Spark MLlib回归算法LinearRegression
算法说明
线性回归是利用称为线性回归方程的函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析方法,只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归,在实际情况中大多数都是多元回归。
线性回归(Linear Regression)问题属于监督学习(Supervised Learning)范畴,又称分类(Classification)或归纳学习(Inductive Learning)。这类分析中训练数据集中给出的数据类型是确定的。机器学习的目标是,对于给定的一个训练数据集,通过不断的分析和学习产生一个联系属性集合和类标集合的分类函数(Classification Function)或预测函数)Prediction Function),这个函数称为分类模型(Classification Model——或预测模型(Prediction Model)。通过学习得到的模型可以是一个决策树、规格集、贝叶斯模型或一个超平面。通过这个模型可以对输入对象的特征向量预测或对对象的类标进行分类。
回归问题中通常使用最小二乘(Least Squares)法来迭代最优的特征中每个属性的比重,通过损失函数(Loss Function)或错误函数(Error Function)定义来设置收敛状态,即作为梯度下降算法的逼近参数因子。
实例介绍
该例子给出了如何导入训练集数据,将其解析为带标签点的RDD,然后使用了LinearRegressionWithSGD 算法来建立一个简单的线性模型来预测标签的值,最后计算了均方差来评估预测值与实际值的吻合度。
线性回归分析的整个过程可以简单描述为如下三个步骤:
(1)寻找合适的预测函数,即上文中的 h(x) ,用来预测输入数据的判断结果。这个过程是非常关键的,需要对数据有一定的了解或分析,知道或者猜测预测函数的“大概”形式,比如是线性函数还是非线性函数,若是非线性的则无法用线性回归来得出高质量的结果。
(2)构造一个Loss函数(损失函数),该函数表示预测的输出(h)与训练数据标签之间的偏差,可以是二者之间的差(h-y)或者是其他的形式(如平方差开方)。综合考虑所有训练数据的“损失”,将Loss求和或者求平均,记为 J(θ) 函数,表示所有训练数据预测值与实际类别的偏差。
(3)显然, J(θ) 函数的值越小表示预测函数越准确(即h函数越准确),所以这一步需要做的是找到 J(θ) 函数的最小值。找函数的最小值有不同的方法,Spark中采用的是梯度下降法(stochastic gradient descent,SGD)。
程序代码
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.mllib.regression.LinearRegressionWithSGD
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.linalg.Vectors
object LinearRegression {
def main(args:Array[String]): Unit ={
// 屏蔽不必要的日志显示终端上
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
// 设置运行环境
val conf = new SparkConf().setAppName("Kmeans").setMaster("local[4]")
val sc = new SparkContext(conf)
// Load and parse the data
val data = sc.textFile("/home/hadoop/upload/class8/lpsa.data")
val parsedData = data.map { line =>
val parts = line.split(',')
LabeledPoint(parts().toDouble, Vectors.dense(parts().split(' ').map(_.toDouble)))
}
// Building the model
val numIterations =
val model = LinearRegressionWithSGD.train(parsedData, numIterations)
// Evaluate model on training examples and compute training error
val valuesAndPreds = parsedData.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
val MSE = valuesAndPreds.map{ case(v, p) => math.pow((v - p), )}.reduce (_ + _) / valuesAndPreds.count
println("training Mean Squared Error = " + MSE)
sc.stop()
}
}
执行情况
第一步 启动Spark集群
$cd /app/hadoop/spark-1.1. $sbin/start-all.sh
第二步 在IDEA中设置运行环境
在IDEA运行配置中设置LinearRegression运行配置,由于读入的数据已经在程序中指定,故在该设置界面中不需要设置输入参数
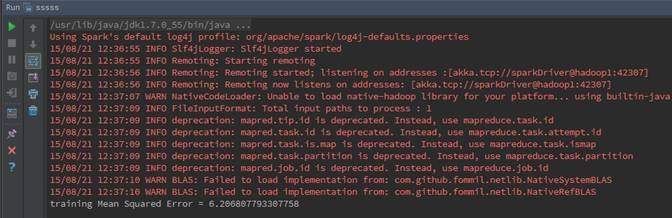
第三步 执行并观察输出
Spark MLlib回归算法LinearRegression的更多相关文章
- Spark MLlib回归算法------线性回归、逻辑回归、SVM和ALS
Spark MLlib回归算法------线性回归.逻辑回归.SVM和ALS 1.线性回归: (1)模型的建立: 回归正则化方法(Lasso,Ridge和ElasticNet)在高维和数据集变量之间多 ...
