模型量化原理及tflite示例
模型量化
什么是量化
模型的weights数据一般是float32的,量化即将他们转换为int8的。当然其实量化有很多种,主流是int8/fp16量化,其他的还有比如
- 二进制神经网络:在运行时具有二进制权重和激活的神经网络,以及在训练时计算参数的梯度。
- 三元权重网络:权重约束为+1,0和-1的神经网络
- XNOR网络:过滤器和卷积层的输入是二进制的。 XNOR 网络主要使用二进制运算来近似卷积。
现在很多框架或者工具比如nvidia的TensorRT,xilinx的DNNDK,TensorFlow,PyTorch,MxNet 等等都有量化的功能.
量化的优缺点
量化的优点很明显了,int8占用内存更少,运算更快,量化后的模型可以更好地跑在低功耗嵌入式设备上。以应用到手机端,自动驾驶等等。
缺点自然也很明显,量化后的模型损失了精度。造成模型准确率下降.
量化的原理
先来看一下计算机如何存储浮点数与定点数:
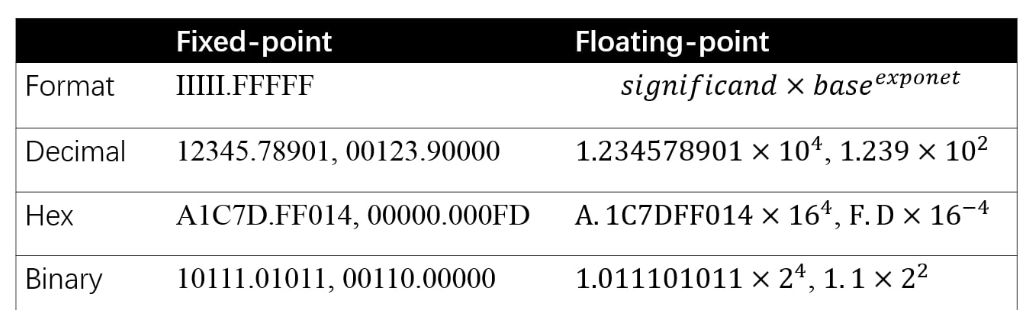
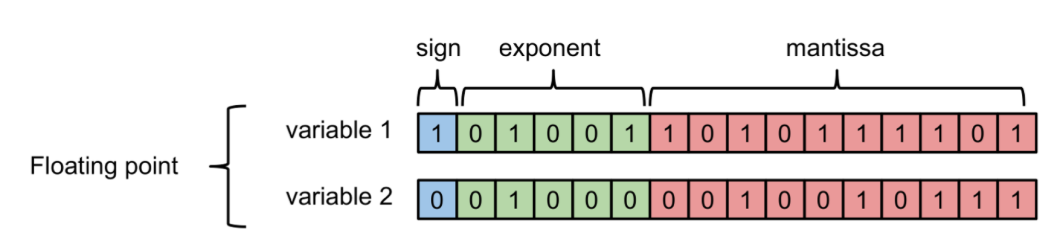
其中负指数决定了浮点数所能表达的绝对值最小的非零数;而正指数决定了浮点数所能表达的绝对值最大的数,也即决定了浮点数的取值范围。
float的范围为-2^128 ~ +2^128. 可以看到float的值域分布是极其广的。
说回量化的本质是:找到一个映射关系,使得float32与int8能够一一对应。那问题来了,float32能够表达值域是非常广的,而int8只能表达[0,255].
怎么能够用255个数代表无限多(其实也不是无限多,很多,但是也还是有限个)的浮点数?
