分布式任务队列 Celery —— 应用基础
目录
前文列表
分布式任务队列 Celery
分布式任务队列 Celery —— 详解工作流
前言
紧接前文,继续看 Celery 应用基础,下列样例依旧从前文 proj 中进行修改。
Celery 的周期(定时)任务
Celery 周期任务功能由 Beat 任务调度器模块支撑,Beat 是一个服务进程,负责周期性启动 beat_schedule 中定义的任务。
e.g.
# filename: app_factory.py
from __future__ import absolute_import
from celery import Celery
from kombu import Queue, Exchange
def make_app():
app = Celery('proj')
app.config_from_object('proj.celeryconfig')
default_exchange = Exchange('default', type='direct')
web_exchange = Exchange('task', type='direct')
app.conf.task_default_queue = 'default'
app.conf.task_default_exchange = 'default'
app.conf.task_default_routing_key = 'default'
app.conf.task_queues = (
Queue('default', default_exchange, routing_key='default'),
Queue('high_queue', web_exchange, routing_key='hign_task'),
Queue('low_queue', web_exchange, routing_key='low_task'),
)
# 设定 Beat 时区,默认为 UTC 时区
app.conf.timezone = 'Asia/Shanghai’
# 在 beat_schedule 中声明周期任务
app.conf.beat_schedule = {
# 周期任务 Friendly Name
'periodic_task_add': {
# 任务全路径
'task': 'proj.task.tasks.add’,
# 周期时间
'schedule': 3.0,
# 指定任务所需的参数
'args': (2, 2)
},
}
return app使用 -B 选择,表示启动 Celery Worker 服务进程的同时启动 Beat 模块。

NOTE 1:Beat 会把周期任务的时间表存储在 celerybeat-schedule 文件,在执行指令的当前目录生成。当 timezone 发生改变时,Beat 会根据 celerybeat-schedule 的内容自动调整计时方式。
NOTE 2:Beat 也支持 crontab 计时方式,十分简单易用。
e.g.
# filename: app_factory.py
from celery.schedules import crontab
…
app.conf.beat_schedule = {
'periodic_task_add': {
'task': 'proj.task.tasks.add’,
# 每隔一分钟周期执行
'schedule': crontab(minute='*/1'),
'args': (2, 2)
},
}Celery 的同步调用
Task.get 方法处理用于获取任务的执行结果之外,还能够用于实现 Celery 同步调用,以满足更多的应用场景。
e.g.
# filename: tasks.py
import time
from proj.celery import app
@app.task
def add(x, y, debug=False):
# Test sync invoke.
time.sleep(10)
for i in xrange(10):
print("Warting: %s s" % i)
if debug:
print("x: %s; y: %s" % (x, y))
return x + y同步调用任务 add
>>> from proj.task.tasks import add
>>> add.delay(2, 2).get()
4
因为直接调用了 get 方法,所以进程会被阻塞知道任务 add 返回结果为止。
Celery 结果储存
如果你对任务执行的结果非常关注,那么你可以使用数据库(e.g. Redis)来充当 Backend,从而将执行结果持久化。
e.g.
# 执行一个任务,并取得任务 id
>>> from proj.task.tasks import add
>>> result = add.delay(2, 2)
>>> result.status
u’SUCCESS'
>>> result.get()
4
>>> result.id
'65cee5e0-5f4f-4d2b-b52f-6904e7f2b6ab’进入 Redis 数据库,查看该任务对应的记录。
root@aju-test-env:~# redis-cli
127.0.0.1:6379>
# 查看 Redis 所有的 keys
127.0.0.1:6379> keys *
1) "celery-task-meta-da3f6f3d-f977-4b39-a795-eaa89aca03ec"
2) "celery-task-meta-38437d5c-ebd8-442c-8605-435a48853085”
...
35) "celery-task-meta-65cee5e0-5f4f-4d2b-b52f-6904e7f2b6ab"
...
