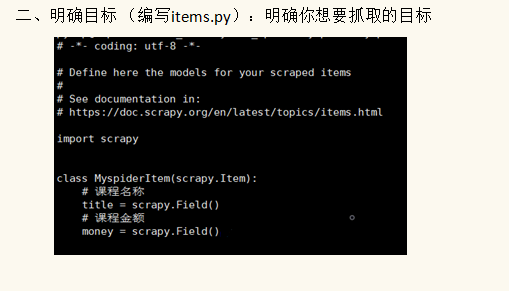
scrapy框架介绍及安装
什么是scrapy框架?

scrapy框架的安装
1.windowes下的安装
Python 2 / 3
升级pip版本:
pip install --upgrade pip
通过pip 安装 Scrapy 框架
pip install scrapy
2.Ubuntu下的安装
Ubuntu 需要9.10或以上版本安装方式
Python 2 / 3
安装非Python的依赖
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
通过pip 安装 Scrapy 框架
sudo pip install scrapy
具体Scrapy安装流程参考:http://doc.scrapy.org/en/latest/intro/install.html#intro-install-platform-notes 里面有各个平台的安装方法
3.scrapy的运行流程

Scrapy构架解析:Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
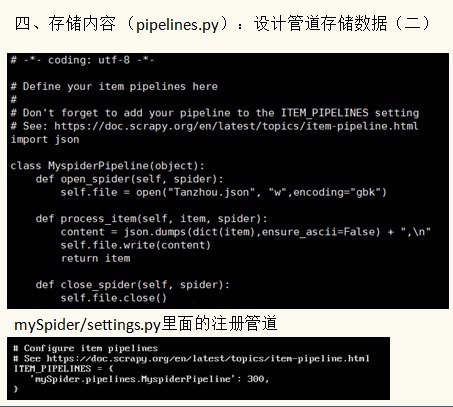
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
4.部分问题解答



scrapy框架介绍及安装的更多相关文章
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- Scrapy框架——介绍、安装、命令行创建,启动、项目目录结构介绍、Spiders文件夹详解(包括去重规则)、Selectors解析页面、Items、pipelines(自定义pipeline)、下载中间件(Downloader Middleware)、爬虫中间件、信号
一 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Scrapy的用途十分广泛,可 ...
- hue框架介绍和安装部署
大家好,我是来自内蒙古的小哥,我现在在北京学习大数据,我想把学到的东西分享给大家,想和大家一起学习 hue框架介绍和安装部署 hue全称:HUE=Hadoop User Experience 他是cl ...
- 爬虫之Scrapy框架介绍
Scrapy介绍 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内 ...
- scrapy框架介绍
一,介绍 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性 ...
- python爬虫之scrapy框架介绍
一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等) ...
- 爬虫相关-scrapy框架介绍
性能相关-进程.线程.协程 在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下请求URL时必然会引起等待,从而使得请求整体变慢. 串行执行 import requests def fetc ...
- Scrapy框架学习(一)Scrapy框架介绍
Scrapy框架的架构图如上. Scrapy中的数据流由引擎控制,数据流的过程如下: 1.Engine打开一个网站,找到处理该网站的Spider,并向该Spider请求第一个要爬取得URL. 2.En ...
- Scrapy 框架介绍
Scrapy 框架 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试. ...
随机推荐
- bootstrap网格系统.html
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title&g ...
- vue条件渲染2
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- SpringBoot 逻辑异常统一处理
构建项目 我们将逻辑异常核心处理部分提取出来作为单独的jar供其他模块引用,创建项目在parent项目pom.xml添加公共使用的依赖,配置内容如下所示: <dependencies> & ...
- URL中文参数,JSON转换,PHP赋值JS
var jsonProps = { "dispMode":dispMode, "autoRun":autoRun, "clientPath" ...
- 痞子衡嵌入式:飞思卡尔i.MX RTyyyy系列MCU硬件那些事(2.2)- 在串行NOR Flash XIP调试原理
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是飞思卡尔i.MX RTyyyy系列EVK在串行NOR Flash调试的原理. 本文是i.MXRT硬件那些事系列第二篇的续集,在第二篇首集 ...
- 爬虫基本库的使用---requests库
使用requests---实现Cookies.登录验证.代理设置等操作 处理网页验证和Cookies时,需要写Opener和Handler来处理,为了更方便地实现这些操作,就有了更强大的库reques ...
- Pytorch数据集读入——Dataset类,实现数据集打乱Shuffle
在进行相关平台的练习过程中,由于要自己导入数据集,而导入方法在市面上五花八门,各种库都可以应用,在这个过程中我准备尝试torchvision的库dataset torchvision.datasets ...
- C++:类中创建线程
#include <iostream> #include <stdio.h> #include <stdlib.h> #include <iostream&g ...
- MinIO 参数解析与限制
MinIO 参数解析与限制 MinIO server 在默认情况下会将所有配置信息存到 ${HOME}/.minio/config.json 文件中. 以下部分提供每个字段的详细说明以及如何自定义它们 ...
- 安全路径——最短路径树+dsu缩边
题目描述 思路 首先想到$dijkstra$跑完之后$build$一棵最短路径树.要找到每个节点i到根的满足要求的最短路,考虑把一些非树边加进去. 对于非树边$(u,v)$,因为节点i上方的边被占领, ...