理解Java字符串常量池与intern()方法
String s1 = "Hello";
String s2 = "Hello";
String s3 = "Hel" + "lo";
String s4 = "Hel" + new String("lo");
String s5 = new String("Hello");
String s6 = s5.intern();
String s7 = "H";
String s8 = "ello";
String s9 = s7 + s8; System.out.println(s1 == s2); // true
System.out.println(s1 == s3); // true
System.out.println(s1 == s4); // false
System.out.println(s1 == s9); // false
System.out.println(s4 == s5); // false
System.out.println(s1 == s6); // true
刚开始看字符串的时候,经常会看到类似的题,难免会有些不解,查看答案总会提到字符串常量池、运行常量池等概念,很容易让人搞混。
下面就来说说Java中的字符串到底是怎样创建的。
Java内存区域
String有两种赋值方式,第一种是通过“字面量”赋值。
String str = "Hello";
String str = new String("Hello");
要弄清楚这两种方式的区别,首先要知道他们在内存中的存储位置。

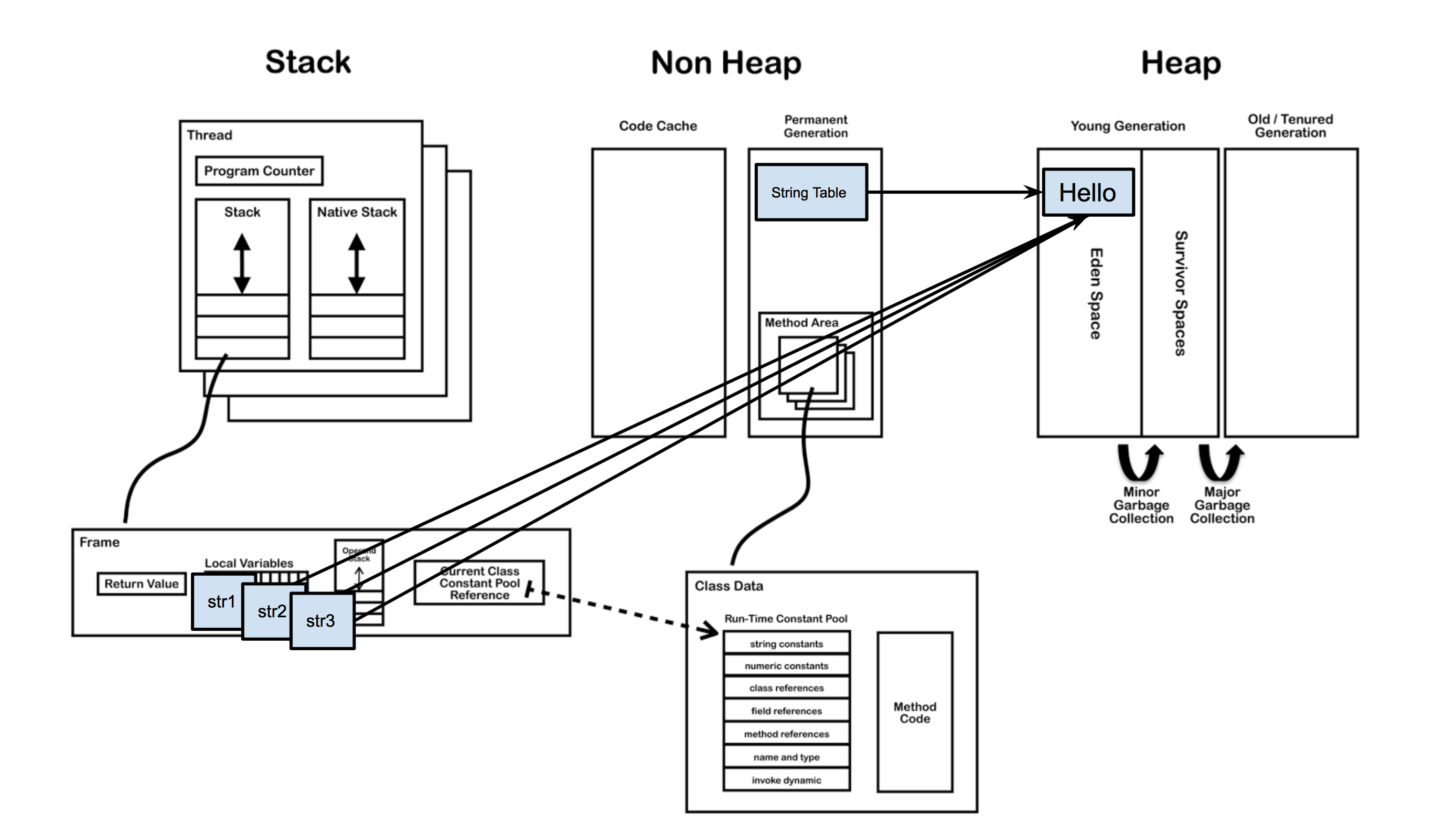
图片来源:http://286.iteye.com/blog/1928180