- spark mllib k-means算法实现
package iie.udps.example.spark.mllib; import java.util.regex.Pattern; import org.apache.spark.SparkC ...
- Spark MLlib基本算法【相关性分析、卡方检验、总结器】
一.相关性分析 1.简介 计算两个系列数据之间的相关性是统计中的常见操作.在spark.ml中提供了很多算法用来计算两两的相关性.目前支持的相关性算法是Pearson和Spearman.Correla ...
- Spark 实践——基于 Spark MLlib 和 YFCC 100M 数据集的景点推荐系统
1.前言 上接 YFCC 100M数据集分析笔记 和 使用百度地图api可视化聚类结果, 在对 YFCC 100M 聚类出的景点信息的基础上,使用 Spark MLlib 提供的 ALS 算法构建推荐 ...
- FP-Growth in Spark MLLib
并行FP-Growth算法思路 上图的单线程形成的FP-Tree. 分布式算法事实上是对FP-Tree进行分割,分而治之 首先,假设我们只关心...|c这个conditional transactio ...
- Spark MLlib架构解析(含分类算法、回归算法、聚类算法和协同过滤)
Spark MLlib架构解析 MLlib的底层基础解析 MLlib的算法库分析 分类算法 回归算法 聚类算法 协同过滤 MLlib的实用程序分析 从架构图可以看出MLlib主要包含三个部分: 底层基 ...
- Spark Mllib逻辑回归算法分析
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3816289.html 本文以spark 1.0.0版本MLlib算法为准进行分析 一.代码结构 逻辑回归 ...
- Spark机器学习(3):保序回归算法
保序回归即给定了一个无序的数字序列,通过修改其中元素的值,得到一个非递减的数字序列,要求是使得误差(预测值和实际值差的平方)最小.比如在动物身上实验某种药物,使用了不同的剂量,按理说剂量越大,有效的比 ...
- 梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python)
梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python) http://blog.csdn.net/liulingyuan6/article/details ...
随机推荐
- 射击的乐趣:WIN32诠释打飞机游戏
一楼留给链接http://blog.csdn.net/crocodile__/article/details/11860129 楼上神贴,膜拜片刻...... 一.游戏玩法和已经实现的功能 1.打开游 ...
- PHP接收GET中文参数乱码的原因及解决方案
方案1: $str = iconv("gb2312","utf-8",$str); 方案2: mb_convert_encoding($str, "u ...
- 【Git 四】一款不错的 Git 客户端
平常做开发使用 git bash 进行代码提交,一直没有使用过 git 相关的客户端. 直到有次同一分支下两个日志进行代码比较时,bash 返回的结果可视化理解起来比较差. 如果更改的部分比较多,问题 ...
- centOS7下 安装nodejs+nginx+mongodb+pm2部署vue项目
一.购买服务器并远程连接 1.购买服务器和域名 可以选择阿里云或者是其他的厂商的服务器.然后会获得服务器ip地址,用户名和密码. 购买域名,将域名绑定到ip地址上. 2.下载xshell,winscp ...
- shell清除日志小脚本
#!/bin/bash #清除日志脚本 LOG_DIR=/var/log ROOT_UID=0 #用户id为0的 ,即为root if [ "$UID" -ne "$RO ...
- 【IDEA】Error: java: Compliance level '1.6' is incompatible with target level '1.8'. A compliance level '1.8' or better is required解决办法
在运行的时候常常出现如下错误: Error: java: Compliance level '1.6' is incompatible with target level '1.8'. A compl ...
- Qt之图形(绘制文本)
简述 前面我们讲解了Qt图形的基本绘制,其中包括: 绘制文本.直线.直线.矩形.弧线.椭圆.多边形.图片,以及其它一些高级用法,比如:渐变.转换等. 本节我们来详细讲解文字的绘制.主要通过QPaint ...
- cocos2d-x 2.2.0 怎样在lua中注冊回调函数给C++
cocos2d-x内部使用tolua进行lua绑定.可是引擎并没有提供一个通用的接口让我们能够把一个lua函数注冊给C++层面的回调事件. 翻看引擎的lua绑定代码,我们能够仿照引擎中的方法来做. 值 ...
- ProFTPD 的 mod_lang模块
ProFTPD 的 mod_lang模块http://www.proftpd.org/docs/modules/mod_lang.html安装该mod_lang模块随ProFTPD一起分发.要在pro ...
- BZOJ 1579 道路升级 Dijkstra
思路: 这道题 不能把所有边都建出来 会MLE的!!! oh gosh 其实不建所有的边 用的时候再调就行了-.(也没啥区别) //By SiriusRen #include <queue> ...