python的jieba分词
# 官方例程
# encoding=utf-8
import jieba
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
输出:===============================
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
输出: ======================
【精确模式】: 我/ 来到/ 北京/ 清华大学
seg_list = jieba.cut("他来到了网易杭研大厦")
# 默认是精确模式
print(", ".join(seg_list))
输出:================
【新词识别】:他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了)
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
输出:=================================
【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
附上个人案例:
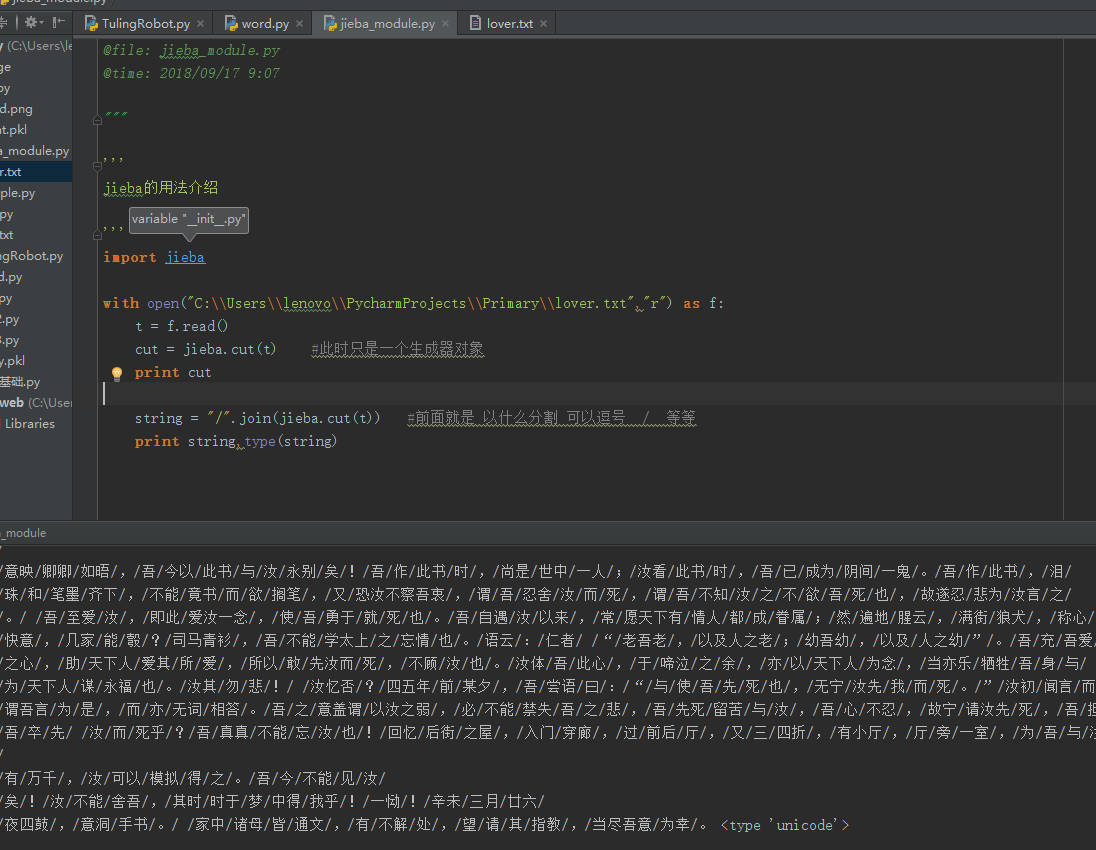
词云wordcloud+jieba+matplotlib做出漂亮的词云效果:
#!usr/bin/env python
#-*- coding:utf-8 _*-
"""
@author:wujf
@file: word.py
@time: 2018/09/14 10:05
必须要安装 matplotlib
"""
import sys
# default_encoding = 'utf-8'
# if sys.getdefaultencoding() != default_encoding:
# reload(sys)
# sys.setdefaultencoding(default_encoding)
import jieba
from wordcloud import WordCloud import matplotlib.pyplot as plt with open(r"C:\\Users\\lenovo\\PycharmProjects\\Primary\\lover.txt",'r') as f:
text = f.read() str = " ".join(jieba.cut(text)) print type(str) font = r"C:\\Windows\\Fonts\\微软雅黑\\msyhl.ttc" #这里一定要些win10电脑里面的中文字体,否则遇到中文字体分不出来
s = WordCloud(font_path=font,
background_color='black',
width=1200,
height=600
).generate(str)
s.to_file("cloud.png")
plt.imshow(s)
plt.axis("off")
plt.show()
效果图:

python的jieba分词的更多相关文章
- python结巴(jieba)分词
python结巴(jieba)分词 一.特点 1.支持三种分词模式: (1)精确模式:试图将句子最精确的切开,适合文本分析. (2)全模式:把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能解 ...