我们平时所说的内存就是图中的运行时数据区(Runtime Data Area),其中与字符串的创建有关的是方法区(Method Area)、堆区(Heap Area)和栈区(Stack Area)。
- 方法区:存储类信息、常量、静态变量。全局共享。
- 堆区:存放对象和数组。全局共享。
- 栈区:基本数据类型、对象的引用都存放在这。线程私有。
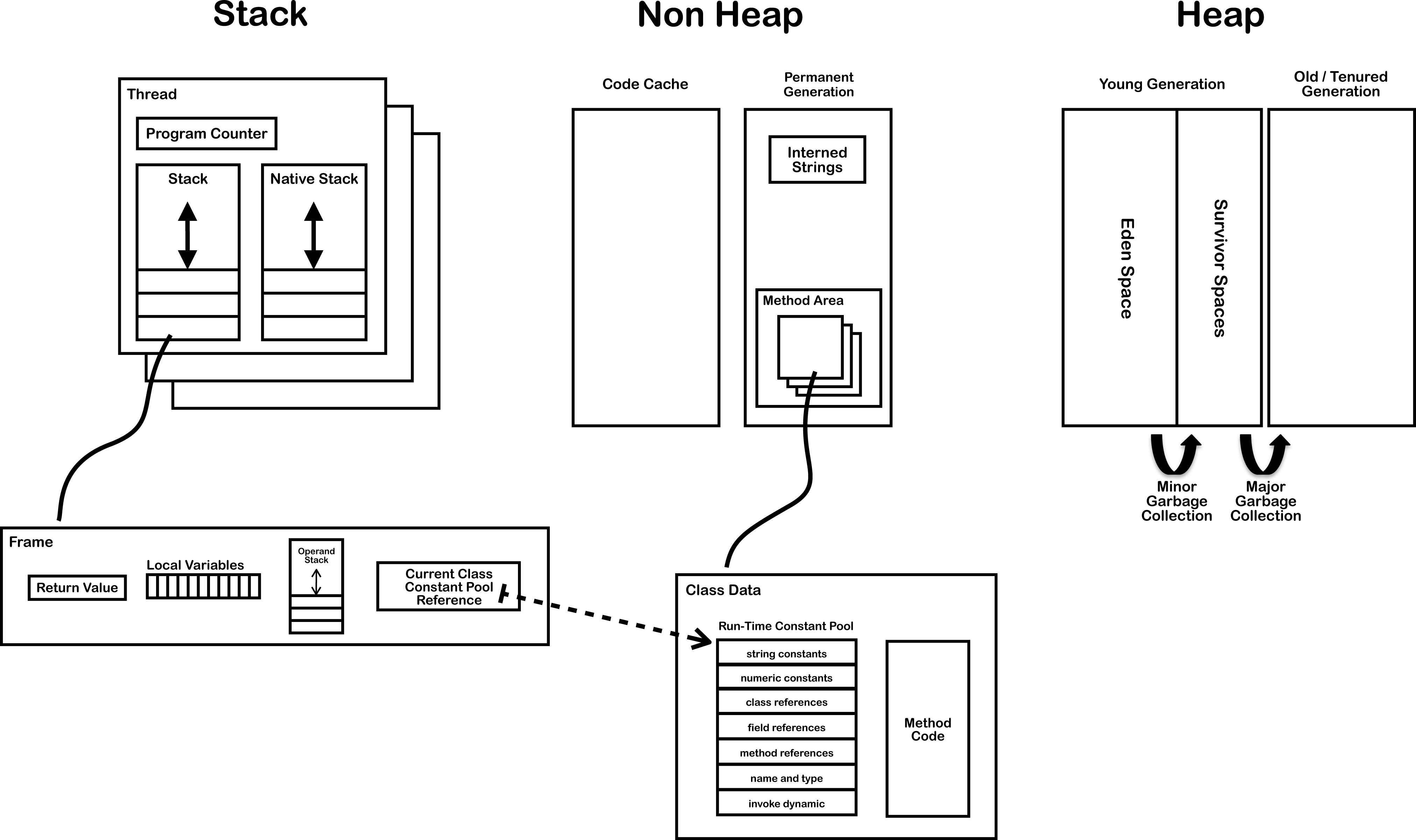
每当一个方法被执行时就会在栈区中创建一个栈帧(Stack Frame),基本数据类型和对象引用就存在栈帧中局部变量表(Local Variables)。
当一个类被加载之后,类信息就存储在非堆的方法区中。在方法区中,有一块叫做运行时常量池(Runtime Constant Pool),它是每个类私有的,每个class文件中的“常量池”被加载器加载之后就映射存放在这,后面会说到这一点。
和String最相关的是字符串池(String Pool),其位置在方法区上面的驻留字符串(Interned Strings)的位置,之前一直把它和运行时常量池搞混,其实是两个完全不同的存储区域,字符串常量池是全局共享的。字符串调用String.intern()方法后,其引用就存放在String Pool中。
两种创建方式在内存中的区别
了解了这些概念,下面来说说究竟两种字符串创建方式有何区别。
下面的Test类,在main方法里以“字面量”赋值的方式给字符串str赋值为“Hello”。
public class Test {
public static void main(String[] args) {
String str = "Hello";
}
}
