python通过TimedRotatingFileHandler按时间切割日志
通过TimedRotatingFileHandler按时间切割日志
线上跑了一个定时脚本,每天生成的日志文件都写在了一个文件中。但是日志信息不可能输出到单一的一个文件中。
原因有二:1.日志文件越来越大会影响系统的性能。2.日志文件格式不够清晰,比如我想看今天的日志,不太方便找到的今天的日志信息(即使对日志输出做了时间提示)
通过设置TimedRotatingFileHandler进行日志按周(W)、天(D)、时(H)、分(M)、秒(S)切割。
先看一个简单例子:
import time
import logging
import os
from logging import handlers
def _logging(**kwargs):
level = kwargs.pop('level', None)
filename = kwargs.pop('filename', None)
datefmt = kwargs.pop('datefmt', None)
format = kwargs.pop('format', None)
if level is None:
level = logging.DEBUG
if filename is None:
filename = 'default.log'
if datefmt is None:
datefmt = '%Y-%m-%d %H:%M:%S'
if format is None:
format = '%(asctime)s [%(module)s] %(levelname)s [%(lineno)d] %(message)s'
log = logging.getLogger(filename)
format_str = logging.Formatter(format, datefmt)
# backupCount 保存日志的数量,过期自动删除
# when 按什么日期格式切分(这里方便测试使用的秒)
th = handlers.TimedRotatingFileHandler(filename=filename, when='S', backupCount=3, encoding='utf-8')
th.setFormatter(format_str)
th.setLevel(logging.INFO)
log.addHandler(th)
log.setLevel(level)
return log
os.makedirs("./logs", exist_ok=True)
logger = _logging(filename='./logs/default.log')
if __name__ == '__main__':
while True:
time.sleep(0.1)
logger.info('哈哈哈')
结果如下:
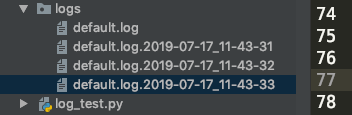
上述代码可以正常运行,而且也可以生成固定的日志个数,但是有一个问题,生成的日志文件格式是你的
文件名+时间的格式,没有设置时间的话默认设置到了秒(这里是按秒切割)
修改日志格式后缀名称:
# 在上述代码中加入
def namer(filename):
return filename.split('default.')
th.namer = namer
# 设置为S,默认的suffix为 Y-%m-%d_%H-%M-%S
th.suffix = "%Y-%m-%d_%H-%M-%S.log"
# 为了看的更视觉效果,可以显示在控制台答应
cmd = logging.StreamHandler()
cmd.setFormatter(format_str)
cmd.setLevel(level)
log.addHandler(cmd)
运行结果:
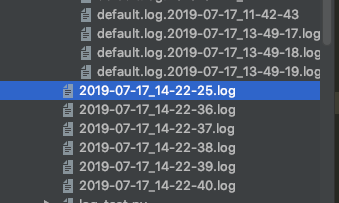
名字好像可以了,但是日志好像没有起到自动删除的目的啊,而且也没在之前的log文件夹了。
来看看源码:
def getFilesToDelete(self):
"""
Determine the files to delete when rolling over.
More specific than the earlier method, which just used glob.glob().
"""
dirName, baseName = os.path.split(self.baseFilename)
fileNames = os.listdir(dirName)
result = []
prefix = baseName + "."
plen = len(prefix)
for fileName in fileNames:
if fileName[:plen] == prefix:
suffix = fileName[plen:]
if self.extMatch.match(suffix):
result.append(os.path.join(dirName, fileName))
if len(result) < self.backupCount:
result = []
else:
result.sort()
result = result[:len(result) - self.backupCount]
return result
这是它的删除逻辑,关键是通过
.前面的字段判断是否重复,当有特定的重复数后开始删除。
所以问题来了,要么自己去重写源码,要么就只能用default.日期.log这种格式了。
附上平时使用的日志代码
import logging
import os
from logging import handlers
def _logging(**kwargs):
level = kwargs.pop('level', None)
filename = kwargs.pop('filename', None)
datefmt = kwargs.pop('datefmt', None)
format = kwargs.pop('format', None)
if level is None:
level = logging.DEBUG
if filename is None:
filename = 'default.log'
if datefmt is None:
datefmt = '%Y-%m-%d %H:%M:%S'
if format is None:
format = '%(asctime)s [%(module)s] %(levelname)s [%(lineno)d] %(message)s'
log = logging.getLogger(filename)
format_str = logging.Formatter(format, datefmt)
def namer(filename):
return filename.split('default.')[1]
# cmd = logging.StreamHandler()
# cmd.setFormatter(format_str)
# cmd.setLevel(level)
# log.addHandler(cmd)
os.makedirs("./debug/logs", exist_ok=True)
th_debug = handlers.TimedRotatingFileHandler(filename="./debug/" + filename, when='D', backupCount=3,
encoding='utf-8')
# th_debug.namer = namer
th_debug.suffix = "%Y-%m-%d.log"
th_debug.setFormatter(format_str)
th_debug.setLevel(logging.DEBUG)
log.addHandler(th_debug)
th = handlers.TimedRotatingFileHandler(filename=filename, when='D', backupCount=3, encoding='utf-8')
# th.namer = namer
th.suffix = "%Y-%m-%d.log"
th.setFormatter(format_str)
th.setLevel(logging.INFO)
log.addHandler(th)
log.setLevel(level)
return log
os.makedirs('./logs', exist_ok=True)
logger = _logging(filename='./logs/default')
python通过TimedRotatingFileHandler按时间切割日志的更多相关文章
- zap+日志分级分文件+按时间切割日志整合demo
实现功能 info debug 级别的日志输出到 /path/log/demo.log warn error .... 级别的日志输出到 /path/log/demo_error.lo ...
