logstash之OutPut插件
output插件是经过了input,然后过滤结构化数据之后,接下来我们需要借助output传到我们想传到的地方.output相当于一个输出管道。
2.3.1: 将采集数据标准输出到控制台
配置示例:
output {
stdout {
codec => rubydebug
}
}
Codec 来自 Coder/decoder
两个单词的首字母缩写,Logstash 不只是一个input | filter | output 的数据流,
而是一个input | decode | filter | encode | output 的数据流,codec 就是用来decode、encode 事件的。
简单说,就是在logstash读入的时候,通过codec编码解析日志为相应格式,从logstash输出的时候,通过codec解码成相应格式。
演示:
input {stdin{}}
output {
stdout {
codec => rubydebug
}
}
启动:bin/logstash -f /usr/local/elk/logstash-5.5.2/conf/template/stdout.conf
展示:

2.3.2:将采集数据保存到file文件中
通过日志收集系统将分散在数百台服务器上的数据集中存储在某中心服务器上,这是运维最原始的需求;
需求:将数据采集到logstash的日志文件中,区分业务和采集日期(哪天采集的)
input {stdin{}}
output {
file {
path => "/home/angel/logstash-5.5.2/logs/stdout/mobile-collection/%{+YYYY-MM-dd}-%{host}.txt"
codec => line {
format => "%{message}"
}
gzip => true
}
}
启动:
bin/logstash -f /home/angel/servers/logstash-5.5.2/logstash_conf/stdout_file.conf
2.3.3:将采集数据保存到elasticsearch
Logstash可以直接将采集到的信息下沉到elasticsearch中
input {stdin{}}
output {
elasticsearch {
hosts => ["hadoop01:9200"]
index => "logstash-%{+YYYY.MM.dd}" #这个index是保存到elasticsearch上的索引名称,如何命名特别重要,因为我们很可能后续根据某些需求做查询,所以最好带时间,因为我们在中间加上type,就代表不同的业务,这样我们在查询当天数据的时候,就可以根据类型+时间做范围查询
flush_size => 20000 #表示logstash的包数量达到20000个才批量提交到es.默认是500
idle_flush_time => 10 #多长时间发送一次数据,flush_size和idle_flush_time以定时定量的方式发送,按照批次发送,可以减少logstash的网络IO请求
user => elastic
password => changeme
}
}
启动:bin/logstash -f /usr/local/elk/logstash-5.5.2/conf/template/stdout_es.conf
向控制台中输入6条数据:
192.168.77.1 - - [10/Apr/2018:00:44:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 505 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.2 - - [10/Apr/2018:00:45:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 460 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.3 - - [10/Apr/2018:00:46:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 510 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.4 - - [10/Apr/2018:00:47:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 112 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.5 - - [10/Apr/2018:00:48:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 455 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.6 - - [10/Apr/2018:00:49:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 653 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
