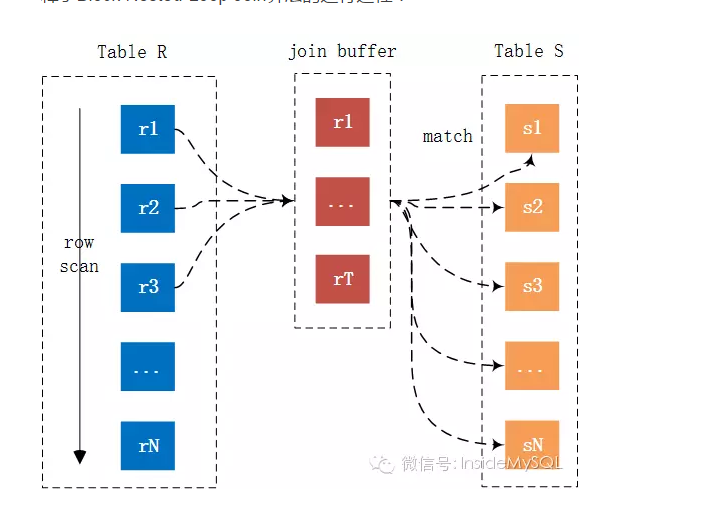
MySQL JOIN原理(转)
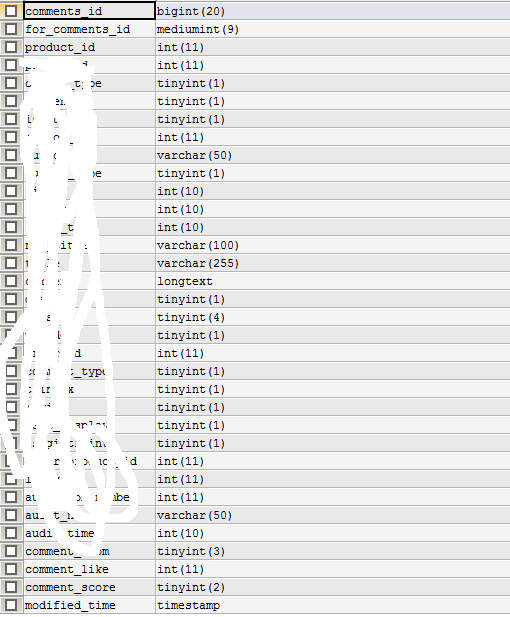
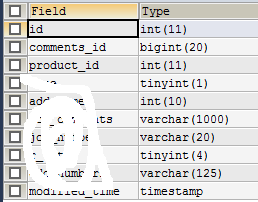
先看一下实验的两张表:
EXPLAIN SELECT * FROM comments gc
JOIN comments_for gcf ON gc.comments_id=gcf.comments_id;

SELECT * FROM comments gc
JOIN comments_for gcf ON gc.comments_id=gcf.comments_id
WHERE gc.comments_id =2056

EXPLAIN SELECT * FROM comments gc
JOIN comments_for gcf ON gc.order_id=gcf.product_id

EXPLAIN SELECT * FROM comments gc
LEFT JOIN comments_for gcf ON gc.comments_id=gcf.comments_id