# 通过任务 id,可以定位出任务在 Redis 中的 value
127.0.0.1:6379> GET 'celery-task-meta-65cee5e0-5f4f-4d2b-b52f-6904e7f2b6ab'
"{\"status\": \"SUCCESS\", \"traceback\": null, \"result\": 4, \"task_id\": \"65cee5e0-5f4f-4d2b-b52f-6904e7f2b6ab\", \"children\": []}"Celery 的监控
Celery Flower 是 Celery 官方推荐的监控工具,借助于 Celery Events 接口,Flower 能够实时监控 Celery 的 Worker、Tasks、Broker、并发池等重要对象。
- 安装 Flower
$ pip install flower- 开启 Celery Events
celery worker -A proj -E -l info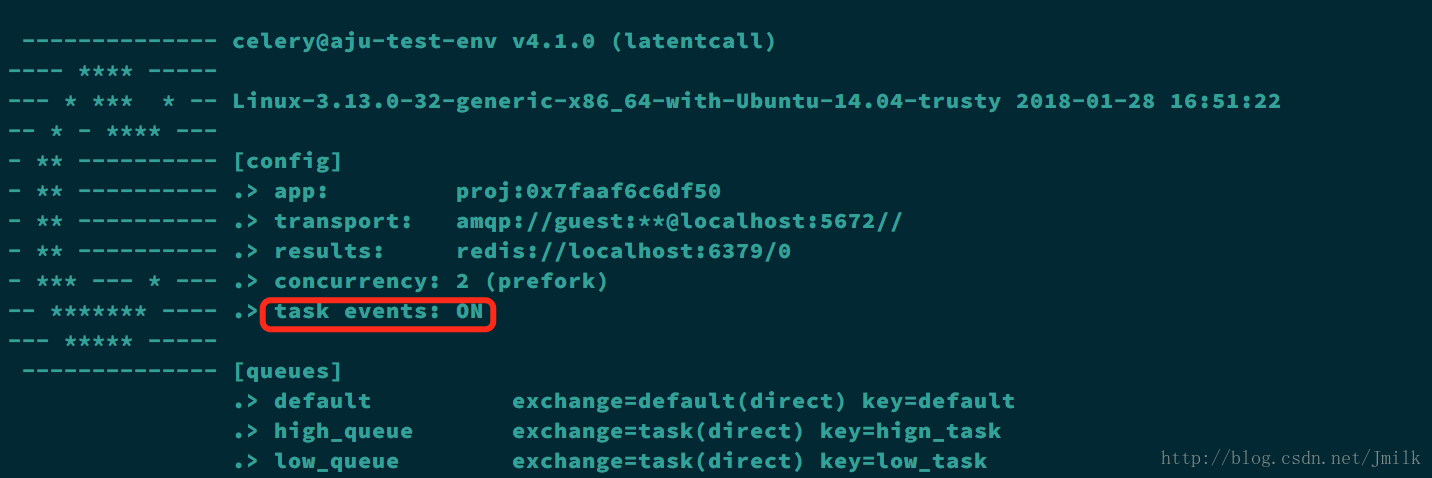