Test.java文件编译后得到.class文件,里面包含了类的信息,其中有一块叫做常量池(Constant Pool)的区域,.class常量池和内存中的常量池并不是一个东西。
.class文件常量池主要存储的就包括字面量,字面量包括类中定义的常量,由于String是不可变的(String为什么是不可变的?),所以字符串“Hello”就存放在这。
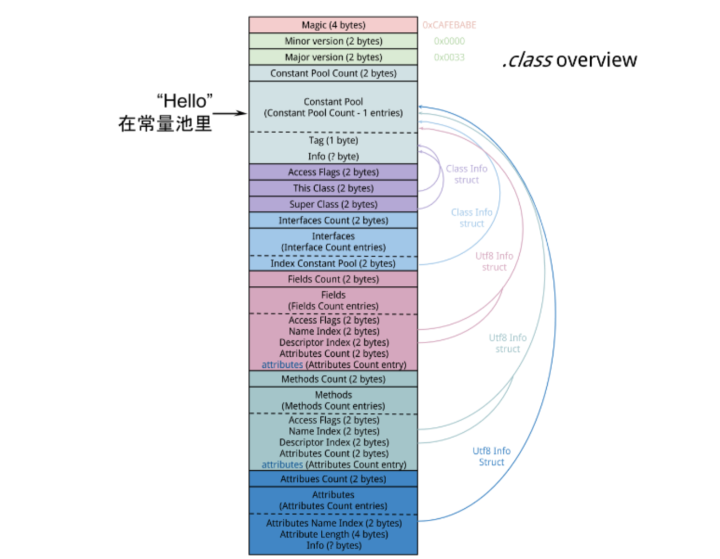
当程序用到Test类时,Test.class被解析到内存中的方法区。.class文件中的常量池信息会被加载到运行时常量池,但String不是。
例子中“Hello”会在堆区中创建一个对象,同时会在字符串池(String Pool)存放一个它的引用,如下图所示。
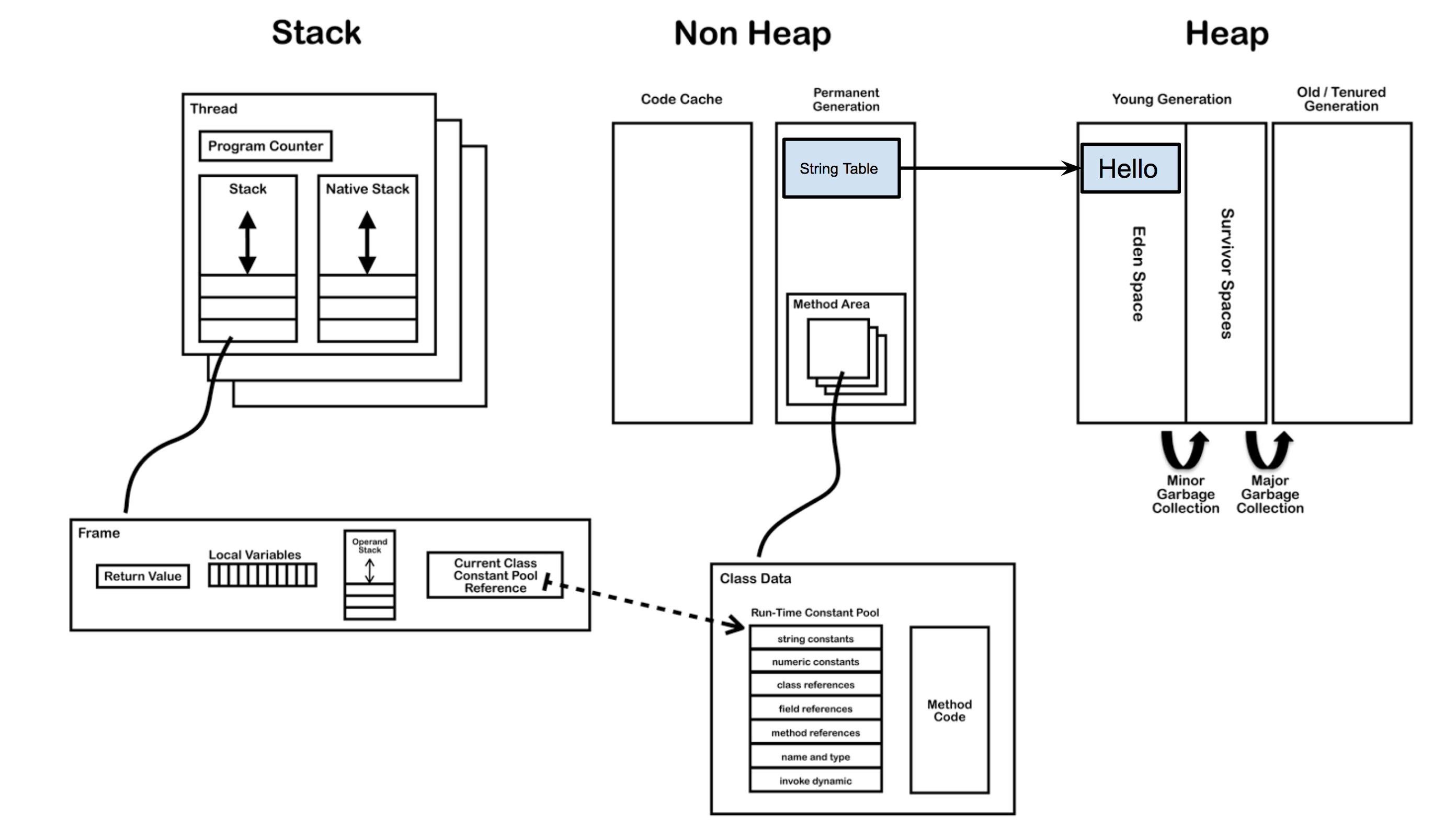
此时只是Test类刚刚被加载,主函数中的str并没有被创建,而“Hello”对象已经创建在于堆中。
当主线程开始创建str变量的,虚拟机会去字符串池中找是否有equals(“Hello”)的String,如果相等就把在字符串池中“Hello”的引用复制给str。如果找不到相等的字符串,就会在堆中新建一个对象,同时把引用驻留在字符串池,再把引用赋给str。
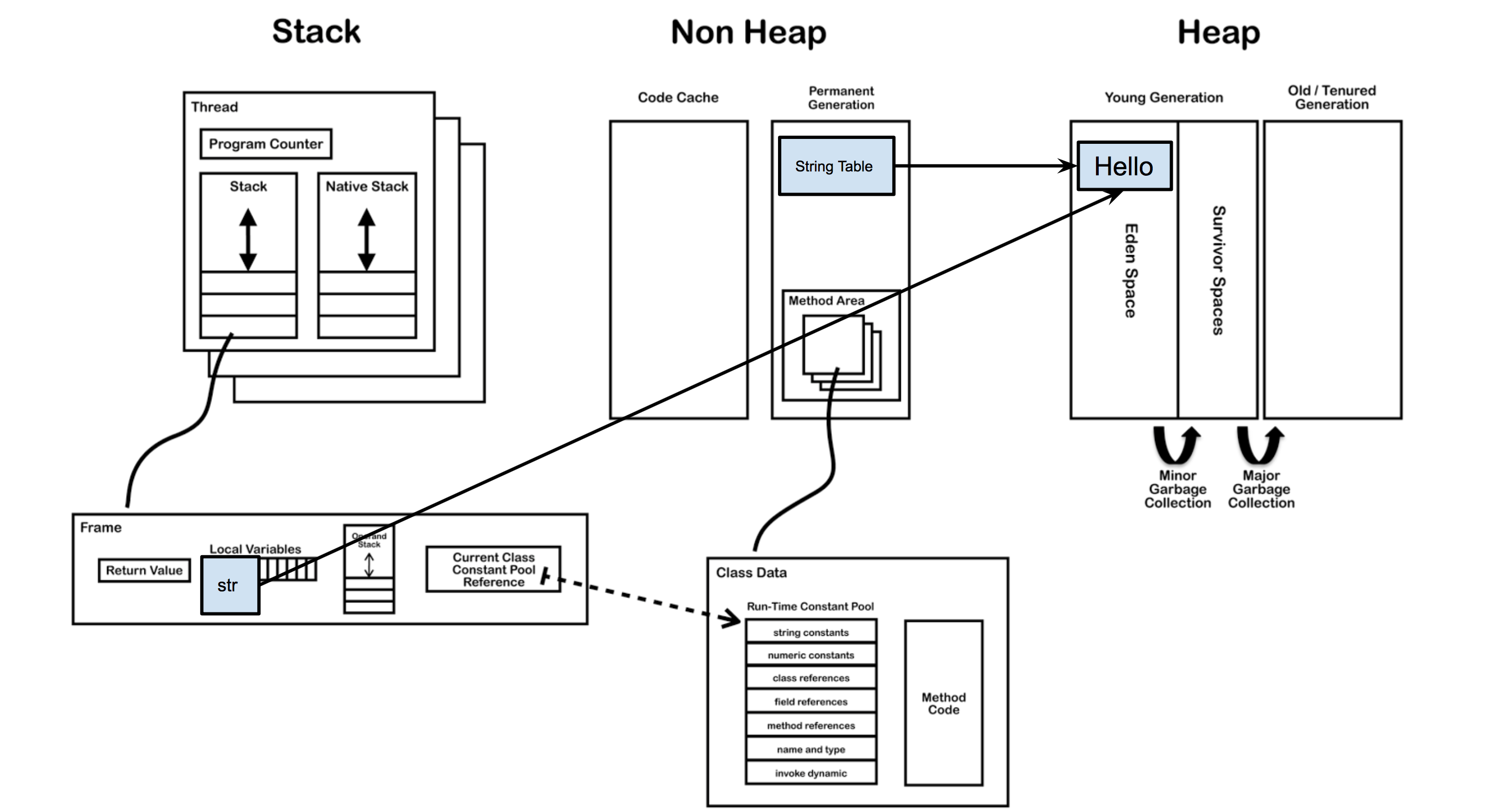
当用字面量赋值的方法创建字符串时,无论创建多少次,只要字符串的值相同,它们所指向的都是堆中的同一个对象。
public class Test {
public static void main(String[] args) {
String str1 = "Hello";
String str2 = “Hello”;
String str3 = “Hello”;
}
}
