Pyspider爬虫简单框架——链家网
pyspider
目录
pyspider简单介绍
一个国人编写的强大的网络爬虫系统并带有强大的WebUI。采用Python语言编写,分布式架构,支持多种数据库后端,
强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器
官方文档: http://docs.pyspider.org/en/latest/
开源地址: http://github.com/binux/pyspider
中文文档: http://www.pyspider.cn/
pyspider框架的特性
- python脚本控制,可以使用用任何你喜欢的html解析包(内置pyquery)
- WEB界面编写调试脚本,启停脚本,监控执行状态,查看活动内容,获取结果产出
- 数据库存储支持MySQl,MongoDB,Redis,SQLite,Elasticsearch,PostgreSQL及SQLAlchemy
- 队列服务支持RabbitMQ,Beanstalk,Redis和Kombu
- 支持抓取JavaScript的页面
- 组件可替换,支持单机/分布式部署,支持Docker的部署
- 强大的调度控制,支持超时重爬及优先级设置
- 支持python2&3
pyspider的安装
pip install pyspider
- 安装完成后运行,在cmd窗口输入pyspider

pyspider的使用:
- 在浏览器中输入最后一行的IP和端口号。
- 在web控制台点create按钮新建项目。

- 保存后打开代码编辑器(代码编辑器默认有简单的示例代码)
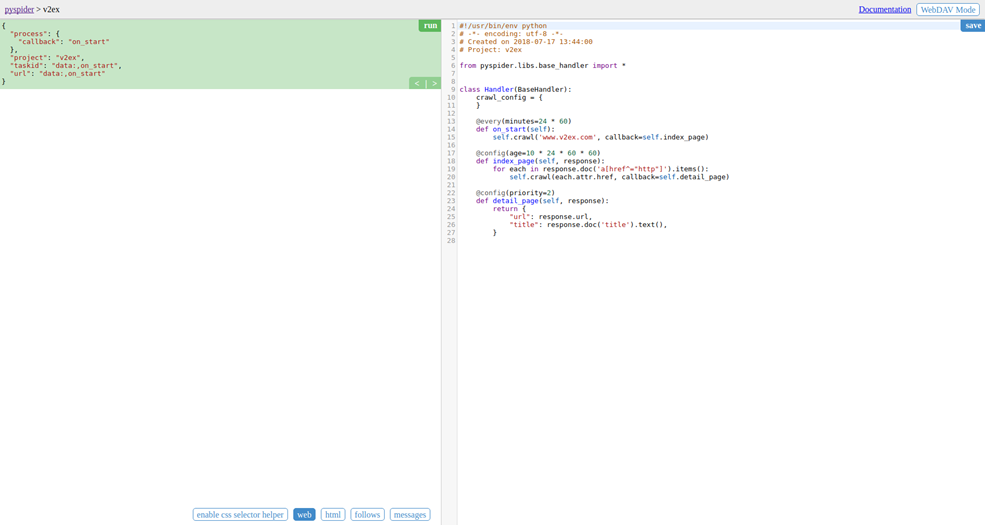
- 右侧就是代码编辑器,,以后可以直接在这里添加和修改代码。代码如下:

代码分析:
- def on_start(self)方法是入口代码。当在web控制台点击run按钮时会执行此方法。
- self.crawl(url, callback=self.index_page)这个方法是调用API生成一个新的爬虫任务,这个任务被添加到待爬取队列
- def index_page(self.response)这个方法获取一个response对象。response.doc是pyquery对象的一个扩展方法。pyquery是一个类似于jquery的对象选择器。
- def detail_page(self, response)返回一个结果即对象。这个结果默认会被添加到resultdb数据库(如果启动时没有指定数据库默认调用sqlite数据库)。也可以重写on_result(self, result) 方法来指定保存位置。

- 当完成脚本编写,调试无误后,请先保存脚本,然后返回控制台首页
- 直接点击项目状态status那栏,把状态由TTODO改成debug或running
- 最后点击项目最右边那个RUN按钮启动项目

- 当progress那栏有数据显示说明启动成功。就可以点击右侧的result查看结果了
技巧:
- pyspider访问https协议得网站是,会提示证书问题,需要设置validate_cert = False,屏蔽证书验证
- 预览网页得时候,可能会出现空白页面,是因为pysipder不加载JavaScript代码,用fetch_type='js',pyspider会自动调用phantomjs来渲染网页。前提是电脑上已经安装了phantomls.exe插件
- 当需要删除项目时,将status状态改成STOP,再将group写上delete,pyspider默认在STOP的delete状态下保存24小时后删除

enable css selector helper可以在点击了web 的网页预览下,获取网页的css选择器

点击图片箭头的按键,就会生成对应css选择器在光标所在的位置处
- follows是根据代码请求所跟进的url链接,点击
 实现网页跳转
实现网页跳转 - 当代码调试出错的时候,要回到最初的首页开始重新调试

实战
爬取链家网的信息:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-11-02 10:54:11
# Project: ddd from pyspider.libs.base_handler import * class Handler(BaseHandler):
crawl_config = {
} @every(minutes=24 * 60) # 设置爬取的时间间隔
def on_start(self):
self.crawl('https://cs.lianjia.com/ershoufang/', callback=self.index_page, validate_cert = False) # 参数三是设置不验证ssl证书 @config(age=10 * 24 * 60 * 60) # 过期时间
def index_page(self, response):
for each in response.doc('.title > a').items():
self.crawl(each.attr.href, callback=self.detail_page, validate_cert = False) @config(priority=2) # 优先级 数大极高
def detail_page(self, response):
yield {
'title': response.doc('.main').text(),
'special': response.doc('.tags > .content').text(),
'price': response.doc('.price > .total').text(),
'sell point': response.doc('.baseattribute > .content').text()
}
结果:分别爬取了卖房的标题(title),特点(special),卖点(sell point)和价格(price),因为字典保存,所以无序