- python环境jieba分词的安装
我的python环境是Anaconda3安装的,由于项目需要用到分词,使用jieba分词库,在此总结一下安装方法. 安装说明======= 代码对 Python 2/3 均兼容 * 全自动安装:`ea ...
- Python使用jieba分词
# -*- coding: utf-8 -*- # Spyder (python 3.7) import pandas as pd import jieba import jieba.analyse ...
- python bottle + jieba分词服务
2019-12-16 19:46:34 星期一 最近接触到结巴分词项目, 就试试 用python的bottle库来当服务器监听localhost:8080 把请求的数据转给jieba来分词, 并返回分 ...
- Python之jieba分词
jieba,很有意思的一个模块,专门用来分词. import jieba # sentence:分割的中文字符串 # cut_all:是否采用全模式,默认为False表示精确模式 # HMM:表示是否 ...
- python安装Jieba中文分词组件并测试
python安装Jieba中文分词组件 1.下载http://pypi.python.org/pypi/jieba/ 2.解压到解压到python目录下: 3.“win+R”进入cmd:依次输入如下代 ...
- [python] 使用Jieba工具中文分词及文本聚类概念
声明:由于担心CSDN博客丢失,在博客园简单对其进行备份,以后两个地方都会写文章的~感谢CSDN和博客园提供的平台. 前面讲述了很多关于Python爬取本体Ontology.消息盒Inf ...
- Python自然语言处理学习——jieba分词
jieba——“结巴”中文分词是sunjunyi开发的一款Python中文分词组件,可以在Github上查看jieba项目. 要使用jieba中文分词,首先需要安装jieba中文分词,作者给出了如下的 ...
- $好玩的分词——python jieba分词模块的基本用法
jieba(结巴)是一个强大的分词库,完美支持中文分词,本文对其基本用法做一个简要总结. 安装jieba pip install jieba 简单用法 结巴分词分为三种模式:精确模式(默认).全模式和 ...
随机推荐
- ACdream 1735 输油管道
输油管道 Time Limit: 2000/1000MS (Java/Others) Memory Limit: 262144/131072KB (Java/Others) Problem Des ...
- Redis参数
phpredis是php的一个扩展,效率是相当高有链表排序功能,对创建内存级的模块业务关系 很有用;以下是redis官方提供的命令使用技巧: Redis::__construct构造函数$redis ...
- Remote Desktop安卓软件实现手机远程控制电脑
这篇文章写的是利用Remote Desktop安卓软件实现手机远程控制电脑. 电脑上的操作: 鼠标右击计算机>属性>远程设置>计算机名 如下图:
- 在Map对象中获取属性,注意判断为空
在Map对象中获取属性,注意判断为空 public static void main(String[] args) { Map map = new HashMap(); Integer i = (In ...
- UVa 10465 Homer Simpson(DP 全然背包)
题意 霍默辛普森吃汉堡 有两种汉堡 一中吃一个须要m分钟 还有一种吃一个须要n分钟 他共同拥有t分钟时间 要我们输出他在尽量用掉全部时间的前提下最多能吃多少个汉堡 假设时间无法用 ...
- Android訪问网络,使用HttpURLConnection还是HttpClient?
原文地址:http://android-developers.blogspot.com/2011/09/androids-http-clients.html 大多数的Android应用程序都会使用HT ...
- 某P2P开发商ERP系统核心业务介绍
之前说到.某软件公司卖P2P系统的后台管理系统.号称"ERP",今天继续说说这个ERP的核心业务. 业务1:贷款审批流程 贷款审批.主要是针对线下人员的 ...
- selenium找到页面元素click没反应
问题描述:通过调试可以看到控制台已经找到了起诉入口页面元素,可是点击“我是原告”没有反应了,也没有报错 解决办法:登录时是跳进了两层的iframe中,需要跳出iframe才能找到我是原告.
- 【Cocos2dx】资源目录,播放背景音乐,导入外部库
在Cocos2dx中播放背景音乐是一件非常easy的事情,就一行代码,可是首先要导入Cocos2dx的音频引擎cocosDenshion. cocosDenshion对cocos2dproject提供 ...
- Node.js:文件系统
ylbtech-Node.js:文件系统 1.返回顶部 1. Node.js 文件系统 Node.js 提供一组类似 UNIX(POSIX)标准的文件操作API. Node 导入文件系统模块(fs)语 ...