- python 多线程日志切割+日志分析
python 多线程日志切割+日志分析 05/27. 2014 楼主最近刚刚接触python,还是个小菜鸟,没有学习python之前可以说楼主的shell已经算是可以了,但用shell很多东西实现起来 ...
- Nginx服务优化及优化深入(配置网页缓存时间、日志切割、防盗链等等)
原文:https://blog.51cto.com/11134648/2134389 默认的Nginx安装参数只能提供最基本的服务,还需要调整如网页缓存时间.连接超时.网页压缩等相应参数,才能发挥出服 ...
- python实现根据当前时间创建目录并输出日志
举个例子:比如我们要实现根据当前时间的年月日来新建目录来存放每天的日志,当前时间作为日志文件名称:代码如下: #!/usr/bin/env python3 # _*_ coding: utf-8 _* ...
- python:利用logbook模块管理日志
日志管理作为软件项目的通用部分,无论是开发还是自动化测试过程中,都显得尤为重要. 最初是打算利用python的logging模块来管理日志的,后来看了些github及其他人的自动化框架设计,做了个比对 ...
- nginx按天切割日志
原文链接:http://www.cnblogs.com/benio/archive/2010/10/13/1849935.html 本文只节选部分内容 Nginx自己没有日志分割的功能,一旦时间过长 ...
- 【转】Python之日期与时间处理模块(date和datetime)
[转]Python之日期与时间处理模块(date和datetime) 本节内容 前言 相关术语的解释 时间的表现形式 time模块 datetime模块 时间格式码 总结 前言 在开发工作中,我们经常 ...
- [Java][log4j]支持同一时候按日期和文件大小切割日志
依据DailyRollingFileAppender和RollingFileAppender改编,支持按日期和文件大小切割日志. 源文件: package com.bao.logging; impo ...
- python统计apache、nginx访问日志IP访问次数并且排序(显示前20条)【转】
前言:python统计apache.nginx访问日志IP访问次数并且排序(显示前20条).其实用awk+sort等命令可以实现,用awk数组也可以实现,这里只是用python尝试下. apach ...
随机推荐
- mingw 构建 mysql-connector-c-6.1.9记录(26种不同的编译错误,甚至做了一个windows系统返回错误码与System V错误码的一个对照表)
http://www.cnblogs.com/oloroso/p/6867162.html
- Win8Metro(C#)数字图像处理--2.30直方图均衡化
原文:Win8Metro(C#)数字图像处理--2.30直方图均衡化 [函数名称] 直方图均衡化函数HistogramEqualProcess(WriteableBitmap src) [算法说明] ...
- 将WriteableBitmap转为byte[]
原文:将WriteableBitmap转为byte[] Win8 metro中的操作与之前的版本有所不同,因此作为一个新手,我将自己的一些问题解答记录了下来,希望与大家分享!! 下面是将Writeab ...
- Android 命令设置获取、IP地址、网关、dns
设置ip root@android:/ # ifconfig eth0 192.168.0.173 netmask 255.255.255.0 ifconfig eth0 192.168.0.173 ...
- JavaScript关于原型的相关内容
function Person () { } Person.prototype.name = 'Alan'; Person.prototype.age = 26; Person.prototype.j ...
- Android零基础入门第62节:搜索框组件SearchView
原文:Android零基础入门第62节:搜索框组件SearchView 一.SearchView概述 SearchView是搜索框组件,它可以让用户在文本框内输入文字,并允许通过监听器监控用户输入,当 ...
- Windows 10 版本信息
原文 https://technet.microsoft.com/zh-cn/windows/release-info Windows 10 版本信息 Microsoft 已更新其服务模型. 半年频道 ...
- 如何在 Linux 中添加一块大于 2TB 的新磁盘?
你有没有试过使用 fdisk 对大于 2TB 的硬盘进行分区,并且纳闷为什么会得到需要使用 GPT 的警告? 是的,你看到的没错.我们无法使用 fdisk 对大于 2TB 的硬盘进行分区. 在这种情况 ...
- 常用json解析库比较及选择 fastjson & gson
一.常用json解析库比较及选择 1.简介 fastjson和gson是目前比较常用的json解析库,并且现在我们项目代码中,也在使用这两个解析库. fastjson 是由阿里开发的,号称是处理jso ...
- window下搭建qt开发环境编译、引用ace
工作中经常用到ace.tao等,在windwo下的c++开发工具基本上就是vs20xx这些工具,还有些就是类似编辑工具例如:source insight等,前者比较大,打开.编译运行比较慢,二期针对a ...