python 微服务方案
介绍
使用python做web开发面临的一个最大的问题就是性能,在解决C10K问题上显的有点吃力。有些异步框架Tornado、Twisted、Gevent 等就是为了解决性能问题。这些框架在性能上有些提升,但是也出现了各种古怪的问题难以解决。
在python3.6中,官方的异步协程库asyncio正式成为标准。在保留便捷性的同时对性能有了很大的提升,已经出现许多的异步框架使用asyncio。
使用较早的异步框架是aiohttp,它提供了server端和client端,对asyncio做了很好的封装。但是开发方式和最流行的微框架flask不同,flask开发简单,轻量,高效。正是结合这些优点, 以Sanic为基础,集成多个流行的库来搭建微服务。 Sanic框架是和Flask相似的异步协程框架,简单轻量,并且性能很高。本项目就是以Sanic为基础搭建的python微服务框架。(思想适用于其他语言)
微服务设计原则个人总结:
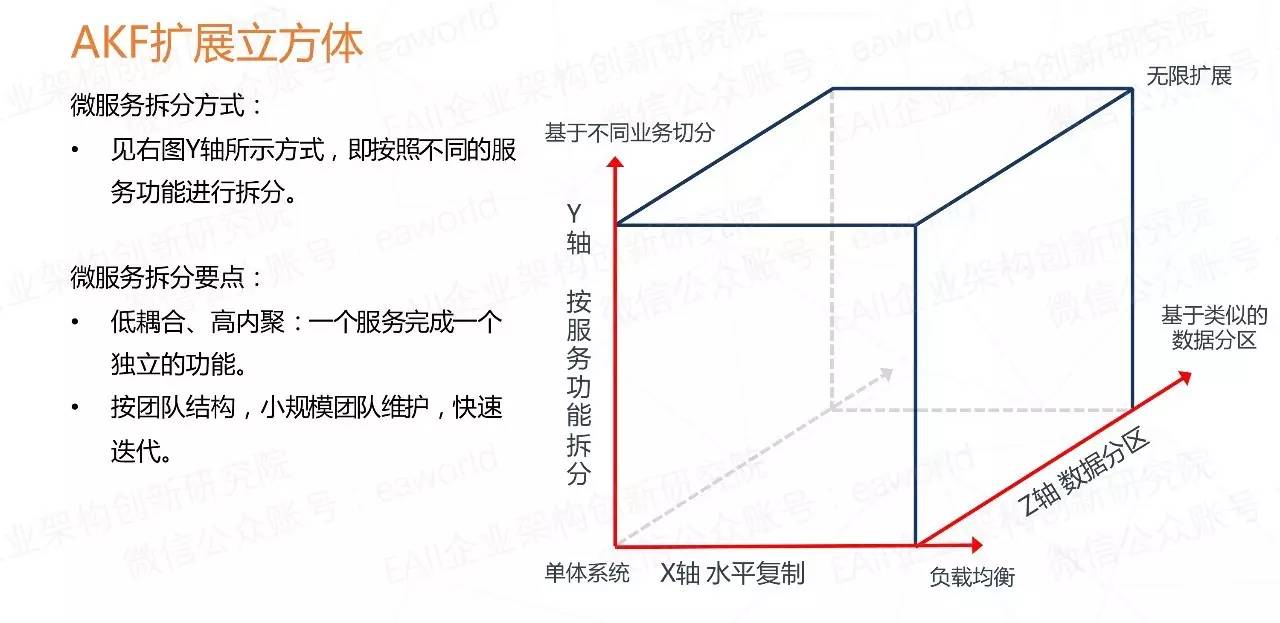
X 轴 :指的是水平复制,很好理解,就是讲单体系统多运行几个实例,做个集群加负载均衡的模式。
Z 轴 :是基于类似的数据分区,比如一个互联网打车应用突然或了,用户量激增,集群模式撑不住了,那就按照用户请求的地区进行数据分区,北京、上海、四川等多建几个集群。简单理解数据库拆分,比如分库分表
Y 轴 :就是我们所说的微服务的拆分模式,就是基于不同的业务拆分。
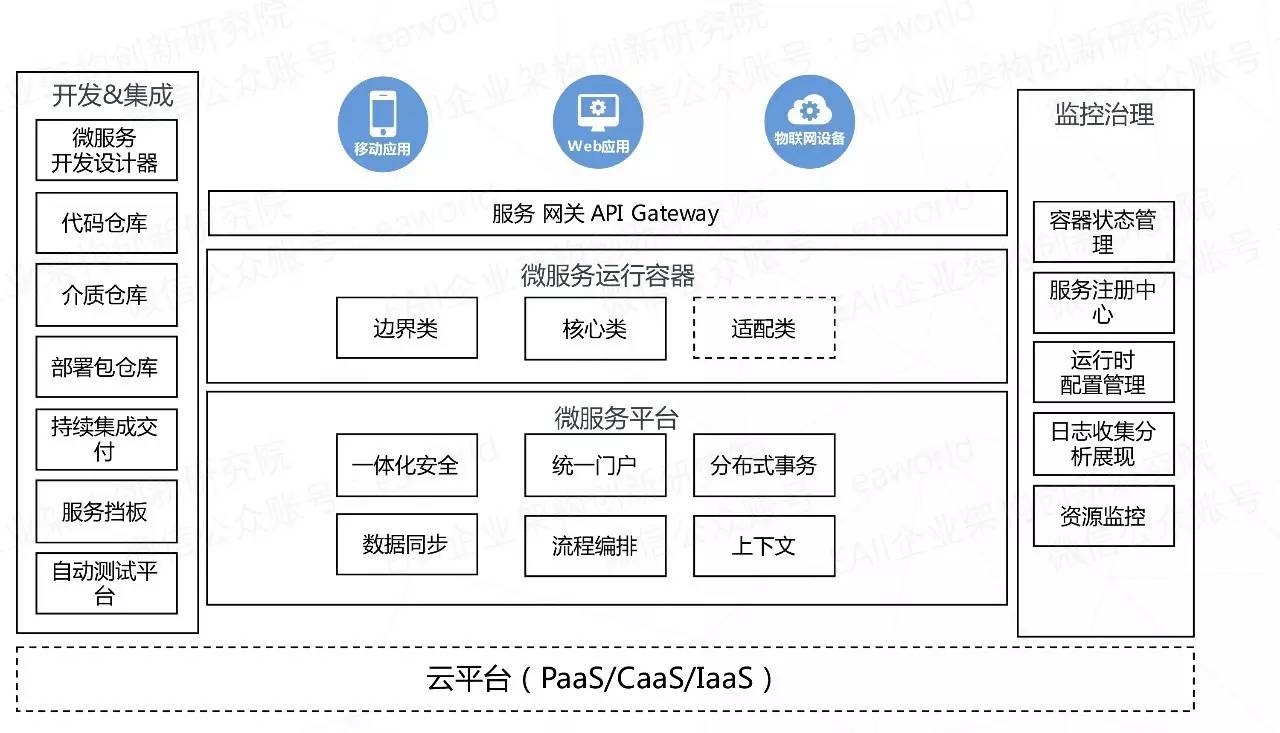
特点
- 使用sanic异步框架,简单,轻量,高效。
- 使用uvloop为核心引擎,使sanic在很多情况下单机并发甚至不亚于Golang。
- 使用asyncpg为数据库驱动,进行数据库连接,执行sql语句执行。
- 使用aiohttp为Client,对其他微服务进行访问。
- 使用peewee为ORM,但是只是用来做模型设计和migration。
- 使用opentracing为分布式追踪系统。
- 使用unittest做单元测试,并且使用mock来避免访问其他微服务。
- 使用swagger做API标准,能自动生成API文档。
服务端
使用sanic异步框架,有较高的性能,但是使用不当会造成blocking, 对于有IO请求的都要选用异步库。添加库要慎重。
sanic使用uvloop异步驱动,uvloop基于libuv使用Cython编写,性能比nodejs还要高。
功能说明:
启动前
- @app.listener('before_server_start')
- async def before_srver_start(app, loop):
- queue = asyncio.Queue()
- app.queue = queue
- loop.create_task(consume(queue, app.config.ZIPKIN_SERVER))
- reporter = AioReporter(queue=queue)
- tracer = BasicTracer(recorder=reporter)
- tracer.register_required_propagators()
- opentracing.tracer = tracer
- app.db = await ConnectionPool(loop=loop).init(DB_CONFIG)
- 创建DB连接池
- 创建Client连接
- 创建queue, 消耗span,用于日志追踪
- 创建opentracing.tracer进行日志追踪
中间件