幸运地是,实践证明,神经网络的weights往往是集中在一个非常狭窄的范围,如下:
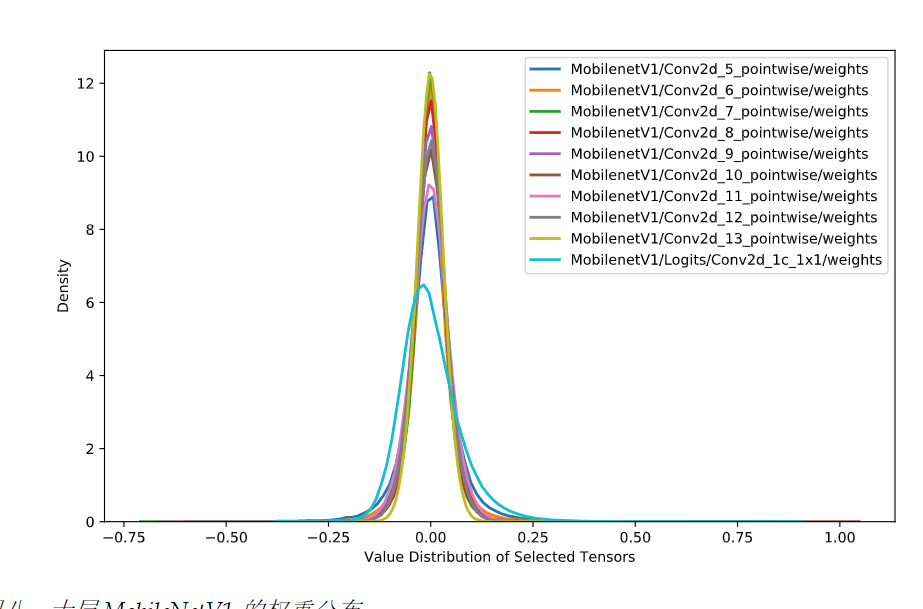
所以这个问题解决了,即我们并不需要对值域-2^128 ~ +2^128的所有值都做映射。但即便是一个很小的范围,比如[-1,1]能够表达的浮点数也是非常多的,所以势必
会有多个浮点数被映射成同一个int8整数.从而造成精度的丢失.
这时候,第二个问题来了,为什么量化是有效的,为什么weights变为int8后,并不会让模型的精度下降太多?
在搜索了大量的资料以后,我发现目前并没有一个很严谨的理论解释这个事情.
您可能会问为什么量化是有效的(具有足够好的预测准确度),尤其是将 FP32 转换为 INT8 时已经丢失了信息?严格来说,目前尚未出现相关的严谨的理论。一个直觉解释是,神经网络被过度参数化,进而包含足够的冗余信息,裁剪这些冗余信息不会导致明显的准确度下降。相关证据是,对于给定的量化方法,FP32 网络和 INT8 网络之间的准确度差距对于大型网络来说较小,因为大型网络过度参数化的程度更高
和深度学习模型一样,很多时候,我们无法解释为什么有的参数就是能work,量化也是一样,实践证明,量化损失的精度不会太多,do not know why it works,it just works.
如何做量化
由以下公式完成float和int8之间的相互映射.
\(x_{float} = x_{scale} \times (x_{quantized} - x_{zero\_point})\)
其中参数由以下公式确定:

举个例子,假设原始fp32模型的weights分布在[-1.0,1.0],要映射到[0,255],则\(x_{scale}=2/255\),\(x_{zero\_point}=255-1/(2/255)=127\)
量化后的乘法和加法:
依旧以上述例子为例:
我们可以得到0.0:127,1.0:255的映射关系.
那么原先的0.0 X 1.0 = 0.0 注意:并非用127x255再用公式转回为float,这样算得到的float=(2/255)x(127x255-127)=253

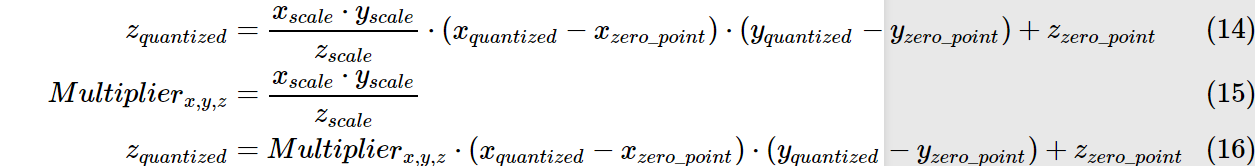
我们假设所有layer的数据分布都是一致的.则根据上述公式可得\(z_{quantized}=127\),再将其转换回float32,即0.0.