2.3.4:将采集的数据保存到redis
配置:
input { stdin {} }
output {
redis {
host => "hadoop01"
data_type => "list"
db => 2
port => "6379"
key => "logstash-chan-%{+yyyy.MM.dd}"
}
}
数据落地到redis的优化:
• 批处理类(仅用于data_type为list)
o batch:设为true,通过发送一条rpush命令,存储一批的数据
o 默认为false:1条rpush命令,存储1条数据
o 设为true之后,1条rpush会发送batch_events条数据
o batch_events:一次rpush多少条
o 默认50条
o batch_timeout:一次rpush最多消耗多少s
o 默认5s
• 拥塞保护(仅用于data_type为list)
o congestion_interval:每隔多长时间进行一次拥塞检查
o 默认1s
o 设为0,表示对每rpush一个,都进行检测
o congestion_threshold:list中最多可以存在多少个item数据
o 默认是0:表示禁用拥塞检测
o 当list中的数据量达到congestion_threshold,会阻塞直到有其他消费者消费list中的数据
o 作用:防止OOM
启动redis 将数据打入logstash控制台:
192.168.77.1 - - [10/Apr/2018:00:44:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 505 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.2 - - [10/Apr/2018:00:45:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 460 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.3 - - [10/Apr/2018:00:46:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 510 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.4 - - [10/Apr/2018:00:47:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 112 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.5 - - [10/Apr/2018:00:48:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 455 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
192.168.77.6 - - [10/Apr/2018:00:49:11 +0800] "POST /api/metrics/vis/data HTTP/1.1" 200 653 "http://hadoop01/app/kibana" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
去redis上做认证,查看是否已经存储redis中:
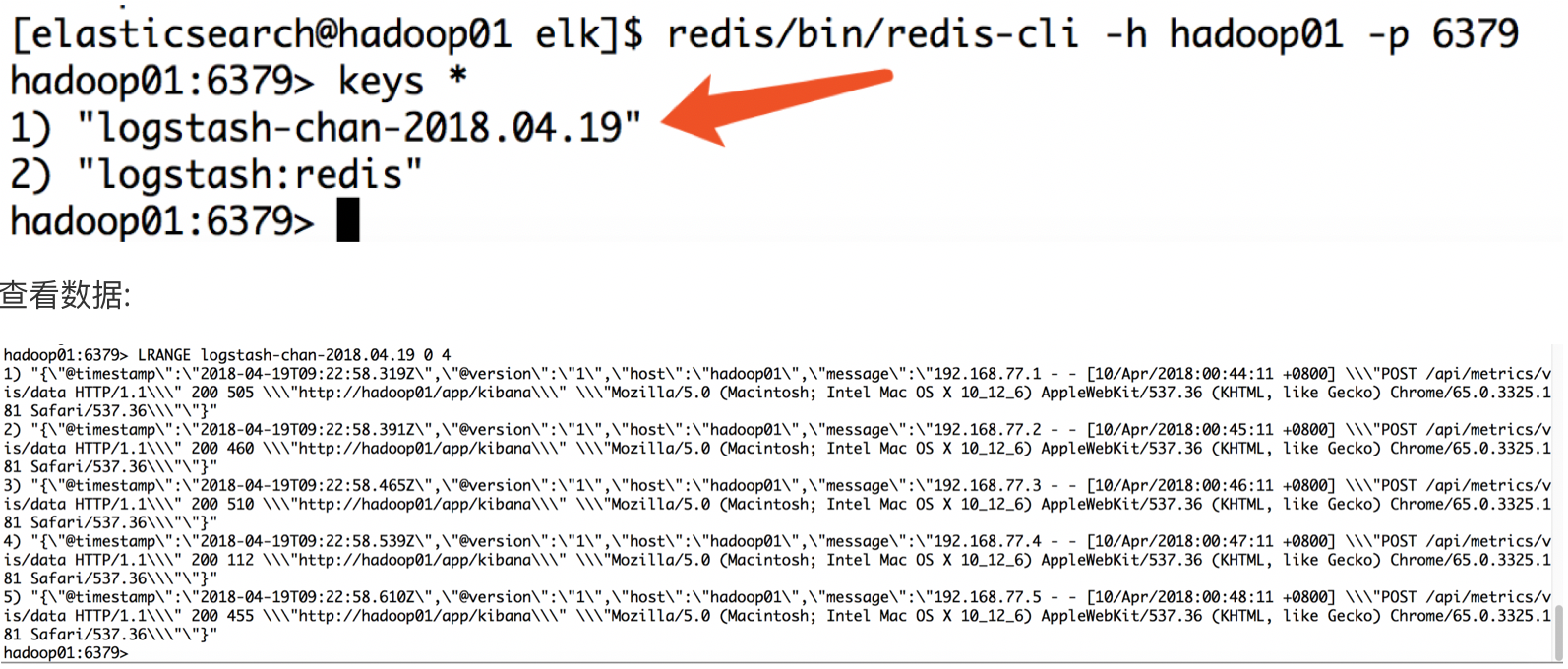
logstash之OutPut插件的更多相关文章
- logstash的output插件
logstash 的output插件 nginx,logstash和redis在同一台机子上 yum -y install redis,vim /etc/redis.conf 设置bind 0.0.0 ...