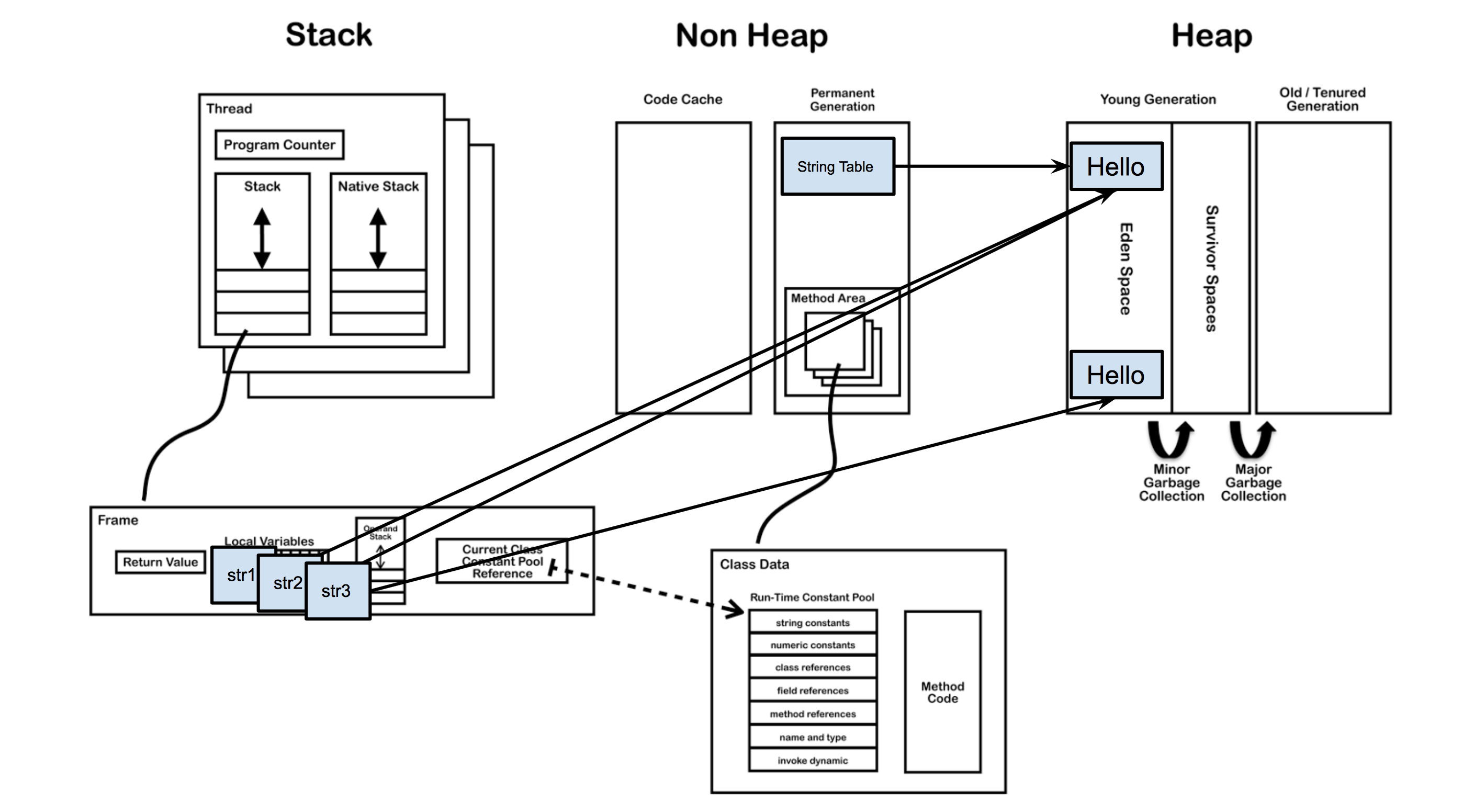
当利用new关键字去创建字符串时,前面加载的过程是一样的,只是在运行时无论字符串池中有没有与当前值相等的对象引用,都会在堆中新开辟一块内存,创建一个对象。
public class Test {
public static void main(String[] args) {
String str1 = "Hello";
String str2 = “Hello”;
String str3 = new String("Hello");
}
}
解释开头的例子
现在我们来回头看之前的例子。
String s1 = "Hello";
String s2 = "Hello";
String s3 = "Hel" + "lo";
String s4 = "Hel" + new String("lo");
String s5 = new String("Hello");
String s6 = s5.intern();
String s7 = "H";
String s8 = "ello";
String s9 = s7 + s8; System.out.println(s1 == s2); // true
System.out.println(s1 == s3); // true
System.out.println(s1 == s4); // false
System.out.println(s1 == s9); // false
System.out.println(s4 == s5); // false
System.out.println(s1 == s6); // true
有了上面的基础,之前的问题就迎刃而解了。
s1在创建对象的同时,在字符串池中也创建了其对象的引用。