- 开启 RabbitMQ Management Plugin
$ rabbitmq-plugins enable rabbitmq_management
$ service rabbitmq-server restart- 启动 Flower,并指定 broker URL
>nbsp;celery flower -l info --broker_api=http://guest:guest@<rabbitmq_server_ip>:15672/api/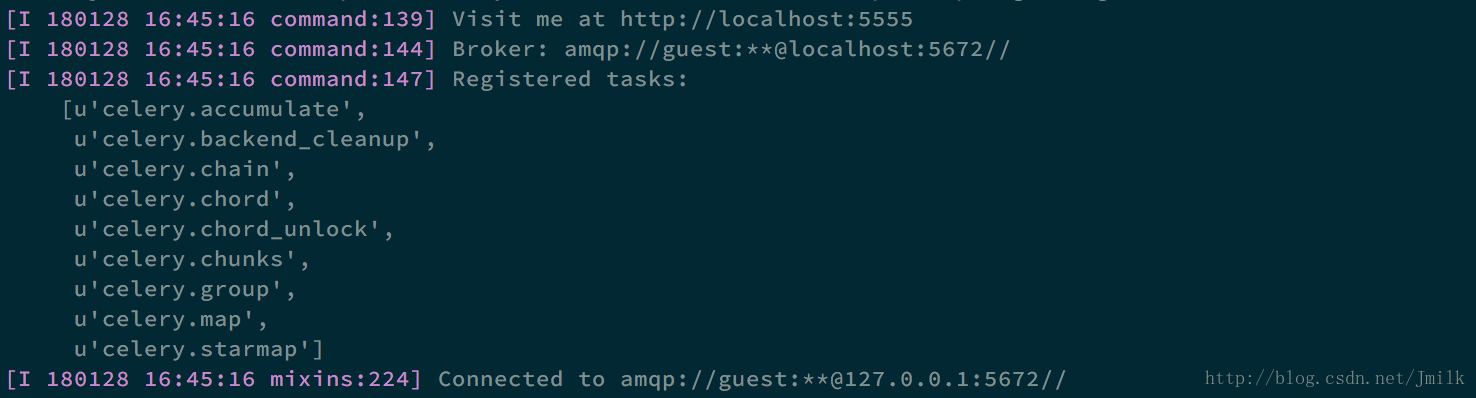
- 访问 Flower Web,浏览器打开
http://<flower_server_ip>:5555/dashboard
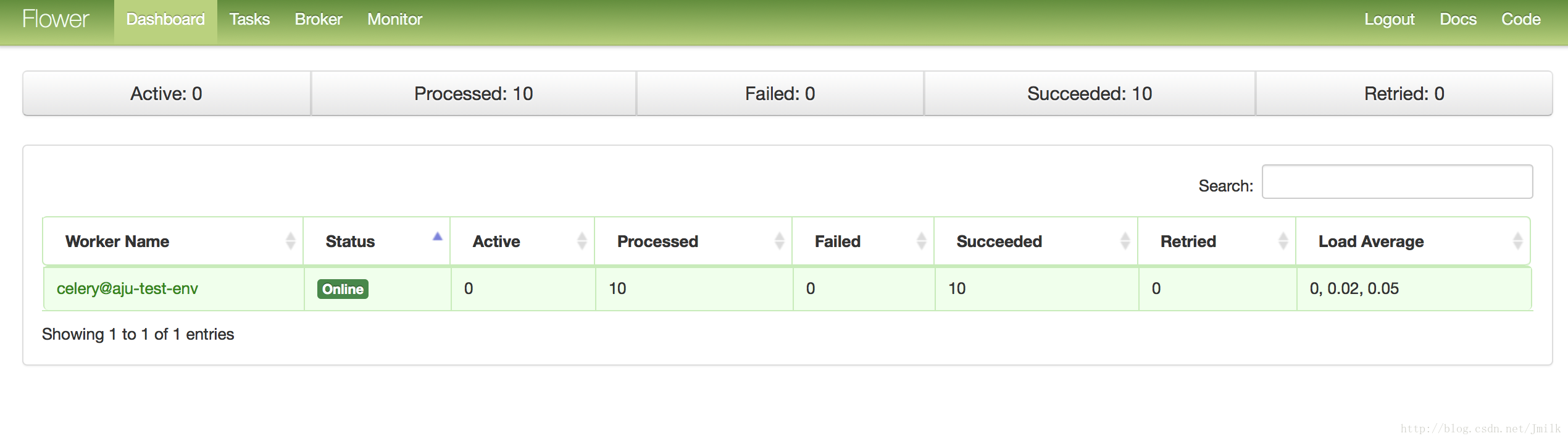
Celery 的调试
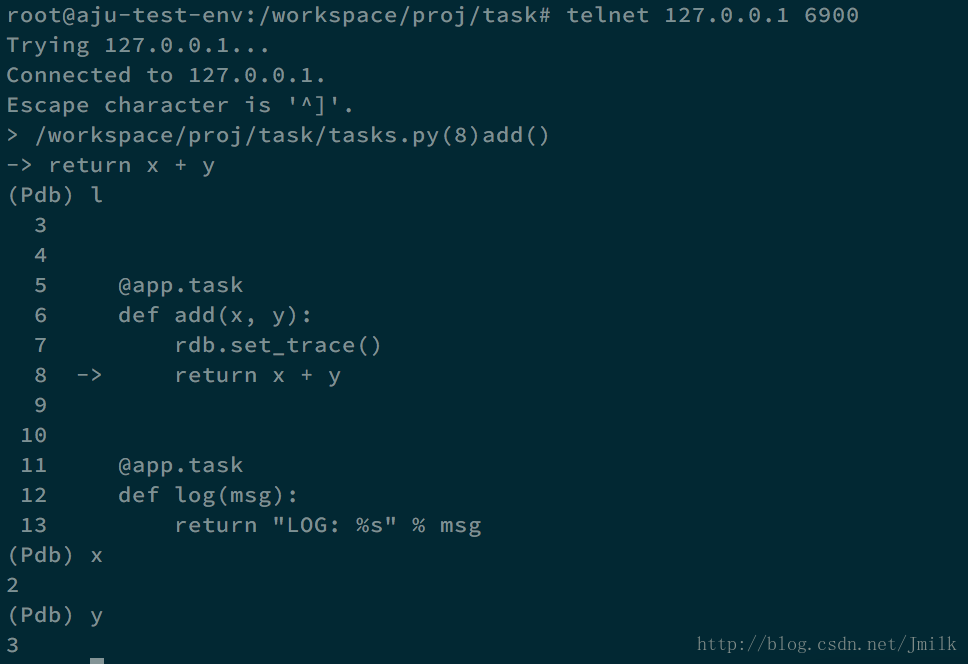
Celery 借助 telnet 可以支持远程 pdb 调试,非常方便。