同理加法:

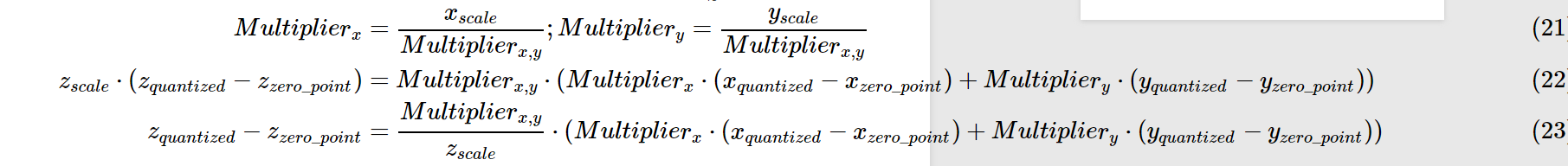
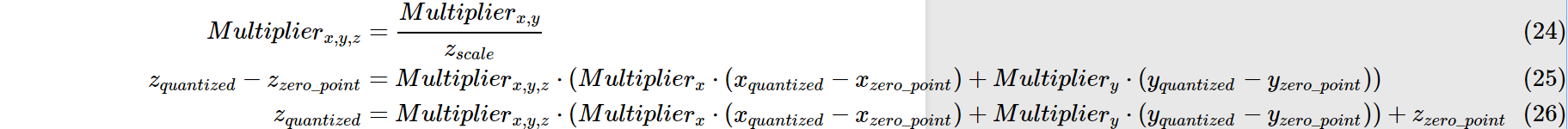
tflite_convert
日常吐槽:tensorflow sucks. tensorflow要不是大公司开发的,绝对不可能这么流行. 文档混乱,又多又杂,api难理解难使用.
tensorflow中使用tflite_convert做模型量化.用法:
tflite_convert \
--output_file=/tmp/foo.cc \
--graph_def_file=/tmp/mobilenet_v1_0.50_128/frozen_graph.pb \
--inference_type=QUANTIZED_UINT8 \
--input_arrays=input \
--output_arrays=MobilenetV1/Predictions/Reshape_1 \
--default_ranges_min=0 \
--default_ranges_max=6 \
--mean_values=128 \
--std_dev_values=127
官方指导:https://www.tensorflow.org/lite/convert/cmdline_examples
关于各参数的说明参见:
https://www.tensorflow.org/lite/convert/cmdline_reference
关于参数mean_values,std_dev_values比较让人困惑.tf的文档里,对这个参数的描述有3种形式.
- (mean, std_dev)
- (zero_point, scale)
- (min,max)
转换关系如下:
std_dev = 1.0 / scale
mean = zero_point
mean = 255.0*min / (min - max)
std_dev = 255.0 / (max - min)
结论:
训练时模型的输入tensor的值在不同范围时,对应的mean_values,std_dev_values分别如下:
- range (0,255) then mean = 0, std_dev = 1
- range (-1,1) then mean = 127.5, std_dev = 127.5
- range (0,1) then mean = 0, std_dev = 255
参考:
https://heartbeat.fritz.ai/8-bit-quantization-and-tensorflow-lite-speeding-up-mobile-inference-with-low-precision-a882dfcafbbd
https://stackoverflow.com/questions/54830869/understanding-tf-contrib-lite-tfliteconverter-quantization-parameters/58096430#58096430
https://arleyzhang.github.io/articles/923e2c40/
https://zhuanlan.zhihu.com/p/79744430
https://zhuanlan.zhihu.com/p/58182172
模型量化原理及tflite示例的更多相关文章
- Optaplanner规划引擎的工作原理及简单示例(2)
开篇 在前面一篇关于规划引擎Optapalnner的文章里(Optaplanner规划引擎的工作原理及简单示例(1)),老农介绍了应用Optaplanner过程中需要掌握的一些基本概念,这些概念有且于 ...
- tensorflow模型量化实例
1,概述 模型量化应该是现在最容易实现的模型压缩技术,而且也基本上是在移动端部署的模型的毕竟之路.模型量化基本可以分为两种:post training quantizated和quantization ...
- deeplearning模型量化实战
deeplearning模型量化实战 MegEngine 提供从训练到部署完整的量化支持,包括量化感知训练以及训练后量化,凭借"训练推理一体"的特性,MegEngine更能保证量化 ...