由于s2也是利用字面量创建,所以会先去字符串池中寻找是否有相等的字符串,显然s1已经帮他创建好了,它可以直接使用其引用。那么s1和s2所指向的都是同一个地址,所以s1==s2。
s3是一个字符串拼接操作,参与拼接的部分都是字面量,编译器会进行优化,在编译时s3就变成“Hello”了,所以s1==s3。
s4虽然也是拼接,但“lo”是通过new关键字创建的,在编译期无法知道它的地址,所以不能像s3一样优化。所以必须要等到运行时才能确定,必然新对象的地址和前面的不同。
同理,s9由两个变量拼接,编译期也不知道他们的具体位置,不会做出优化。
s5是new出来的,在堆中的地址肯定和s4不同。
s6利用intern()方法得到了s5在字符串池的引用,并不是s5本身的地址。由于它们在字符串池的引用都指向同一个“Hello”对象,自然s1==s6。
总结一下:
- 字面量创建字符串会先在字符串池中找,看是否有相等的对象,没有的话就在堆中创建,把地址驻留在字符串池;有的话则直接用池中的引用,避免重复创建对象。
- new关键字创建时,前面的操作和字面量创建一样,只不过最后在运行时会创建一个新对象,变量所引用的都是这个新对象的地址。
由于不同版本的JDK内存会有些变化,JDK1.6字符串常量池在永久代,1.7移到了堆中,1.8用元空间代替了永久代。但是基本对上面的结论没有影响,思想是一样的。
intern()方法
下面来说说跟字符常量池有关的intern()方法。
/**
* Returns a canonical representation for the string object.
* <p>
* A pool of strings, initially empty, is maintained privately by the
* class {@code String}.
* <p>
* When the intern method is invoked, if the pool already contains a
* string equal to this {@code String} object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this {@code String} object is added to the
* pool and a reference to this {@code String} object is returned.
* <p>
* It follows that for any two strings {@code s} and {@code t},
* {@code s.intern() == t.intern()} is {@code true}
* if and only if {@code s.equals(t)} is {@code true}.
* <p>
* All literal strings and string-valued constant expressions are
* interned. String literals are defined in section 3.10.5 of the
* <cite>The Java™ Language Specification</cite>.
*
* @return a string that has the same contents as this string, but is
* guaranteed to be from a pool of unique strings.