# filename: tasks.py
from proj.celery import app
from celery.contrib import rdb
@app.task
def add(x, y):
# 设置断点
rdb.set_trace()
return x + y使用 celery.contrib 的 rdb 来设置断点,然后重启 Celery Worker 服务。
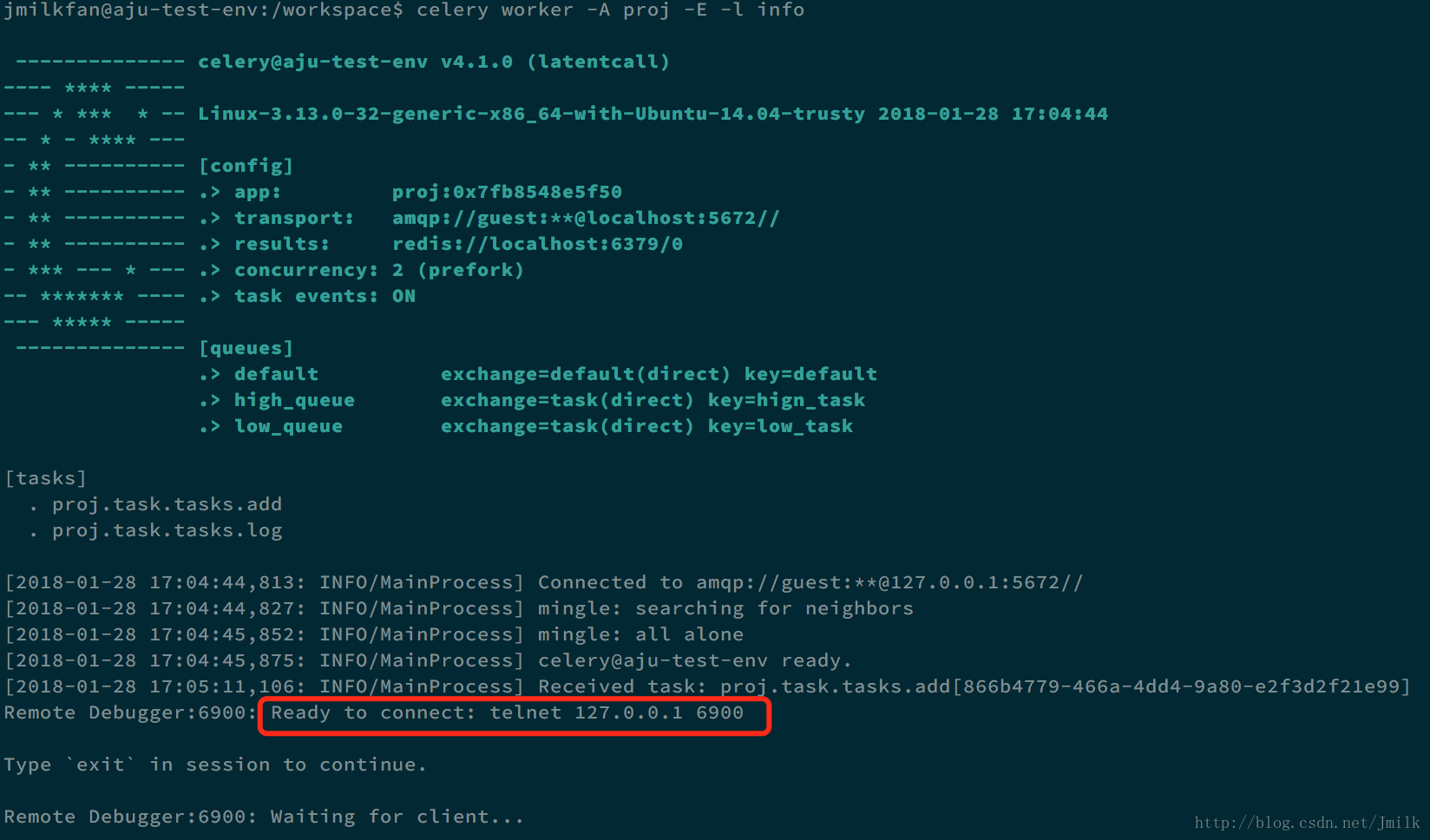
可以看见日志中提示了 telnet 远程连接的地址,所以打开另外一个终端,执行 telnet 指令即可完成连接,进入到非常熟悉的 pdb shell。
分布式任务队列 Celery —— 应用基础的更多相关文章
- 分布式任务队列 Celery —— Task对象
转载至 JmilkFan_范桂飓:http://blog.csdn.net/jmilk 目录 目录 前文列表 前言 Task 的实例化 任务的名字 任务的绑定 任务的重试 任务的请求上下文 任务的继 ...
