HBase2.0新特性解析
作者 | 个推大数据运维工程师 行者
升级背景
个推作为专业的数据智能服务商,在业务开展过程中存在海量的数据存储与查询的需求,为此个推选用了高可靠、高性能、面向列、可伸缩的分布式数据存储系统——HBase。
然而,运行HBase老集群(使用HBase1.0版本)多年后,遇到了两大问题:各节点基础环境不一致;该集群的服务器运行多年已过保。而且随着个推业务量增长,性能方面也开始遇到瓶颈。经过综合评估,个推决定将老集群升级并迁移到HBase2.0新集群以解决HBase老集群存在的上述问题。
升级步骤
下面是个推升级并迁移的全步骤,供开发者参考。由于整个过程将涉及多个部门且用时长,建议各位在操作的过程中可以让各部门指定专人对接。
准备1:HBase表认领,找到所有表的读写应用与业务方;
准备2:HBase2.0新集群部署,并打通到所有读写应用服务器的网络;
调试3:测试环境调试应用,确认能正常使用HBase2.0集群;
调试4:开发数据校验工具,对迁移后新老集群数据进行完整性校验;
迁移5:所有表双写工程上线,并确认新老集群写入数据一致;
迁移6:所有读取应用变更,迁移到新集群,确认读取正常;
收尾7:老集群写入工程停止,表禁用半个月,无异常后老集群下线。
HBase2.0 新特性
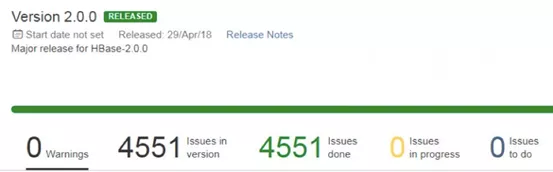
2018年4月29日,HBase2.0发布,共包含了4551个Issues。HBase2.0的新特性非常多,本次只介绍主要的几个特性,更多内容见官网文档。
[https://issues.apache.org/jira/secure/ReleaseNote.jspa?projectId=12310753&version=12327188]
特性1:AssignmentManager V2
AMv1存在的问题及原因分析
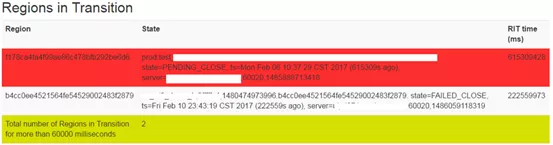
AMV1存在的主要问题是Regoins in Transition(RIT)。深度使用HBase的人一般都被 RIT困扰过,长时间的RIT简直令人抓狂。一些RIT确实是由于Region无法被RegionServer open造成的,但大部分的RIT,都是AM本身的问题引起的。
引发RIT的原因主要有以下几点:
- Region状态变化复杂
Region open 的过程有7 个组件参与并涉及20 多个步骤,但越复杂的逻辑意味着越容易出 bug。
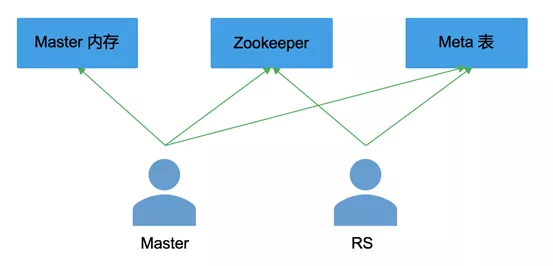
2.region 状态多处缓存
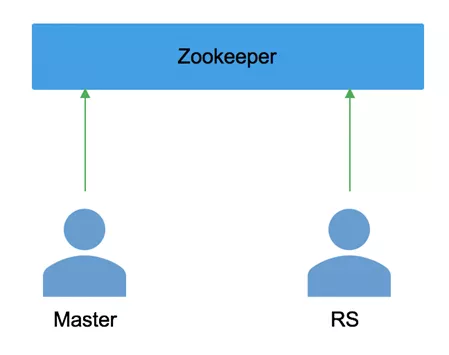
Master 内存 、Meta 表、Zookeeper 都会保存 region 的状态,Hbase1.0要求三者要保持完全同步;
Master 和 RegionServer 都会修改 Meta 表的状态和 Zookeeper 的状态,这将非常容易导致region状态出现混乱;
如果出现不一致,到底以哪里的状态为准?
