MySQL JOIN原理(转)
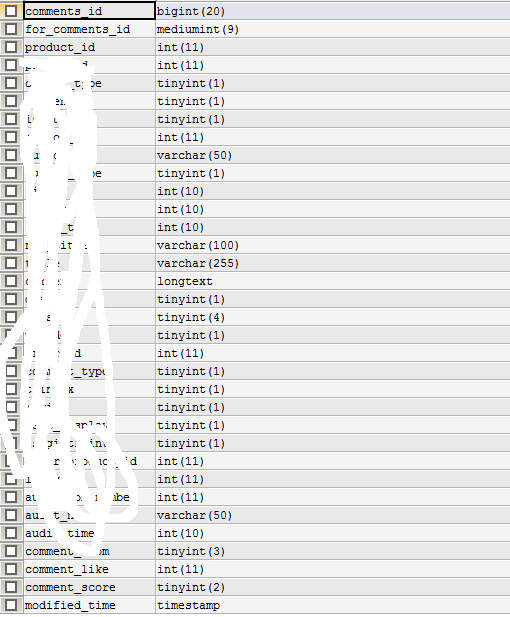
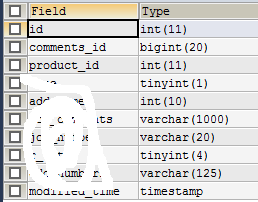
先看一下实验的两张表:
EXPLAIN SELECT * FROM comments gc
JOIN comments_for gcf ON gc.comments_id=gcf.comments_id;

SELECT * FROM comments gc
JOIN comments_for gcf ON gc.comments_id=gcf.comments_id
WHERE gc.comments_id =2056

EXPLAIN SELECT * FROM comments gc
JOIN comments_for gcf ON gc.order_id=gcf.product_id

EXPLAIN SELECT * FROM comments gc
LEFT JOIN comments_for gcf ON gc.comments_id=gcf.comments_id

