记录的插入操作,分别是普通的insert语句,insert set和insert select,update有两种更新语句,分别是单表更新和多表更新,多表更新操作我们会在后面给大家讲解。
同样的,delete语句也单表删除和多表删除两种操作语句,多表删除我们后续再讲。
最后一个就是select语句,其中where可以进行条件的设定,group by可以进行结果的分组,having可以对分组的条件进行设定,order by可以对结果进行排序,limit来限制返回结果的数量。这就是我们本章学习的主要内容,希望大家多多练习。

LIMIT语句解析及本章简单回顾(二十九)的更多相关文章
- 【黑金原创教程】【FPGA那些事儿-驱动篇I 】原创教程连载导读【连载完成,共二十九章】
前言: 无数昼夜的来回轮替以后,这本<驱动篇I>终于编辑完毕了,笔者真的感动到连鼻涕也流下来.所谓驱动就是认识硬件,还有前期建模.虽然<驱动篇I>的硬件都是我们熟悉的老友记,例 ...
- 调用MyFocus库,简单实现二十几种轮播效果
一.首先点击这里下载myFocus库文件,标准文件库就行了,很小仅仅1.4M. myFocus库有以下的好处: a . 文件小巧却高效强大,能够实现二十几种轮播的效果. b . 极其简单的使用,只需要 ...
- 聊聊高并发(二十九)解析java.util.concurrent各个组件(十一) 再看看ReentrantReadWriteLock可重入读-写锁
上一篇聊聊高并发(二十八)解析java.util.concurrent各个组件(十) 理解ReentrantReadWriteLock可重入读-写锁 讲了可重入读写锁的基本情况和基本的方法,显示了怎样 ...
- salesforce 零基础学习(二十九)Record Types简单介绍
在项目中我们可能会遇见这种情况,不同的Profile拥有不同的页面,页面中的PickList标签可能显示不同的值.这个时候,使用Record Types可以很便捷的搞定需求. Record Types ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十九):推送avro格式数据到topic,并使用spark structured streaming接收topic解析avro数据
推送avro格式数据到topic 源代码:https://github.com/Neuw84/structured-streaming-avro-demo/blob/master/src/main/j ...
- Java开发学习(二十九)----Maven依赖传递、可选依赖、排除依赖解析
现在的项目一般是拆分成一个个独立的模块,当在其他项目中想要使用独立出来的这些模块,只需要在其pom.xml使用<dependency>标签来进行jar包的引入即可. <depende ...
- 【leetcode 简单】 第九十九题 字符串相加
给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和. 注意: num1 和num2 的长度都小于 5100. num1 和num2 都只包含数字 0-9. num1 和num2 都不包 ...
- 【leetcode 简单】第十九题 删除排序链表中的重复元素
给定一个排序链表,删除所有重复的元素,使得每个元素只出现一次. 示例 1: 输入: 1->1->2 输出: 1->2 示例 2: 输入: 1->1->2->3-&g ...
- jQuery 源码解析(二十九) 样式操作模块 尺寸详解
样式操作模块可用于管理DOM元素的样式.坐标和尺寸,本节讲解一下尺寸这一块 jQuery通过样式操作模块里的尺寸相关的API可以很方便的获取一个元素的宽度.高度,而且可以很方便的区分padding.b ...
随机推荐
- android学习笔记(5)Activity生命周期学习
每一个activity都有它的生命周期,开启它,关闭它,跳转到其他activity等等,都会自己主动调用下面某种方法.对这些个方法覆写后观察学习. protected void onCreate(Bu ...
- Ubuntu: GlusterFS+HBase安装教程
HBase通常安装在Hadoop HDFS上,但也能够安装在其它实现了Hadoop文件接口的分布式文件系统上.如KFS. glusterfs是一个集群文件系统可扩展到几peta-bytes. 它集合了 ...
- virtio netdev的创建
Linux眼下支持至少了8种虚拟化系统: Xen KVM VMware's VMI IBM's System p IBM's System z User Mode Linux lguest IBM's ...
- 整数翻转C++实现 java实现 leetcode系列(七)
给出一个 32 位的有符号整数,你需要将这个整数中每位上的数字进行反转. 示例 1: 输入: 123 输出: 321 示例 2: 输入: -123 输出: -321 示例 3: 输入: 120 输出: ...
- JavaScript中Number常用属性和方法
title: JavaScript中Number常用属性和方法 toc: false date: 2018-10-13 12:31:42 Number.MAX_VALUE--1.79769313486 ...
- hihoCoder 1403 后缀数组 重复旋律
思路: 后缀数组 第一次写 留个模板吧 先求出后缀数组,问题转换为询问height数组中连续k-1个数的最小值的最大值,单调队列扫描一遍即可.-yousiki 手懒用得STL //By SiriusR ...
- R学习小计
安装R扩展包:install.packages("FKF")http://www.douban.com/note/243004605/1.输入数据 l读入有分隔符数据:A<- ...
- P3809 【模版】后缀排序
题目背景 这是一道模版题. 题目描述 读入一个长度为 nn 的由大小写英文字母或数字组成的字符串,请把这个字符串的所有非空后缀按字典序从小到大排序,然后按顺序输出后缀的第一个字符在原串中的位置.位置编 ...
- http请求常出现的状态码
服务器返回的 响应报文 中第一行为状态行,包含了状态码以及原因短语,用来告知客户端请求的结果. 状态码 类别 原因短语 1XX Informational(信息性状态码) 接收的请求正在处理 2XX ...
- HTML&CSS——网站注册页面
1.表单标签 所有需要提交到服务器端的表单项必须使用<form></form>括起来! form 标签属性: action,整个表单提交的位置(可以是一个页面,也可以是一个后 ...