Solr 4.4.0利用dataimporthandler导入本地pdf、word等文档
1. 创建本地目录
$ mkdir /usr/local/contentplatform/solr/solr/core1/file1
$ ls -lh
total 88M
-rw-r--r-- tnuser appuser 14M May : apache_hbase_reference_guide.pdf
-rw-r--r-- tnuser appuser 7.4M Apr : Architecting_HBase_Applications.pdf
-rw-r--r-- tnuser appuser 14M Jan Cloudera_Hadoop_Test_Cases.docx
-rw-r--r-- tnuser appuser 6.6M Apr : HBase_Administration_Cookbook.pdf
-rw-r--r-- tnuser appuser 2.1M Apr : HBase_Essentials.pdf
-rw-r--r-- tnuser appuser 25M Apr : Hbase-HBase实战.pdf
-rw-r--r-- tnuser appuser 7.9M Nov HBase.in.Action.pdf
-rw-r--r-- tnuser appuser 13M Apr : HBase:The_Definitive_Guide.pdf
2. 在core的conf目录修改配置文件solrconfig.xml配置dataimport请求处理器
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
3. 在conf目录新建data-config.xml文件并添加数据源的引用
<dataConfig>
<dataSource name="fileDataSource" type="fileDataSource" />
<dataSource name="binFileDataSource" type="BinFileDataSource" />
<document>
<entity
name="file1"
datasource="fileDataSource"
processor="FileListEntityProcessor"
baseDir="/usr/local/contentplatform/solr/solr/core1/file1"
fileName=".*\.(pdf)|(doc)|(docx)|(ppt)|(pptx)|(xls)|(xlsx)|(odf)|(txt)|(rtf)|(html)|(htm)|(jpg)|(csv)"
onError="skip"
recursive="true"
rootEntity="false">
<field column="file" name="id" />
<field column="fileSize" name="size" />
<field column="fileAbsolutePath" name="filepath" />
<field column="fileLastModified" name="lastModified" /> <entity
name="documentImport1"
processor="TikaEntityProcessor"
url="${file1.fileAbsolutePath}"
format="text"
datasource="binFileDataSource"
onError="skip"
recursive="true">
<field column="Author" name="author" meta="true"/>
<field column="title" name="title" meta="true"/>
<field column="text" name="text"/>
</entity>
</entity>
</document>
</dataConfig>
4.修改conf目录下的schema.xml文件,添加以下内容
<field name="fileLastModified" type="date" indexed="true" stored="true"/>
<field name="fileAbsolutePath" type="string" indexed="true" stored="true"/>