EXPLAIN SELECT * FROM comments_for gcf
LEFT JOIN comments gc ON gc.comments_id=gcf.comments_id
WHERE gcf.comments_id =2056
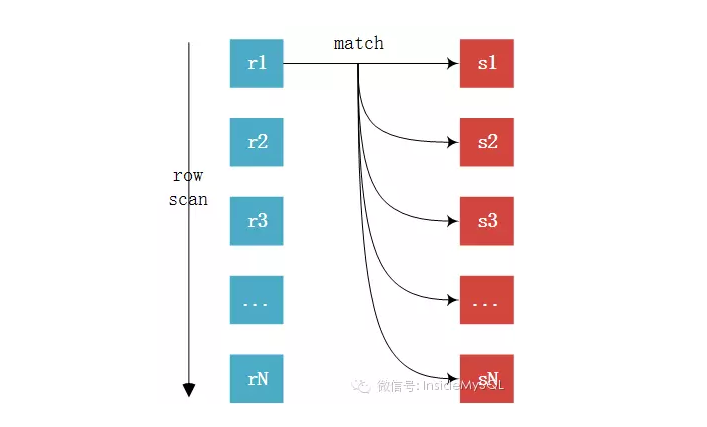
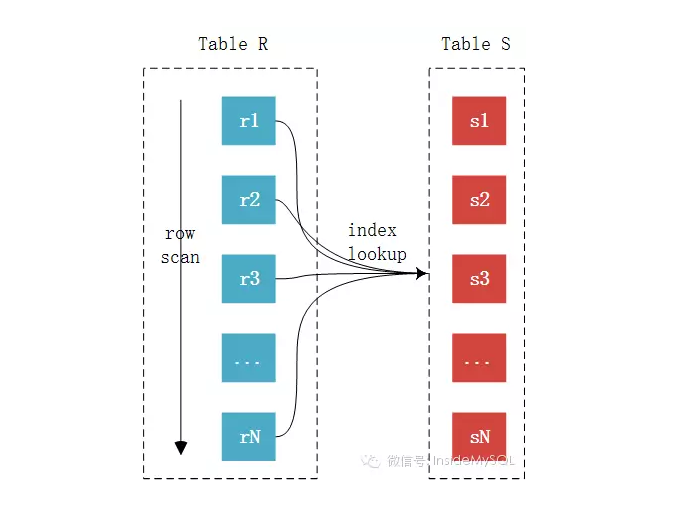
 此,join基本上已经很明了了,未完待续中,欢迎大家指出错误,我会认真改正。。。。
此,join基本上已经很明了了,未完待续中,欢迎大家指出错误,我会认真改正。。。。MySQL JOIN原理(转)的更多相关文章
- MySQL JOIN原理
先看一下实验的两张表: 表comments,总行数28856 表comments_for,总行数57,comments_id是有索引的,ID列为主键. 以上两张表是我们测试的基础,然后看一下索引,co ...
- 由一个场景分析Mysql的join原理
背景 这几天同事写报表,sql语句如下 select * from `sail_marketing`.`mk_coupon_log` a left join `cp0`.`coupon` c on c ...
- MySQL索引原理及慢查询优化
原文:http://tech.meituan.com/mysql-index.html 一个慢查询引发的思考 select count(*) from task where status=2 and ...
- (转)MySQL索引原理及慢查询优化
转自美团技术博客,原文地址:http://tech.meituan.com/mysql-index.html 建索引的一些原则: 1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到 ...
- MySQL索引原理及慢查询优化 转载
原文地址: http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能 ...
- MySQL索引原理及慢查询优化(转)
add by zhj:这是美团点评技术团队的一篇文章,讲的挺不错的. 原文:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰 ...
- 【转载】MySQL索引原理及慢查询优化
原文链接:美团点评技术团队:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型 ...
- MySQL查询原理及其慢查询优化案例分享(转)
MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能出色,但所谓“好马配好鞍”,如何能够更 好的使用它,已经成为开发工程师的必修课,我们经常会从职 ...
- MySQL索引原理与慢查询优化
索引目的 索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql.如果没有索引,那么你可能需要把所有单词看一遍才 ...
随机推荐
- html网页调用本地exe程序的实现方法(转)
https://blog.csdn.net/ilovecr7/article/details/46803711 最近在做一个项目,要什么网页里调exe...开始以为不能实现,后来想想很多就跟淘宝网页上 ...
- [LeetCode] 295. Find Median from Data Stream 找出数据流的中位数
Median is the middle value in an ordered integer list. If the size of the list is even, there is no ...
- logrotate 切割日志
在工作中需要切割日志我们项目中选择的系统自带的logrotate,如需要其他需求需要自己在百度一下或者参考: https://www.cnblogs.com/kevingrace/p/6307298. ...
- 高级UI-画板Canvas
Canvas可以用来绘制直线.点.几何图形.曲线.Bitmap.圆弧等等,做出很多很棒的效果,例如QQ的消息气泡就是使用Canvas画的 Canvas中常用的方法 初始化参数 Paint paint ...
- Postgresql集群解决方案测试报告
1 测试主体 本次测试的主体有3个,分别为: GreenPlum集群,下文简称为GP Postgres-XC集群,下文简称为XC Postgresql单数据库实例,下文简称为pgsql GP和XC都选 ...
- Maven 相关知识点解释
在PC端上面关于Maven的安装等情况我这里就不再复述了,不懂的请自行百度谷歌. 今天聊一下Maven 里面的结构,及相关依赖解释. groupId,artfactId,version,type,cl ...
- SpringBoot(1)
SpringBoot 8/2 CRUD 发送put请求修改数据有三个步骤: SpringMVC中配置HiddenHttpMethodFilter 页面上创建一个post请求(form标签只能写get和 ...
- caurina缓动类
一.简单的缓动 一个实例名为box的正方体,开始alpha为0.5,在两秒内移动到x:300 y:100的位置,alpha变为1.import caurina.transitions.Tweener; ...
- java之hibernate之单向的多对多关联映射
这篇 单向的多对多关联映射 1.如何在权限管理中,角色和权限之间的关系就是多对多的关系,表结构为: 2.类结构 Permission.java public class Permission impl ...
- GitHub预览网页[2019最新]
GitHub预览网页 1. 创建仓库 2. 设置页面预览 3. 上传html 4. 访问网页 1. 创建仓库 登陆GitHub创建仓库 datamoko 添加基本信息: 仓库名.仓库描述,然后点击创建 ...