3.严重依赖 Zookeeper进行状态通知
Region 状态的通知完全通过 Zookeeper,这导致了 region 的上线/下线的速度存在着一定的瓶颈。特别是在 region 比较多的时候,Zookeeper的通知会出现严重的滞后现象。
AMv2 的改进
主要的改进有以下四点:
1.region 每次状态变化,会先记录到 ProcedureWAL中,然后记录在 Meta 表;
2.region 状态信息只存放两个地方:meta 表、HMaster 的内存,不再存放Zookeeper;
3.只有 HMaster 才可以更新 meta 表中的信息;
4.HMaster与RS直接进行状态信息同步,去除Zookeeper依赖;
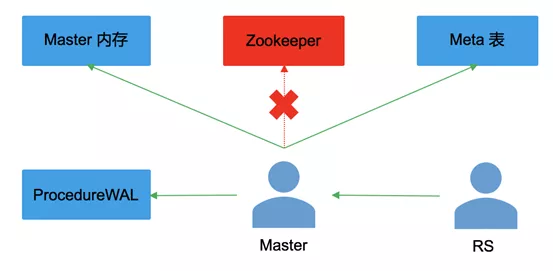
整体上来看,AMv2去除了 Zookeeper 依赖,有清晰明了的 region transition 机制,代码的可读性更强,非常有效地解决了RIT现象。
特性2:In-memory Flush & Compaction
HBase写入流程中,数据会先写入Memstore(内存中),达到阈值后,会触发flush刷新,生成HFile文件落到磁盘中。需要注意的是MemStore的最小flush单元是‘HRegion’而不是单个MemStore,如果HRegion中Memstore过多,每次flush的IO开销会很大。
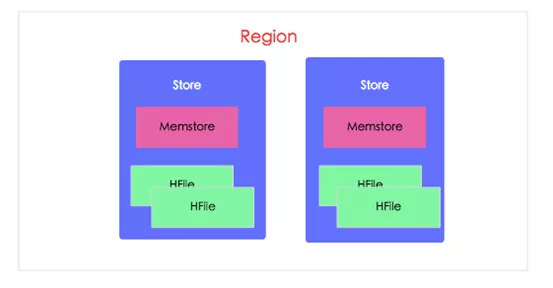
HBase1.x 的问题
Memstore flush刷新的触发条件很多,不过大多数对业务影响小,开发者无需担心。但如果触发Region Server级别flush,将会导致整个 RS 执行 flush,阻塞所有落在该Region Server上的更新操作,而且阻塞时间很长,可能会达到分钟级别,对业务影响非常大。
HBase2.0的改进
在2.0版本中,MemStore中的数据先Flush成一个Immutable的Segment,多个Immutable Segments可以在内存中进行Compaction,当达到一定阈值以后才将内存中的数据持久化成HDFS中的HFile文件。这就是2.0的新特性:In-memory Flush and Compaction ,而且该特性在2.0版本中已被默认启用(系统表除外)。
好处1:减少数据量、降低磁盘 IO,很多表的列簇只保留1个版本;
好处2:Segment 来替代 ConcurrentSkipListMap数据结构存储索引,节省空间,同样的 MemStore 可以存储更多的数据。

特性3:Offheaping of Read/Write Path
HBase 服务读写数据较多依赖堆内内存实现,JVM采用的是stop-the-world的方式进行垃圾回收,很容易造成 JVM 进程因为 GC 而停顿时间比较长。 而HBase 是一个低延迟、对响应性要求比较高的系统,GC 很容易造成HBase 服务抖动、延迟高。
HBase社区解决GC延迟的思路是尽量减少使用JVM 堆内内存,堆内内存使用减少了,GC也就随着减少了,社区为此支持了读写链路的offheap。
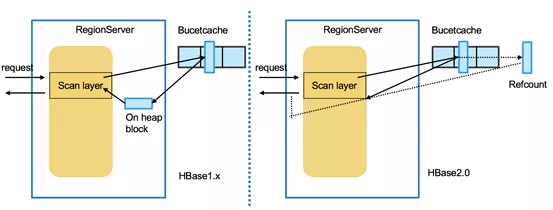
读链路的offheap主要包括以下几个优化 :
- 对BucketCache引用计数,避免读取时的拷贝;
- 使用ByteBuffer做为服务端KeyValue的实现,从而使KeyValue可以存储在offheap的内存中;
- 对BucketCache进行了一系列性能优化。
写链路的offheap包括以下几个优化:
- 在RPC层直接把网络流上的KeyValue读入offheap的bytebuffer中;
- 使用offheap的MSLAB pool;
- 使用支持offheap的Protobuf版本(3.0+)。
HBase2.0 的“坑”
V2.0.3之前版本不支持HBCK2
HBCK2 versions should be able to work across multiple hbase-2 releases. It will fail with a complaint if it is unable to run. There is no HbckService in versions of hbase before 2.0.3 and 2.1.1. HBCK2 will not work against these versions.
建议HBase升级到V2.0.3或V2.1.1,详情看HBCK2文档。
[https://github.com/apache/hbase-operator-tools/tree/master/hbase-hbck2]
重度依赖Procedure V2
AMv2之所以能保持简洁高效的一个重要原因就是其重度依赖了Procedure V2,把一些复杂的逻辑都转移到了Procedure V2中。但是这样做的问题是:一旦ProcedureWAL出现了损坏,这个后果就是灾难性的。当然,小编相信经过一段时间的bug修复和完善后,这些问题将不复存在。
HBase作为个推大数据一项重要的基础服务,性能的好坏影响重大。个推将HBase1.0升级到了HBase2.0版本后,在可靠性、安全性方面都有了很大提升,有效解决了1.0版本中的多种问题。未来,个推将会持续关注HBase 2.0,与大家共同探讨如何在生产环境中更好地对其进行使用。
HBase2.0新特性解析的更多相关文章
- HBase2.0新特性之In-Memory Compaction
In-Memory Compaction是HBase2.0中的重要特性之一,通过在内存中引入LSM结构,减少多余数据,实现降低flush频率和减小写放大的效果.本文根据HBase2.0中相关代码以及社 ...