5. 重新加载配置文件

6. 通过DIH导入本地的文件
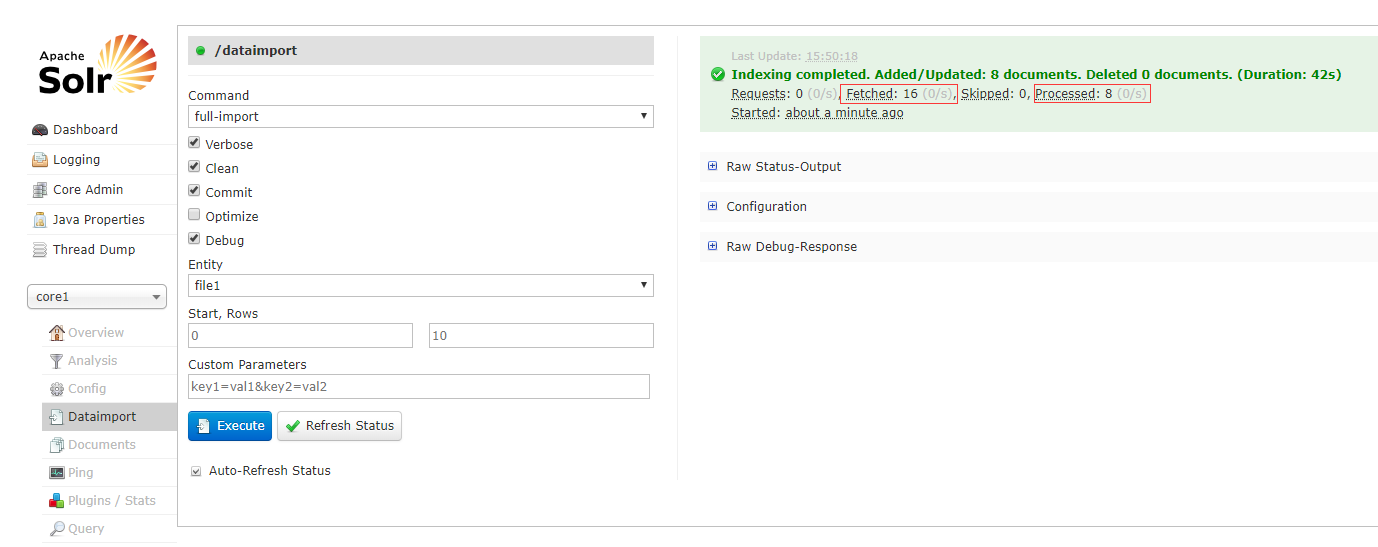
6. 查看导入的文档

{
"responseHeader": {
"status": ,
"QTime": ,
"params": {
"indent": "true",
"q": "*:*",
"_": "",
"wt": "json"
}
},
"response": {
"numFound": ,
"start": ,
"docs": [
{
"id": "Hbase-HBase实战.pdf",
"title": [
"HBASE 实战=HBASE IN ACTION"
],
"author": "(美)NICK DIMIDUK著;谢磊译",
"author_s": "(美)NICK DIMIDUK著;谢磊译",
"_version_":
},
{
"id": "apache_hbase_reference_guide.pdf",
"title": [
"Apache HBase ™ Reference Guide"
],
"author": "Apache HBase Team",
"author_s": "Apache HBase Team",
"_version_":
},
{
"id": "Architecting_HBase_Applications.pdf",
"title": [
"Architecting HBase Applications"
],
"author": "Jean-Marc Spaggiari & Kevin O'Dell",
"author_s": "Jean-Marc Spaggiari & Kevin O'Dell",
"_version_":
},
{
"id": "HBase_Administration_Cookbook.pdf",
"_version_":
},
{
"id": "HBase_Essentials.pdf",
"title": [
""
],
"author": "",
"author_s": "",
"_version_":
},
{
"id": "HBase.in.Action.pdf",
"title": [
"HBase in Action"
],
"author": "Nick Dimiduk, Amandeep Khurana",
"author_s": "Nick Dimiduk, Amandeep Khurana",
"_version_":
},
{
"id": "HBase:The_Definitive_Guide.pdf",
"title": [
"HBase: The Definitive Guide"
],
"author": "Lars George",
"author_s": "Lars George",
"_version_":
},
{
"id": "Cloudera_Hadoop_Test_Cases.docx",
"author": "FeiLong, Li [DBA]",
"author_s": "FeiLong, Li [DBA]",
"_version_":
}
]
}
}
Solr 4.4.0利用dataimporthandler导入本地pdf、word等文档的更多相关文章
- Solr 4.4.0利用dataimporthandler导入postgresql数据库表
将数据库edbstore的edbtore schema下的customers表导入到solr 1. 首先查看customers表字段信息 edbstore=> \d customers Tabl ...
- 【工具篇】利用DBExportDoc V1.0 For MySQL自动生成数据库表结构文档
对于DBA或开发来说,如何规范化你的数据库表结构文档是灰常之重要的一件事情.但是当你的库,你的表排山倒海滴多的时候,你就会很头疼了. 推荐一款工具DBExportDoc V1.0 For MySQL( ...
- 利用DBExportDoc V1.0 For MySQL自动生成数据库表结构文档
对于DBA或开发来说,如何规范化你的数据库表结构文档是灰常之重要的一件事情.但是当你的库,你的表排山倒海滴多的时候,你就会很头疼了. 推荐一款工具DBExportDoc V1.0 For MySQL( ...