*/
public native String intern();
这个方法是一个本地方法,注释中描述得很清楚:“如果常量池中存在当前字符串,就会直接返回当前字符串;如果常量池中没有此字符串,会将此字符串放入常量池中后,再返回”。
由于上面提到JDK1.6之后,字符串常量池在内存中的位置发生了变化,所以intern()方法在不同版本的JDK中也有所差别。
来看下面的代码:
public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
在JDK1.6中的运行结果是false false,而在1.7中结果是false true。
将intern()语句下移一行。
public static void main(String[] args) {
String s = new String("1");
String s2 = "1";
s.intern();
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
String s4 = "11";
s3.intern();
System.out.println(s3 == s4);
}
在JDK1.6中的运行结果是false false,在1.7中结果也是false false。
下面来解释一下JDK1.6环境下的结果:

图中绿色线条代表string对象的内容指向,黑色线条代表地址指向。
JDK1.6中的intern()方法只是返回常量池中的引用,上面说过,常量池中的引用所指向的对象和new出来的对象并不是一个,所以他们的地址自然不相同。
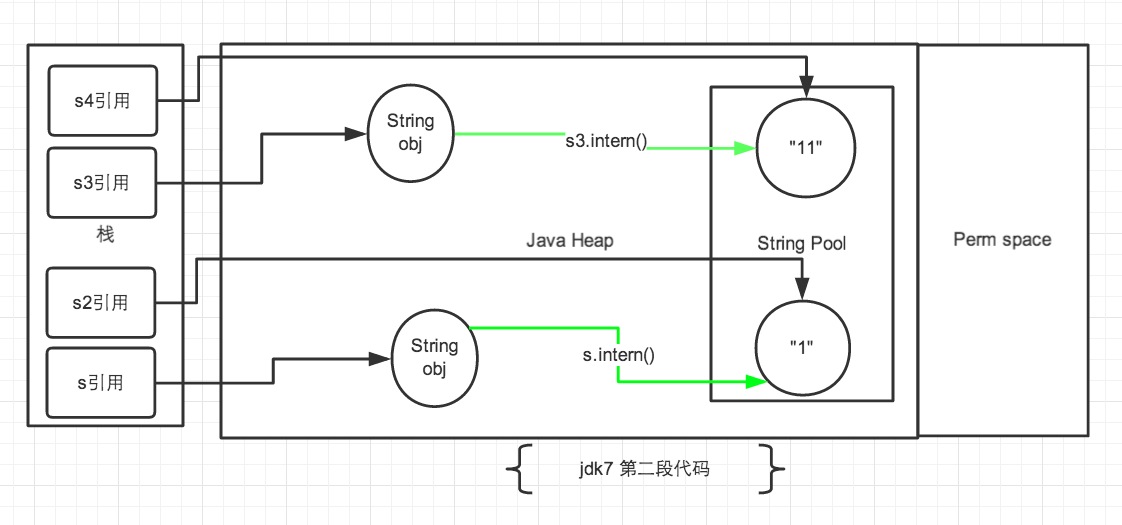
接着来说一下JDK1.7:
再贴一下代码
public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
创建s3生成了两个最终对象(不考虑两个new String("1"),常量池中也没有“11”),一个是s3,另一个是池中的“1”。如果在1.6中,s3调用intern()方法,则先在常量池中寻找是否有等于“11”的对象,本例中自然是没有,然后会在堆中创建一个“11”的对象,并在常量池中存储它的引用并返回。然而在1.7中调用intern(),如果这个字符串在常量池中是第一次出现,则不会重新创建对象,直接返回它在堆中的引用。在本例中,s4和s3指向的都是在堆中的那个对象,所以s3和s4的地址相等。
由于s是new出来的,所以会在常量池和堆中创建两个不同的对象,s.intern()后,发现“1”并不是第一次出现在常量池了,所以接下来就和之前没有区别了。
public static void main(String[] args) {
String s = new String("1");
String s2 = "1";
s.intern();
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
String s4 = "11";
s3.intern();
System.out.println(s3 == s4);
}
将intern()语句下移一行后,执行顺序发生改变,执行到intern()时,字符串常量池已经存在“1”和“11”了,并不是第一次出现,字面量对象依然指向的是常量池,所以字面量创建的对象和new的对象地址一定是不同的。
转载请注明原文链接:http://www.cnblogs.com/justcooooode/p/7603381.html
参考资料
https://www.zhihu.com/question/29884421/answer/113785601
http://www.cnblogs.com/iyangyuan/p/4631696.html
https://tech.meituan.com/in_depth_understanding_string_intern.html
https://javaranch.com/journal/200409/ScjpTipLine-StringsLiterally.html ——【译】Java中的字符串字面量
理解Java字符串常量池与intern()方法的更多相关文章
- 深入理解JAVA字符串常量池
初学JAVA时,在学习如何比较两个字符串是否相等,大量资料告诉我,不能用等于号( = )去比较,需要使用equals方法,理由是String是一个对象,等号此时比较的是两个字符串在java内存堆中的地 ...