- GreenDao3.0新特性解析(配置、注解、加密)
Greendao3.0release与7月6日发布,其中最主要的三大改变就是:1.换包名 2.实体注解 3.加密支持的优化 本文里面会遇到一些代码示例,就摘了官方文档和demo里的例子了,因为他们的例 ...
- C++ 11学习和掌握 ——《深入理解C++ 11:C++11新特性解析和应用》读书笔记(一)
因为偶然的机会,在图书馆看到<深入理解C++ 11:C++11新特性解析和应用>这本书,大致扫下,受益匪浅,就果断借出来,对于其中的部分内容进行详读并亲自编程测试相关代码,也就有了整理写出 ...
- C#发展历程以及C#6.0新特性
一.C#发展历程 下图是自己整理列出了C#每次重要更新的时间及增加的新特性,对于了解C#这些年的发展历程,对C#的认识更加全面,是有帮助的. 二.C#6.0新特性 1.字符串插值 (String In ...
- ASP.NET Web API 2.0新特性:Attribute Routing1
ASP.NET Web API 2.0新特性:Attribute Routing[上篇] 对于一个针对ASP.NET Web API的调用请求来说,请求的URL和对应的HTTP方法的组合最终决定了目标 ...
- php 7.1 新特性解析
php 7.1 新特性解析 返回值和传入参数可以指定为 null <?php function testReturn(): ?string { return 'elePHPant'; } var ...
- C#6.0,C#7.0新特性
C#6.0新特性 Auto-Property enhancements(自动属性增强) Read-only auto-properties (真正的只读属性) Auto-Property Initia ...
- webpack 4.0.0-beta.0 新特性介绍
webpack 可以看做是模块打包机.它做的事情是:分析你的项目结构,找到JavaScript模块以及其它的一些浏览器不能直接运行的拓展语言(Scss,TypeScript等),并将其打包为合适的格式 ...
- Spring Boot 2(一):Spring Boot 2.0新特性
Spring Boot 2(一):Spring Boot 2.0新特性 Spring Boot依赖于Spring,而Spring Cloud又依赖于Spring Boot,因此Spring Boot2 ...
随机推荐
- Linux 测试IP和端口是否能访问
一. 使用wget判断 wget是linux下的下载工具,需要先安装. 用法: wget ip:port 连接存在的端口 转自:https://blog.csdn.net/weixin_3768923 ...
- Volatile可见性 与 Synchronization原子性的优化
Volatile可见性 比如现在我们有这样一段代码:线程等待另一个线程将数据装载完就输出success,可是最后程序一直卡在while循环里没有往下执行. public class VolatileD ...
- 【Activiti】为每一个流程绑定相应的业务对象的2种方法
方式1: 在保存每一个流程实例时,设置多个流程变量,通过多个流程变量的组合来过滤筛选符合该组合条件的流程实例,以后在需要查询对应业务对象所对应的流程实例时,只需查询包含该流程变量的值的流程实例即可. ...
- Freemarker生成word文档的时的一些&,>,<报错
替换模板ftl中的内容的时候,一些特殊的字符需要转移,例如: &,<,> value为字符串 value.replace("&","& ...
- 通过Nginx对CC攻击限流
最近公司部署到阿里金融云的系统遭受CC攻击,网络访问安全控制仅靠阿里云防火墙保障,在接入层及应用层并未做限流. 攻击者拥有大量的IP代理,只要合理控制每个IP的请求速率(以不触发防火墙拦截为限),仍给 ...
- centos7网络配置脚本
如下参数根据实际情况修改 #!/bin/bash #设置网络环境 sed -i -e 's|BOOTPROTO=dhcp|BOOTPROTO=static|' /etc/sysconfig/netwo ...
- shell 脚本中的入参获取与判断
1.获取shell脚本的入参个数: $# 2.获取shell脚本的第n个入参的字符个数/字符串长度(注意这里的n需要替换为具体的数字,如果这个数字超过实际的入参个数,结果为0): ${#n}
- web攻击日志分析之新手指南
0x00 前言 现实中可能会经常出现web日志当中出现一些被攻击的迹象,比如针对你的一个站点的URL进行SQL注入测试等等,这时候需要你从日志当中分析到底是个什么情况,如果非常严重的话,可能需要调查取 ...
- 初学者如何从零学习人工智能?(AI)
一.机器学习 有关机器学习领域的最佳介绍,请观看Coursera的Andrew Ng机器学习课程. 它解释了基本概念,并让你很好地理解最重要的算法. 有关ML算法的简要概述,查看这个TutsPlus课 ...
- 找到并更改启动时间(timeout)
centos7更改引导项等待时间 centos7已经不用grub,改用grub2. [ root]# vi /boot/grub2/grub.cfg 找到并更改启动时间(timeout) [root] ...