- 大数据运算模型 MapReduce 原理
大数据运算模型 MapReduce 原理 2016-01-24 杜亦舒 MapReduce 是一个大数据集合的并行运算模型,由google提出,现在流行的hadoop中也使用了MapReduce作为计 ...
- tensorflow模型量化
tensorflow模型量化/DATA/share/DeepLearning/code/tensorflow/bazel-bin/tensorflow/tools/graph_transforms/t ...
- Python进阶(十六)----面向对象之~封装,多态,鸭子模型,super原理(单继承原理,多继承原理)
Python进阶(十六)----面向对象之~封装,多态,鸭子模型,super原理(单继承原理,多继承原理) 一丶封装 , 多态 封装: 将一些东西封装到一个地方,你还可以取出来( ...
- CUDA上深度学习模型量化的自动化优化
CUDA上深度学习模型量化的自动化优化 深度学习已成功应用于各种任务.在诸如自动驾驶汽车推理之类的实时场景中,模型的推理速度至关重要.网络量化是加速深度学习模型的有效方法.在量化模型中,数据和模型参数 ...
- Pytorch模型量化
在深度学习中,量化指的是使用更少的bit来存储原本以浮点数存储的tensor,以及使用更少的bit来完成原本以浮点数完成的计算.这么做的好处主要有如下几点: 更少的模型体积,接近4倍的减少: 可以更快 ...
- TensorFlow 8 bit模型量化
本文基本参考自这篇文章:8-Bit Quantization and TensorFlow Lite: Speeding up mobile inference with low precision ...
随机推荐
- 2018.8.13 python中生成器和生成器表达式
主要内容: 1.生成器和生成器函数 2.列表推导式 一.生成器 生成器是指就是迭代器,在python中有三种方式来获取生成器: 1.通过生成器函数 2.通过各种推导式来实现生成器 3.通过数据的转换也 ...
- $POJ2942\ Knights\ of\ the\ Round\ Table$ 图论
正解:图论 解题报告: 传送门! 一道,综合性比较强的题(我是萌新刚学$OI$我只是想练下$tarjan$,,,$QAQ$ 考虑先建个补图,然后现在就变成只有相互连边的点不能做邻居.所以如果有$K$个 ...
- Mybaits 源码解析 (七)----- Select 语句的执行过程分析(下篇)(Mapper方法是如何调用到XML中的SQL的?)全网最详细,没有之一
我们上篇文章讲到了查询方法里面的doQuery方法,这里面就是调用JDBC的API了,其中的逻辑比较复杂,我们这边文章来讲,先看看我们上篇文章分析的地方 SimpleExecutor public & ...
- 使用float设置经典的网站前端结构
float浮动是能使得标签脱离文档流,此处脱离文档流,是指此便签后面的,没有脱离文档流的标签将此标签当作透明,按正常来布局. float脱离文档流,是受到父级范围限制的,在父级范围内脱离文档流,脱离文 ...
- Springboot中使用自定义参数注解获取 token 中用户数据
使用自定义参数注解获取 token 中User数据 使用背景 在springboot项目开发中需要从token中获取用户信息时通常的方式要经历几个步骤 拦截器中截获token TokenUtil工具类 ...
- Java零基础入门之常用工具
Java异常 什么是异常? 在程序运行过程中,意外发生的情况,背离我们程序本身的意图的表现,都可以理解为异常. throwable是所有异常的根类,异常分为两种异常exception和error Er ...
- 网络安全-主动信息收集篇第二章-二层网络扫描之scapy
scapy是python第三方库文件,可以使用python进行调用也单独进行使用. 非常强大可以用于抓包.分析.创建.修改.注入网络流量. 使用scapy 详细使用方式可以查看github:https ...
- day 2 下午 骑士 基环树+树形DP
#include<iostream> #include<cstdio> #include<cstring> #include<cstdlib> #inc ...
- Java描述设计模式(18):享元模式
本文源码:GitHub·点这里 || GitEE·点这里 一.使用场景 应用代码 public class C01_InScene { public static void main(String[] ...
- 『题解』洛谷P3958 奶酪
Portal Portal1: Luogu Portal2: LibreOJ Portal3: Vijos Description 现有一块大奶酪,它的高度为\(h\),它的长度和宽度我们可以认为是无 ...