@app.middleware('request')async def cros(request):if request.method == 'POST' or request.method == 'PUT':request['data'] = request.jsonspan = before_request(request)request['span'] = span@app.middleware('response')async def cors_res(request, response):span = request['span'] if 'span' in request else Noneif response is None:return responseresult = {'code': 0}if not isinstance(response, HTTPResponse):if isinstance(response, tuple) and len(response) == 2:result.update({'data': response[0],'pagination': response[1]})else:result.update({'data': response})response = json(result)if span:span.set_tag('http.status_code', "200")if span:span.set_tag('component', request.app.name)span.finish()return response
- 创建span, 用于日志追踪
- 对response进行封装,统一格式
异常处理
对抛出的异常进行处理,返回统一格式
任务
创建task消费queue中对span,用于日志追踪
异步处理
由于使用的是异步框架,可以将一些IO请求并行处理
Example:
async def async_request(datas):# async handler requestresults = await asyncio.gather(*[data[2] for data in datas])for index, obj in enumerate(results):data = datas[index]data[0][data[1]] = results[index]@user_bp.get('/<id:int>')@doc.summary("get user info")@doc.description("get user info by id")@doc.produces(Users)async def get_users_list(request, id):async with request.app.db.acquire(request) as cur:record = await cur.fetch(""" SELECT * FROM users WHERE id = $1 """, id)datas = [[record, 'city_id', get_city_by_id(request, record['city_id'])][record, 'role_id', get_role_by_id(request, record['role_id'])]]await async_request(datas)return record
get_city_by_id, get_role_by_id是并行处理。
相关连接
模型设计 & ORM
Peewee is a simple and small ORM. It has few (but expressive) concepts, making it easy to learn and intuitive to use。
ORM使用peewee, 只是用来做模型设计和migration, 数据库操作使用asyncpg。
Example:
# models.pyclass Users(Model):id = PrimaryKeyField()create_time = DateTimeField(verbose_name='create time',default=datetime.datetime.utcnow)name = CharField(max_length=128, verbose_name="user's name")age = IntegerField(null=False, verbose_name="user's age")sex = CharField(max_length=32, verbose_name="user's sex")city_id = IntegerField(verbose_name='city for user', help_text=CityApi)role_id = IntegerField(verbose_name='role for user', help_text=RoleApi)class Meta:db_table = 'users'# migrations.pyfrom sanic_ms.migrations import MigrationModel, info, dbclass UserMigration(MigrationModel):_model = Users# @info(version="v1")# def migrate_v1(self):# migrate(self.add_column('sex'))def migrations():try:um = UserMigration()with db.transaction():um.auto_migrate()print("Success Migration")except Exception as e:raise eif __name__ == '__main__':migrations()
- 运行命令 python migrations.py
- migrate_v1函数添加字段sex, 在BaseModel中要先添加name字段
- info装饰器会创建表migrate_record来记录migrate,version每个model中必须唯一,使用version来记录是否执行过,还可以记录author,datetime
- migrate函数必须以migrate_开头
相关连接
数据库操作
asyncpg is the fastest driver among common Python, NodeJS and Go implementations
使用asyncpg为数据库驱动, 对数据库连接进行封装, 执行数据库操作。
不使用ORM做数据库操作,一个原因是性能,ORM会有性能的损耗,并且无法使用asyncpg高性能库。另一个是单个微服务是很简单的,表结构不会很复杂,简单的SQL语句就可以处理来,没必要引入ORM。使用peewee只是做模型设计
Example:
- sql = "SELECT * FROM users WHERE name=$1"
- name = "test"
- async with request.app.db.acquire(request) as cur:
- data = await cur.fetchrow(sql, name)
- async with request.app.db.transaction(request) as cur:
- data = await cur.fetchrow(sql, name)
- acquire() 函数为非事务, 对于只涉及到查询的使用非事务,可以提高查询效率
- tansaction() 函数为事务操作,对于增删改必须使用事务操作
- 传入request参数是为了获取到span,用于日志追踪
- TODO 数据库读写分离
相关连接
客户端
使用aiohttp中的client,对客户端进行了简单的封装,用于微服务之间访问。
Don’t create a session per request. Most likely you need a session per application which performs all requests altogether.
A session contains a connection pool inside, connection reusage and keep-alives (both are on by default) may speed up total performance.