- 分布式任务队列 Celery —— 深入 Task
目录 目录 前文列表 前言 Task 的实例化 任务的名字 任务的绑定 任务的重试 任务的请求上下文 任务的继承 前文列表 分布式任务队列 Celery 分布式任务队列 Celery -- 详解工作流 ...
- 分布式任务队列 Celery
目录 目录 前言 简介 Celery 的应用场景 架构组成 Celery 应用基础 前言 分布式任务队列 Celery,Python 开发者必备技能,结合之前的 RabbitMQ 系列,深入梳理一下 ...
- [源码解析] 分布式任务队列 Celery 之启动 Consumer
[源码解析] 分布式任务队列 Celery 之启动 Consumer 目录 [源码解析] 分布式任务队列 Celery 之启动 Consumer 0x00 摘要 0x01 综述 1.1 kombu.c ...
- [源码解析] 并行分布式任务队列 Celery 之 Task是什么
[源码解析] 并行分布式任务队列 Celery 之 Task是什么 目录 [源码解析] 并行分布式任务队列 Celery 之 Task是什么 0x00 摘要 0x01 思考出发点 0x02 示例代码 ...
- [源码分析] 并行分布式任务队列 Celery 之 Timer & Heartbeat
[源码分析] 并行分布式任务队列 Celery 之 Timer & Heartbeat 目录 [源码分析] 并行分布式任务队列 Celery 之 Timer & Heartbeat 0 ...
- 分布式任务队列 Celery —— 详解工作流
目录 目录 前文列表 前言 任务签名 signature 偏函数 回调函数 Celery 工作流 group 任务组 chain 任务链 chord 复合任务 chunks 任务块 mapstarma ...
- [源码解析] 并行分布式任务队列 Celery 之 消费动态流程
[源码解析] 并行分布式任务队列 Celery 之 消费动态流程 目录 [源码解析] 并行分布式任务队列 Celery 之 消费动态流程 0x00 摘要 0x01 来由 0x02 逻辑 in komb ...
- [源码解析] 并行分布式任务队列 Celery 之 多进程模型
[源码解析] 并行分布式任务队列 Celery 之 多进程模型 目录 [源码解析] 并行分布式任务队列 Celery 之 多进程模型 0x00 摘要 0x01 Consumer 组件 Pool boo ...
随机推荐
- C++ ->error LNK1123
终极解决方案:VS2010在经历一些更新后,建立Win32 Console Project时会出“error LNK1123” 错误,解决方案为将 项目|项目属性|配置属性|清单工具|输入和输出|嵌入 ...
- javaweb 项目编码格式设置
- SpringMVC @CookieValue注解
@CookieValue的作用 用来获取Cookie中的值 @CookieValue参数 1.value:参数名称 2.required:是否必须 3.defaultValue:默认值 @Cookie ...
- jquery 查找元素,并判断隐藏或显示
html <div class="panel-heading"> <h4 class="panel-title"> <a data ...
- Python Web 服务开发者: 第 1 部分
Python Web 服务开发者: 第 1 部分 Python Web 服务世界 Python 的座右铭一向是“装备齐全”,这是指在安装该语言时会附带一大套标准库和功能程序.本文概述了在 Python ...
- numpy模块、matplotlib模块、pandas模块
目录 1. numpy模块 2. matplotlib模块 3. pandas模块 1. numpy模块 numpy模块的作用 用来做数据分析,对numpy数组(既有行又有列)--矩阵进行科学计算 实 ...
- 微信小程序模板消息后端代码
利用spring 事件发送模板消息 1.定义事件 import com.ruoyi.project.salerauth.domain.TemplateMessage; import org.sprin ...
- Nginx静态文件服务器配置方法
在Java开发以及生产环境中,最常用的web应用服务器当属Tomcat,尽管这只猫也能够处理一些静态请求,例如图片.html.样式文件等,但是效率并不是那么尽人意.在生产环境中,我们一般使用Nginx ...
- DevOps之持续集成Pipeline(一)
一.Pipeline介绍 Jenkins2.0中最大的一个特性就是Pipeline,实际使用中Pipeline已经超越了我们对jenkins本身的理解,可能在之前我们大多数把Jenkins当做 ...
- nginx展示文件目录
1. 如何让nginx显示文件夹目录 vi /etc/nginx/conf.d/default.conf 添加如下内容: location / { root /data/www/file //指定实际 ...