- 五十八.Kibana使用 、 Logstash配置扩展插件
1.导入数据 批量导入数据并查看 1.1 导入数据 1) 使用POST方式批量导入数据,数据格式为json,url 编码使用data-binary导入含有index配置的json文件 ]# ...
- 使用logstash的grok插件解析springboot日志
使用logstash的grok插件解析springboot日志 一.背景 二.解决思路 三.前置知识 四.实现步骤 1.准备测试数据 2.编写`grok`表达式 3.编写 logstash pipel ...
- logstash的output配置中指定elasticsearch的template
转自:https://blog.csdn.net/felix_yujing/article/details/78930389 之前采用的是通过filebeat收集nginx的日志,直接到elastic ...
- ELK 学习笔记之 Logstash之output配置
Logstash之output配置: 输出到file 配置conf: input{ file{ path => "/usr/local/logstash-5.6.1/bin/spark ...
- logstash之multiline插件,匹配多行日志
在外理日志时,除了访问日志外,还要处理运行时日志,该日志大都用程序写的,比如log4j.运行时日志跟访问日志最大的不同是,运行时日志是多行,也就是说,连续的多行才能表达一个意思. 在filter中,加 ...
- logstash 安装zabbix插件
<pre name="code" class="html">[root@xxyy yum.repos.d]# yum install ruby Lo ...
- Logstash使用grok插件解析Nginx日志
grok表达式的打印复制格式的完整语法是下面这样的: %{PATTERN_NAME:capture_name:data_type}data_type 目前只支持两个值:int 和 float. 在线g ...
- logstash实战filter插件之grok(收集apache日志)
有些日志(比如apache)不像nginx那样支持json可以使用grok插件 grok利用正则表达式就行匹配拆分 预定义的位置在 /opt/logstash/vendor/bundle/jruby/ ...
随机推荐
- Spring(三)--Spring bean的生命周期
Spring bean的生命周期 ApplicationContext Bean生命周期流程 1.需要的实体类 ackage com.xdf.bean; import org.springframew ...
- Qt两个类通过信号槽通信
qt需要通过信号槽来通信,connect的时候总是返回false,请教了公司的一个小哥,才解决了问题,虽然是个很白痴的问题. bool b = QObject::connect(m_pCollectO ...
- POJ 2955 Brackets 区间DP 入门
dp[i][j]代表i->j区间内最多的合法括号数 if(s[i]=='('&&s[j]==')'||s[i]=='['&&s[j]==']') dp[i][j] ...
- 如何在一个线程环境中使用一个线程非安全的java类
在开发过程中 当我们拿到一个线程非安全的java类的时候,我们可以额外创建这个类的管理类 并在管理类中控制同步 比如 一个非线程安全的Pair类 package test.thread.sx.test ...
- Elasticsearch入门教程(一):Elasticsearch及插件安装
原文:Elasticsearch入门教程(一):Elasticsearch及插件安装 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:h ...
- RabbitMQ入门教程(十一):消息属性Properties
原文:RabbitMQ入门教程(十一):消息属性Properties 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://b ...
- 企业面试题|最常问的MySQL面试题集合(一)
问题1:char.varchar的区别是什么?varchar是变长而char的长度是固定的.如果你的内容是固定大小的,你会得到更好的性能. 问题2: TRUNCATE和DELETE的区别是什么?DEL ...
- java线程中的同步锁和互斥锁有什么区别?
两者都包括对资源的独占. 区别是 1:互斥是通过竞争对资源的独占使用,彼此没有什么关系,也没有固定的执行顺序. 2:同步是线程通过一定的逻辑顺序占有资源,有一定的合作关系去完成任务.
- mycat的wrapper.log日志中发现主从切换报错
可能是MySQL在某些情况下重启(密切关注重启现象,关注日志,找出原因),导致mycat切换主从.由于设置了单向主从,mycat将从库切换为主库,原来的主库宕机.后来重新更新dnindex.conf之 ...
- 【转】Linux添加虚拟网卡
转自:https://blog.csdn.net/hzhsan/article/details/44677867 有时候,一台服务器需要设置多个ip,但又不想添加多块网卡,那就需要设置虚拟网卡.这里介 ...