Example:
@app.listener('before_server_start')async def before_srver_start(app, loop):app.client = Client(loop, url='http://host:port')async def get_role_by_id(request, id):cli = request.app.client.cli(request)async with cli.get('/cities/{}'.format(id)) as res:return await res.json()@app.listener('before_server_stop')async def before_server_stop(app, loop):app.client.close()
对于访问不同的微服务可以创建多个不同的client,这样每个client都会keep-alives
日志 & 分布式追踪系统
装饰器logger
- @logger(type='method', category='test', detail='detail', description="des", tracing=True, level=logging.INFO)
- async def get_city_by_id(request, id):
- cli = request.app.client.cli(request)
- type: 日志类型,如 method, route
- category: 日志类别,默认为app的name
- detail: 日志详细信息
- description: 日志描述,默认为函数的注释
- tracing: 日志追踪,默认为True
- level: 日志级别,默认为INFO
分布式追踪系统
- OpenTracing是以Dapper,Zipkin等分布式追踪系统为依据, 建立了统一的标准。
- Opentracing跟踪每一个请求,记录请求所经过的每一个微服务,以链条的方式串联起来,对分析微服务的性能瓶颈至关重要。
- 使用opentracing框架,但是在输出时转换成zipkin格式。 因为大多数分布式追踪系统考虑到性能问题,都是使用的thrift进行通信的,本着简单,Restful风格的精神,没有使用RPC通信。以日志的方式输出, 可以使用fluentd, logstash等日志收集再输入到Zipkin。Zipkin是支持HTTP输入的。
- 生成的span先无阻塞的放入queue中,在task中消费队列的span。后期可以添加上采样频率。
- 对于DB,Client都加上了tracing
相关连接
API接口
api文档使用swagger标准。
Example:
from sanic_ms import doc@user_bp.post('/')@doc.summary('create user')@doc.description('create user info')@doc.consumes(Users)@doc.produces({'id': int})async def create_user(request):data = request['data']async with request.app.db.transaction(request) as cur:record = await cur.fetchrow(""" INSERT INTO users(name, age, city_id, role_id)VALUES($1, $2, $3, $4, $5)RETURNING id""", data['name'], data['age'], data['city_id'], data['role_id'])return {'id': record['id']}
- summary: api概要
- description: 详细描述
- consumes: request的body数据
- produces: response的返回数据
- tag: API标签
- 在consumes和produces中传入的参数可以是peewee的model,会解析model生成API数据, 在field字段的help_text参数来表示引用对象
- http://host:ip/openapi/spec.json 获取生成的json数据
相关连接
Response 数据
在返回时,不要返回sanic的response,直接返回原始数据,会在Middleware中对返回的数据进行处理,返回统一的格式,具体的格式可以[查看]
单元测试
单元测试使用unittest。 mock是自己创建了MockClient,因为unittest还没有asyncio的mock,并且sanic的测试接口也是发送request请求,所以比较麻烦. 后期可以使用pytest。
Example:
from sanic_ms.tests import APITestCasefrom server import appclass TestCase(APITestCase):_app = app_blueprint = 'visit'def setUp(self):super(TestCase, self).setUp()self._mock.get('/cities/1',payload={'id': 1, 'name': 'shanghai'})self._mock.get('/roles/1',payload={'id': 1, 'name': 'shanghai'})def test_create_user(self):data = {'name': 'test','age': 2,'city_id': 1,'role_id': 1,}res = self.client.create_user(data=data)body = ujson.loads(res.text)self.assertEqual(res.status, 200)
- 其中_blueprint为blueprint名称
- 在setUp函数中,使用_mock来注册mock信息, 这样就不会访问真实的服务器, payload为返回的body信息
- 使用client变量调用各个函数, data为body信息,params为路径的参数信息,其他参数是route的参数
代码覆盖
- coverage erase
- coverage run --source . -m sanic_ms tests
- coverage xml -o reports/coverage.xml
- coverage2clover -i reports/coverage.xml -o reports/clover.xml
- coverage html -d reports
- coverage2colver 是将coverage.xml 转换成 clover.xml,bamboo需要的格式是clover的。
相关连接
异常处理
使用 app.error_handler = CustomHander() 对抛出的异常进行处理
Example:
from sanic_ms.exception import ServerError@visit_bp.delete('/users/<id:int>')async def del_user(request, id):raise ServerError(error='内部错误',code=10500, message="msg")
- code: 错误码,无异常时为0,其余值都为异常
- message: 状态码信息
- error: 自定义错误信息
- status_code: http状态码,使用标准的http状态码
python 微服务方案的更多相关文章
- 推荐一款 Python 微服务框架 - Nameko
1. 前言 大家好,我是安果! 考虑到 Python 性能及效率性,Python Web 端一直不温不火,JAVA 和 Golang 的微服务生态一直很繁荣,也被广泛用于企业级应用开发当中 本篇文章 ...