Pyspider爬虫简单框架——链家网的更多相关文章
- python链家网高并发异步爬虫asyncio+aiohttp+aiomysql异步存入数据
python链家网二手房异步IO爬虫,使用asyncio.aiohttp和aiomysql 很多小伙伴初学python时都会学习到爬虫,刚入门时会使用requests.urllib这些同步的库进行单线 ...
- python链家网高并发异步爬虫and异步存入数据
python链家网二手房异步IO爬虫,使用asyncio.aiohttp和aiomysql 很多小伙伴初学python时都会学习到爬虫,刚入门时会使用requests.urllib这些同步的库进行单线 ...
- 分享系列--面试JAVA架构师--链家网
本月7日去了一趟链家网面试,虽然没有面上,但仍有不少收获,在此做个简单的分享,当然了主要是分享给自己,让大家见笑了.因为这次是第一次面试JAVA网站架构师相关的职位,还是有些心虚的,毕竟之前大部分时间 ...
- TOP100summit:【分享实录】链家网大数据平台体系构建历程
本篇文章内容来自2016年TOP100summit 链家网大数据部资深研发架构师李小龙的案例分享. 编辑:Cynthia 李小龙:链家网大数据部资深研发架构师,负责大数据工具平台化相关的工作.专注于数 ...
- Python的scrapy之爬取链家网房价信息并保存到本地
因为有在北京租房的打算,于是上网浏览了一下链家网站的房价,想将他们爬取下来,并保存到本地. 先看链家网的源码..房价信息 都保存在 ul 下的li 里面 爬虫结构: 其中封装了一个数据库处理模 ...
- Scrapy实战篇(一)之爬取链家网成交房源数据(上)
今天,我们就以链家网南京地区为例,来学习爬取链家网的成交房源数据. 这里推荐使用火狐浏览器,并且安装firebug和firepath两款插件,你会发现,这两款插件会给我们后续的数据提取带来很大的方便. ...
- 使用python抓取并分析数据—链家网(requests+BeautifulSoup)(转)
本篇文章是使用python抓取数据的第一篇,使用requests+BeautifulSoup的方法对页面进行抓取和数据提取.通过使用requests库对链家网二手房列表页进行抓取,通过Beautifu ...
- Scrapy实战篇(九)之爬取链家网天津租房数据
以后有可能会在天津租房子,所以想将链家网上面天津的租房数据抓下来,以供分析使用. 思路: 1.以初始链接https://tj.lianjia.com/zufang/rt200600000001/?sh ...
- python - 爬虫入门练习 爬取链家网二手房信息
import requests from bs4 import BeautifulSoup import sqlite3 conn = sqlite3.connect("test.db&qu ...
随机推荐
- document.getElementById方法在火狐和谷歌浏览器兼容
转自:http://www.office68.com/computer/6505.html 对于前台设计,浏览不兼容是一个很头晕的事情,为此记录下来与大家分享,并供日后自己参考. 例:有一个名为pwd ...
- uoj#34
模板 #include<bits/stdc++.h> #define pi acos(-1) using namespace std; ; int n, m, L, x; int r[N] ...
- Secure CRT中解决vim高亮设置的方法
此文主要是解决vim编程中高亮显示的.原因是: 1.默认情况下,SecureCRT是有自己的终端显示颜色.这样在我们编程中不利于阅读内容. 2.我们必须到Linux系统中进行改进才能真正解决这样的问题 ...
- 记录第一次在egret项目中使用Puremvc
这几天跟着另一个前端在做一个小游戏,使用的是egret引擎和puremvc框架,这对于我来说还是个比较大的突破吧,特此记录下. 因为在此项目中真是的用到了mvc及面向对象编程,值得学习 记录第一次在e ...
- 【NOIP练习赛】学习
[NOIP练习赛]T3.学习 Description 巨弱小 D 准备学习,有 n 份学习资料给他看,每份学习资料的 内容可以用一个正整数 ai 表示.小 D 如果在一天内学习了多份资料, 他只能记住 ...
- 下载谷歌地图封锁IP解决办法
采用重新拨号,动态改变IP的方式.可以使用软件<易好用IP自动更换软件>
- STMP服务器发送邮件,本地可以发送但是服务器一直发送不成功;
在官网上查看到信息 考虑到部分云服务商封禁了其内网对外 25 端口的访问, xxxxx 端口号: 2525 xxxxx 端口号: 587 然后,我换了一下端口号就行了,浪费了我三个小时时间,贼尴尬:
- JdbcTemplate:Jdbc模板和数据库元数据
通过 Jdbc .C3P0 .Druid 的使用我们会发现即使我们做了工具的封装,但重复性的代码依旧很多.我们可以通过 JdbcTemplate 即 Jdbc 模板来使我们的代码更加简洁,逻辑更加清晰 ...
- Laravel5.1学习笔记17 数据库3 数据迁移
介绍 建立迁移文件 迁移文件结构 执行迁移 回滚迁移 填写迁移文件 创建表 重命名/ 删除表 创建字段 修改字段 删除字段 建立索引 删除索引 外键约束 #介绍 Migrations are lik ...
- 原生js实现简单的焦点图效果
用到一些封装好的运动函数,主要是定时器 效果为图片和图片的描述定时自动更换 <!DOCTYPE html> <html> <head> <meta chars ...