- Java字符串常量池及字符串判等解析
一.理解"=="的含义 "=="常用于两个对象的判等操作,在Java中,"=="主要有以下两种用法: 1.基础数据类型:比较的是他们的值是否 ...
- Java字符串常量池是什么?为什么要有这种常量池?
简单介绍 Java中的字符串常量池(String Pool)是存储在Java堆内存中的字符串池.我们知道String是java中比较特殊的类,我们可以使用new运算符创建String对象,也可以用双引 ...
- 看完肯定懂的 Java 字符串常量池指南
字符串问题可谓是 Java 中经久不衰的问题,尤其是字符串常量池经常作为面试题出现.可即便是看似简单而又经常被提起的问题,还是有好多同学一知半解,看上去懂了,仔细分析起来却又发现不太明白. 背景说明 ...
- 结合字符串常量池/String.intern()/String Table来谈一下你对java中String的理解
1.字符串常量池 每创建一个字符串常量,JVM会首先检查字符串常量池,如果字符串已经在常量池中存在,那么就返回常量池中的实例引用.如果字符串不在池中,就会实例化一个字符串放到字符串池中.常量池提高了J ...
- java字符串常量池——字符串==比较的一个误区
转自:https://blog.csdn.net/wxz980927155/article/details/81712342 起因 再一次js的json对象的比较中,发现相同内容的json对象使用 ...
- 常量池之字符串常量池String.intern()
运行时常量池是方法区(PermGen)的一部分. 需要提前了解: 1. JVM内存模型. 2. JAVA对象在JVM中内存分配 常量池的好处 常量池是为了避免频繁的创建和销毁对象而影响系统性能,其实现 ...
- String常量池和intern方法
String s1 = "Hello"; String s2 = "Hello"; String s3 = "Hel" + "lo ...
- [JAVA]字符串常量池String pool
字符串常量池(String Pool)保存着所有字符串字面量(literal strings),这些字面量在编译时期就确定.不仅如此,还可以使用 String 的 intern() 方法在运行过程中将 ...
随机推荐
- Js里面的arguments
了解这个对象之前先来认识一下javascript的一些功能: 其实Javascript并没有重载函数的功能,但是Arguments对象能够模拟重载.Javascrip中国每个函数都会有一个Argume ...
- (转)oracle表空间使用率统计查询
转自:http://www.cnblogs.com/xwdreamer/p/3511047.html 参考文献 文献1:http://blog.itpub.net/24104518/viewspace ...
- Windows 7 Ultimate with SP1(x64) MSDN 官方简体中文旗舰版原版
Windows 7 Ultimate(旗舰版)64位功能齐全,所有其他版本所具有的高级功能它都有!它是最好的Windows 7操作系统.旗舰版很受网友欢迎,下载速度飞快. MSDN 我告诉你下载官网: ...
- 【Codeforces Round #434 (Div. 2) B】Which floor?
[链接]h在这里写链接 [题意] 在这里写题意 [题解] 枚举每层有多少个公寓就好. 要注意,每次都要从1到100判断,一下那个公寓该不该出现在那一层. 多个答案,如果答案是一样的.也算是唯一的. ...
- [D3] Modify DOM Elements with D3 v4
Once you can get hold of DOM elements you’re ready to start changing them. Whether it’s changing col ...
- 9.7 Binder系统_c++实现_编写程序
参考文件:frameworks\av\include\media\IMediaPlayerService.h (IMediaPlayerService,BnMediaPlayerService)fra ...
- [Nuxt] Navigate with nuxt-link and Customize isClient Behavior in Nuxt and Vue.js
Because Nuxt renders pages on the server, you should use the nuxt-link components to navigate betwee ...
- h5 video 点击自动全屏
加上如下属性 https://blog.csdn.net/weixin_40974504/article/details/79639478 可阻止自动全屏播放,感谢 https://blog.csdn ...
- MinGW、MinGW-w64 与TDM-GCC 应该如何选择?
MinGW.MinGW-w64 与TDM-GCC 应该如何选择? https://www.zhihu.com/question/39952667
- libiconv库链接问题一则
https://blog.csdn.net/jeson2090/article/details/54632063 出现过glibc中的iconv_open返回EINVAL,原因猜测是有些字符集转换不支 ...