pandas分组运算(groupby)
1. groupby()
import pandas as pd
df = pd.DataFrame([[1, 1, 2], [1, 2, 3], [2, 3, 4]], columns=["A", "B", "C"])
print(df)

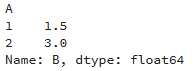
g = df.groupby('A').mean() # 按A列分组(groupby),获取其他列的均值
print(g)

# 方法1
b = df['B'].groupby(df['A']).mean() # 按A列分组,获取B列的均值
print(b) # 方法2
b = df.ix[:,1].groupby(df.ix[:, 0]).mean() # 按A列分组(0对应A列,1对应B列),获取B列的均值
print(b) # 方法3
m = df.groupby('A')
b = m['B'].mean()
print(b)
2. 聚合方法size()和count()
size跟count的区别: size计数时包含NaN值,而count不包含NaN值
import pandas as pd
import numpy as np df = pd.DataFrame({"Name":["Alice", "Bob", "Mallory", "Mallory", "Bob" , "Mallory"],
"City":["Seattle", "Seattle", "Portland", "Seattle", "Seattle", "Portland"],
"Val":[4,3,3,np.nan,np.nan,4]})
print(df)
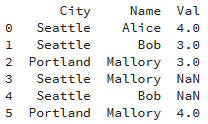
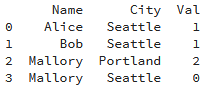
count()
a = df.groupby(["Name", "City"], as_index=False)['Val'].count()
print(a)
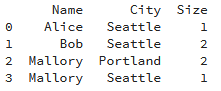
size()
b = df.groupby(["Name", "City"])['Val'].size().reset_index(name='Size')
print(b)
来自:https://blog.csdn.net/m0_37870649/article/details/80979809
pandas分组运算(groupby)的更多相关文章
- pandas聚合和分组运算——GroupBy技术(1)
数据聚合与分组运算——GroupBy技术(1),有需要的朋友可以参考下. pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的方式对数据集进行切片.切块.摘要等操作.根据一个或多个 ...
- Pandas分组运算(groupby)修炼
Pandas分组运算(groupby)修炼 Pandas的groupby()功能很强大,用好了可以方便的解决很多问题,在数据处理以及日常工作中经常能施展拳脚. 今天,我们一起来领略下groupby() ...
- Pandas分组(GroupBy)
任何分组(groupby)操作都涉及原始对象的以下操作之一.它们是 - 分割对象 应用一个函数 结合的结果 在许多情况下,我们将数据分成多个集合,并在每个子集上应用一些函数.在应用函数中,可以执行以下 ...
- pandas学习(数据分组与分组运算、离散化处理、数据合并)
pandas学习(数据分组与分组运算.离散化处理.数据合并) 目录 数据分组与分组运算 离散化处理 数据合并 数据分组与分组运算 GroupBy技术:实现数据的分组,和分组运算,作用类似于数据透视表 ...
- 【学习】数据聚合和分组运算【groupby】
分组键可以有多种方式,且类型不必相同 列表或数组, 某长度与待分组的轴一样 表示DataFrame某个列名的值 字典或Series,给出待分组轴上的值与分组名之间的对应关系 函数用于处理轴索引或索引中 ...
- Python数据聚合和分组运算(1)-GroupBy Mechanics
前言 Python的pandas包提供的数据聚合与分组运算功能很强大,也很灵活.<Python for Data Analysis>这本书第9章详细的介绍了这方面的用法,但是有些细节不常用 ...
- python库学习笔记——分组计算利器:pandas中的groupby技术
最近处理数据需要分组计算,又用到了groupby函数,温故而知新. 分组运算的第一阶段,pandas 对象(无论是 Series.DataFrame 还是其他的)中的数据会根据你所提供的一个或多个键被 ...
- 利用Python进行数据分析-Pandas(第六部分-数据聚合与分组运算)
对数据集进行分组并对各组应用一个函数(无论是聚合还是转换),通常是数据分析工作中的重要环节.在将数据集加载.融合.准备好之后,通常是计算分组统计或生成透视表.pandas提供了一个灵活高效的group ...
- python中pandas数据分析基础3(数据索引、数据分组与分组运算、数据离散化、数据合并)
//2019.07.19/20 python中pandas数据分析基础(数据重塑与轴向转化.数据分组与分组运算.离散化处理.多数据文件合并操作) 3.1 数据重塑与轴向转换1.层次化索引使得一个轴上拥 ...
随机推荐
- CenOS7秘钥双向验证的配置
配置密钥对的双向配置 HOST1配置: root下编辑/etc/ssh/sshd_config RSAAuthentication yes //启用RSA算法 Pubke ...
- Linux 查看主机、CPU、内存、内核、网卡或MAC地址、关机、重启、当前使用人、网络连接状态、主机目前使用状态
7 uname -a 显示主机名.内核.硬件结构等全部信息 unmae -r 只显示内核 查看Redhat和centos的内核版本也可以用cat /etc/redhat-release 或cat /e ...
- 谈谈我所理解的HashMap和HashTable
HashMap和HashTable之间的联系和区别如下: 1.HashMap几乎可以等价于Hashtable,但是它们之间继承不同:HashMap extends AbstractMap implem ...
- Pythonic Code In Several Lines
1. Fibonacci Series def Fib(n): if n == 1 or n == 2: return 1; else: return Fib(n - 1) + Fib(n - 2) ...
- Tableau Sheet
通过Tableau Sheet自带的超市数据给出几种图表. 在左侧数据Data栏有一列是Dimenslons是维度,下面Measures是测度,维度可以理解为你需要筛选的条件,比如根据年份看,根据地区 ...
- linux下redis 安装
--获取redis [redis@localhost ~]$ wget http://download.redis.io/releases/redis-2.8.7.tar.gz --2017-05-2 ...
- jdbc.properties不能加载到tomcat项目下面
javaweb项目的一个坑,每次重启tomcat都不能将项目中的jdbc.properties文件加载到tomcat项目对应的classes目录下面,得手动粘贴到该目录下.
- hdu4352 XHXJ's LIS[数位DP套状压DP+LIS$O(nlogn)$]
统计$[L,R]$内LIS长度为$k$的数的个数,$Q \le 10000,L,R < 2^{63}-1,k \le 10$. 首先肯定是数位DP.然后考虑怎么做这个dp.如果把$k$记录到状态 ...
- Nginx虚拟主机多server_name的顺序问题
Nginx虚拟主机多server_name的顺序问题 大 | 中 | 小 [ 2008-11-28 11:27 | by 张宴 ] [文章作者:张宴 本文版本:v1.0 最后修改:2008.11. ...
- 'EF.Utility.CS.ttinclude' returned a null or empty string.
需要安装https://www.microsoft.com/en-us/download/details.aspx?id=40762