pandas分组运算(groupby)
1. groupby()
import pandas as pd
df = pd.DataFrame([[1, 1, 2], [1, 2, 3], [2, 3, 4]], columns=["A", "B", "C"])
print(df)

g = df.groupby('A').mean() # 按A列分组(groupby),获取其他列的均值
print(g)

# 方法1
b = df['B'].groupby(df['A']).mean() # 按A列分组,获取B列的均值
print(b) # 方法2
b = df.ix[:,1].groupby(df.ix[:, 0]).mean() # 按A列分组(0对应A列,1对应B列),获取B列的均值
print(b) # 方法3
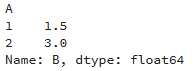
m = df.groupby('A')
b = m['B'].mean()
print(b)
2. 聚合方法size()和count()
size跟count的区别: size计数时包含NaN值,而count不包含NaN值
import pandas as pd
import numpy as np df = pd.DataFrame({"Name":["Alice", "Bob", "Mallory", "Mallory", "Bob" , "Mallory"],
"City":["Seattle", "Seattle", "Portland", "Seattle", "Seattle", "Portland"],
"Val":[4,3,3,np.nan,np.nan,4]})
print(df)
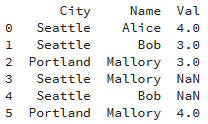
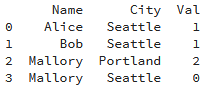
count()
a = df.groupby(["Name", "City"], as_index=False)['Val'].count()
print(a)
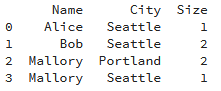
size()
b = df.groupby(["Name", "City"])['Val'].size().reset_index(name='Size')
print(b)
来自:https://blog.csdn.net/m0_37870649/article/details/80979809
pandas分组运算(groupby)的更多相关文章
- pandas聚合和分组运算——GroupBy技术(1)
数据聚合与分组运算——GroupBy技术(1),有需要的朋友可以参考下. pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的方式对数据集进行切片.切块.摘要等操作.根据一个或多个 ...
- Pandas分组运算(groupby)修炼
Pandas分组运算(groupby)修炼 Pandas的groupby()功能很强大,用好了可以方便的解决很多问题,在数据处理以及日常工作中经常能施展拳脚. 今天,我们一起来领略下groupby() ...
- Pandas分组(GroupBy)
任何分组(groupby)操作都涉及原始对象的以下操作之一.它们是 - 分割对象 应用一个函数 结合的结果 在许多情况下,我们将数据分成多个集合,并在每个子集上应用一些函数.在应用函数中,可以执行以下 ...
- pandas学习(数据分组与分组运算、离散化处理、数据合并)
pandas学习(数据分组与分组运算.离散化处理.数据合并) 目录 数据分组与分组运算 离散化处理 数据合并 数据分组与分组运算 GroupBy技术:实现数据的分组,和分组运算,作用类似于数据透视表 ...
- 【学习】数据聚合和分组运算【groupby】
分组键可以有多种方式,且类型不必相同 列表或数组, 某长度与待分组的轴一样 表示DataFrame某个列名的值 字典或Series,给出待分组轴上的值与分组名之间的对应关系 函数用于处理轴索引或索引中 ...
- Python数据聚合和分组运算(1)-GroupBy Mechanics
前言 Python的pandas包提供的数据聚合与分组运算功能很强大,也很灵活.<Python for Data Analysis>这本书第9章详细的介绍了这方面的用法,但是有些细节不常用 ...
- python库学习笔记——分组计算利器:pandas中的groupby技术
最近处理数据需要分组计算,又用到了groupby函数,温故而知新. 分组运算的第一阶段,pandas 对象(无论是 Series.DataFrame 还是其他的)中的数据会根据你所提供的一个或多个键被 ...
- 利用Python进行数据分析-Pandas(第六部分-数据聚合与分组运算)
对数据集进行分组并对各组应用一个函数(无论是聚合还是转换),通常是数据分析工作中的重要环节.在将数据集加载.融合.准备好之后,通常是计算分组统计或生成透视表.pandas提供了一个灵活高效的group ...
- python中pandas数据分析基础3(数据索引、数据分组与分组运算、数据离散化、数据合并)
//2019.07.19/20 python中pandas数据分析基础(数据重塑与轴向转化.数据分组与分组运算.离散化处理.多数据文件合并操作) 3.1 数据重塑与轴向转换1.层次化索引使得一个轴上拥 ...
随机推荐
- Linux 的帐号与群组:有效与初始群组、groups, newgrp
关于群组: 有效与初始群组.groups, newgrp 认识了帐号相关的两个档案 /etc/passwd 与 /etc/shadow 之后,您或许还是会觉得奇怪, 那么群组的设定档在哪里?还有,在 ...
- Jmeter 常见逻辑控制器详解
简介 Jmeter有很多逻辑控制器,可以控制请求的执行顺序和执行逻辑,本文就Jmeter常见的逻辑控制器做一个详细的描述,并通过示例让大家了解逻辑控制器的作用. 代码的逻辑分支通常有: 条件判断I ...
- trigger添加及表达式
创建触发器 点击Configuration(配置) → Hosts(主机) 点击hosts(主机)相关行的trigger 点击右上角的创建触发器(create trigger) name : 触发器名 ...
- Python之路:进程、线程
目录 一.进程与线程区别 1.1 什么是线程 1.2 什么是进程 1.3 进程与线程的区别 二.Python GIL全局解释器锁 三.线程 3.1 threading模块 3.2 Join & ...
- dcoker_ubuntu中安装python2.7
1.apt-get update 2.apt-get install python2.7 或 1.sudo apt-get update 2.sudo apt-get install python2. ...
- @InitBinder的作用
由@InitBinder表示的方法,可以对WebDataBinder对象进行初始化.WebDataBinder是DataBinder的子类,用于完成由表单到JavaBean属性的绑定. @InitBi ...
- Java 和JavaScript实现C#中的String.format效果
1.Java实现 /** * 需要引入com.alibaba.fastjson.1.2.8 * String result2=HuaatUtil.format(templa ...
- JDK代码查看--Eclipse
除了要会查找文档,还要学会使用查看代码. 首先看一看你是否下载了源码,如果没下载就去网上下载一个版本,在Eclipse中window->Preferences->Java->Inst ...
- css文件分类
简介 CSS(层叠样式表)是一门历史悠久的标记性语言,同 HTML 一道,被广泛应用于万维网(World Wide Web)中.HTML 主要负责文档结构的定义,CSS 负责文档表现形式或样式的定义. ...
- ssm框架使用详解&配置两个数据源
学习ssm框架已经快一年了,今天把这个框架总结一下. SSM 就是指 spring.SpringMVC和Mybatis.先说一下基本概念(百度上搜的) 1.基本概念 1.1.Spring Spring ...