EXPLAIN SELECT * FROM comments_for gcf
LEFT JOIN comments gc ON gc.comments_id=gcf.comments_id
WHERE gcf.comments_id =2056
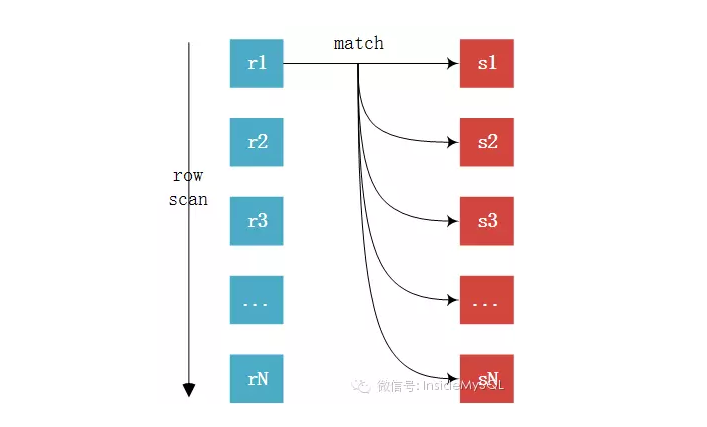
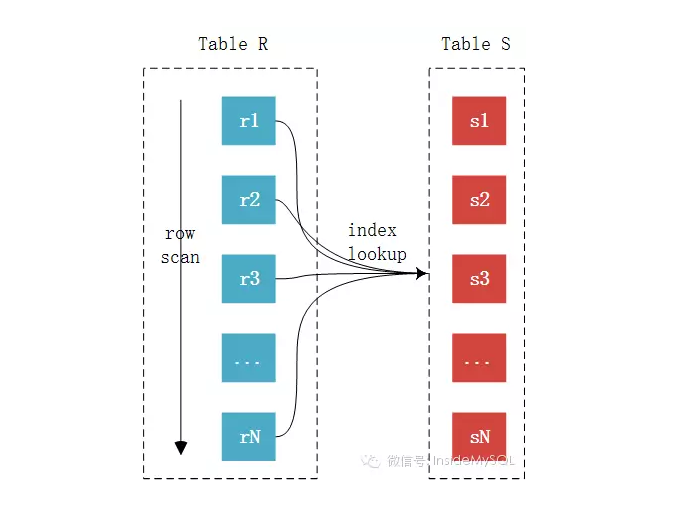
 此,join基本上已经很明了了,未完待续中,欢迎大家指出错误,我会认真改正。。。。
此,join基本上已经很明了了,未完待续中,欢迎大家指出错误,我会认真改正。。。。MySQL JOIN原理(转)的更多相关文章
- MySQL JOIN原理
先看一下实验的两张表: 表comments,总行数28856 表comments_for,总行数57,comments_id是有索引的,ID列为主键. 以上两张表是我们测试的基础,然后看一下索引,co ...
- 由一个场景分析Mysql的join原理
背景 这几天同事写报表,sql语句如下 select * from `sail_marketing`.`mk_coupon_log` a left join `cp0`.`coupon` c on c ...
- MySQL索引原理及慢查询优化
原文:http://tech.meituan.com/mysql-index.html 一个慢查询引发的思考 select count(*) from task where status=2 and ...
- (转)MySQL索引原理及慢查询优化
转自美团技术博客,原文地址:http://tech.meituan.com/mysql-index.html 建索引的一些原则: 1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到 ...
- MySQL索引原理及慢查询优化 转载
原文地址: http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能 ...
- MySQL索引原理及慢查询优化(转)
add by zhj:这是美团点评技术团队的一篇文章,讲的挺不错的. 原文:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰 ...
- 【转载】MySQL索引原理及慢查询优化
原文链接:美团点评技术团队:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型 ...
- MySQL查询原理及其慢查询优化案例分享(转)
MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能出色,但所谓“好马配好鞍”,如何能够更 好的使用它,已经成为开发工程师的必修课,我们经常会从职 ...
- MySQL索引原理与慢查询优化
索引目的 索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql.如果没有索引,那么你可能需要把所有单词看一遍才 ...
随机推荐
- [LeetCode] 88. Merge Sorted Array 合并有序数组
Given two sorted integer arrays nums1 and nums2, merge nums2 into nums1 as one sorted array. Note: T ...
- 【SSH进阶之路】Spring的IOC逐层深入——为什么要使用IOC[实例讲解](二)
上篇博客[SSH进阶之路]Spring简介,搭建Spring环境——轻量级容器框架(一),我们简单的介绍了Spring的基本概念,并且搭建了两个版本的Spring开发环境,但是我们剩下了Spring最 ...
- windows中怎么添加定时任务
linux中有crontab定时任务,很方便 其实windows也有类似的 需求:定时执行python脚本 1.Windows键+R,调出此窗口,输入compmgmt.msc 2. 每分钟都执行一次脚 ...
- 存储Flash--NOR flash和 Nand flash
flash是存储芯片的一种,通过特定的程序可以修改里面的数据.FLASH在电子以及半导体领域内往往表示Flash Memory的意思,即平时所说的“闪存”,全名叫Flash EEPROM Memory ...
- python实践项目七:正则表达式版本的strip()函数
描述:写一个函数,它接受一个字符串,做的事情和 strip()字符串方法一样.如果只传入了要去除的字符串, 没有其他参数, 那么就从该字符串首尾去除空白字符:否则, 函数第二个参数指定的字符将从该字符 ...
- (五)linux 学习 --重定向
The Linux Command Line 读书笔记 - 部分内容来自 http://billie66.github.io/TLCL/book/chap07.html 文章目录 标准输入.输出.错误 ...
- 基于Snappy实现数据压缩和解压
Snappy是谷歌开源的一个用来压缩和解压的开发包.相较其他压缩算法速率有明显的优势,官方文档显示在64位 i7处理器上,每秒可达200~500MB的压缩速度,不禁感叹大厂的算法就是厉害. 开源项目地 ...
- 解决Jupyter notebook安装后不自动跳转网页的方法
在安装完Jupyter notebook后,有童鞋说出现了各种不友好的问题,鉴于此情况,个人先随手写出以下三种情况,并给出解决方法: 题外建议:请使用谷歌浏览器为默认浏览器 一.对于弹不出浏览器的解决 ...
- python实战项目 — 使用bs4 爬取猫眼电影热榜(存入本地txt、以及存储数据库列表)
案例一: 重点: 1. 使用bs4 爬取 2. 数据写入本地 txt from bs4 import BeautifulSoup import requests url = "http:// ...
- oracle数据库 TIMESTAMP(6)时间戳类型
时间戳类型,参数6指的是表示秒的数字的小数点右边可以存储6位数字,最多9位.由于时间戳的精确度很高,我们也常常用来作为版本控制. 插入时,如下方式:insert into test4 values(t ...