- python 微服务开发书中几个方便的python框架
python 微服务开发是一本讲python 如果进行微服务开发的实战类书籍,里面包含了几个很不错的python 模块,记录下,方便后期回顾学习 处理并发的模块 greenlet && ...
- 使用 Consul 作为 Python 微服务的配置中心
使用 Consul 作为 Python 微服务的配置中心 Consul 作为数据中心,提供了 k/v 存储的功能,我们可以利用这个功能为 Python 微服务提供配置中心. Consul 提供了 HT ...
- DBPack 赋能 python 微服务协调分布式事务
作者:朱晗 中国电子云 什么是分布式事务 事务处理几乎在每一个信息系统中都会涉及,它存在的意义是为了保证系统数据符合期望的,且相互关联的数据之间不会产生矛盾,即数据状态的一致性. 按照数据库的经典理论 ...
- Python微服务实践-集成Consul配置中心
A litmus test for whether an app has all config correctly factored out of the code is whether the co ...
- 【Python】Python 微服务框架 nameko
nameko: 1.支持服务发现.负载均衡 2.支持依赖自动注入,使用很方便 3.缺点:超时.限速.权限等机制不完善 代码示例:https://github.com/junneyang/nameko- ...
- python微服务
https://realpython.com/python-microservices-grpc/ https://github.com/saqibbutt/python-flask-microser ...
- Python微服务实战
文档地址:https://www.qikqiak.com/tdd-book/ GitHub地址:https://github.com/cnych/flask-microservices-users 源 ...
- net core微服务构建方案
随着Net core升级,基本趋于完善了,很多都可以使用core开发了.已经有的Net framework就不说了,说实话,关注少了. 今天说说微服务方案,在之前说几句废话,core还在升级改造,AP ...
随机推荐
- [2019杭电多校第六场][hdu6641]TDL
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6641 题意为求出最小的n,满足(f(n,m)-n)^n=k,其中f(n,m)为第m大的x,其中x满足g ...
- P1828 香甜的黄油 (spfa)
[题目描述] 农夫John知道每只奶牛都在各自喜欢的牧场(一个牧场不一定只有一头牛).给出各头牛在的牧场和牧场间的路线,找出使所有牛到达的路程和最短的牧场(他将把糖放在那). [题目链接] https ...
- Oracle DBA_EXTENTS视图 与 DBA_SEGMENTS视图
DBA_EXTENTS describes the extents comprising the segments in all tablespaces in the database. Note ...
- C# 同步调用 异步调用 异步回调 多线程的作用
同步调用 : 委托的Invoke方法用来进行同步调用.同步调用也可以叫阻塞调用,它将阻塞当前线程,然后执行调用,调用完毕后再继续向下进行. 异步调用 :同步调用会阻塞线程,如果是要调用一项繁重的 ...
- axios动态数据的获取
跨域:前端处理.后端处理 前端方法:代理 后端加header 第一步:全局安装axios cnpm install axios --save-dev 第二步: methods:{ ...
- JavaScript基础4——省市联动
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- js中JSON和JSONP的区别,让你从懵逼到恍然大悟
说到AJAX就会不可避免的面临两个问题,第一个是AJAX以何种格式来交换数据?第二个是跨域的需求如何解决?这两个问题目前都有不同的解决方案,比如数据可以用自定义字符串或者用XML来描述,跨域可以通过服 ...
- 自制悬浮框,愉快地查看栈顶 Activity
接手陌生模块时,如何快速了解每个页面对应的类,以及它们之间的跳转逻辑.总不能在代码里一个一个地找startActivity()吧? 有时候,又想查看别人的 app 的页面组织(像淘宝.微信啊),总不能 ...
- c# Winform 调用可执行 exe 文件
c#是一个写windows桌面小工具的好东西,但有个时候,我们需要在 winform 程序中调用其他的 exe 文件,那么该如何实现呢? 如果只是拉起一个 exe 文件,可以参考如下方法实现: str ...
- python面向对象--反射机制
class Black: feture="ugly" def __init__(self,name,addr): self.addr=addr self.name=name def ...