- idea导入项目报错:文档中根元素前面的标记必须格式正确
今天从git上面导入项目之后,由于是上周刚刚提交过的,本地也没有什么修改,于是就从gitlab上面直接下载下来了.可是项目启动时候,报错了... 文档中根元素前面的标记必须格式正确 想想 原来是上次提 ...
- 利用sphinx为python项目生成API文档
sphinx可以根据python的注释生成可以查找的api文档,简单记录了下步骤 1:安装 pip install -U Sphinx 2:在需要生成文档的.py文件目录下执行sphinx-apido ...
- 利用Swagger2自动生成对外接口的文档
一直以来做对外的接口文档都比较原始,基本上都是手写的文档传来传去,最近发现了一个新玩具,可以在接口上省去不少麻烦. swagger是一款方便展示的API文档框架.它可以将接口的类型最全面的展示给对方开 ...
- 利用node 剥取其他网站的文档数据结构 ---
1.如何利用nodejs获取其他网站的文档结构呢 以下是代码演示------! //首先需要引入一些核心模块 var http = require('http'); var fs = require( ...
- Asp.Net Core2.0 WebAPI 使用Swagger生成漂亮的接口文档
1.引用NuGet: Swashbuckle.AspNetCore.Swagger Swashbuckle.AspNetCore.SwaggerGen 或 <PackageReference I ...
- Confluence-6.10.0+Jira-7.13+Crowd-3.2.1最全破解文档,附下载包
=========================================2019.4.19更改================================================ ...
随机推荐
- C# 扩展方法——获得枚举的Description
其他扩展方法详见:https://www.cnblogs.com/zhuanjiao/p/12060937.html /// <summary> /// 扩展方法,获得枚举的Descrip ...
- QT:QSS字体设置
css,qss font-family常用的黑体宋体等字体中英文对照 当qss使用中文设置字体时,无法生效.因为qss不支持中文设置字体,所以下面给出一些常用的黑体宋体字体中英文对照. 微软雅黑: M ...
- jquery attribute选择器 语法
jquery attribute选择器 语法 作用:[attribute] 选择每个带有指定属性的元素.可以选取带有任何属性的元素(对于指定的属性没有限制). 语法:$("[attribut ...
- BZOJ 5084: hashit 后缀自动机(原理题)
比较考验对后缀自动机构建过程的理解. 之前看题解写的都是树链的并,但是想了想好像可以直接撤销,复杂度是线性的. 自己想出来的,感觉后缀自动机的题应该不太能难倒我~ 注意:一定要手画一下后缀自动机的构建 ...
- Windows:在特定路径下启动命令行
造冰箱的大熊猫,本文适用于Windows 7@cnblogs 2018/11/30 在Windows文件浏览器中,按下“Shift+鼠标右键”,点击“在此处打开命令窗口”.
- Unity3D_(游戏)2D坦克大战 像素版
2D坦克大战 像素版 游戏规则: 玩家通过上.下.左.右移动坦克,空格键发射子弹 敌人AI出身时朝向己方大本营(未防止游戏快速结束,心脏上方三个单位障碍物设为刚体) 当玩家被击杀次数>=3 ...
- Java程序,JVM之间的关系
java程序是跑在JVM上的,严格来讲,是跑在JVM实例上的.一个JVM实例其实就是JVM跑起来的进程,二者合起来称之为一个JAVA进程.各个JVM实例之间是相互隔离的. 每个java程序都运行于某个 ...
- 在Idea下配置Maven
Idea 自带了apache maven,默认使用的是内置maven,所以我们可以配置全局setting,来调整一下配置,比如远程仓库地址,本地编译环境变量等. 使用IDEA自带的maven时,若不配 ...
- sessionStorge和localStorage的使用-踩坑记_09
sessionStorge的使用 sessionStorage 属性允许你访问一个 session Storage 对象.它与 localStorage 相似,不同之处在于 localStorage ...
- 20175215 2018-2019-2 第七周java课程学习总结
第八章 常用实用类 8.1 String类 Java专门提供了用来处理字符序列的String类.String类在java.lang包中,由于java.lang包中的类被默认引入,因此程序可以直接使用S ...