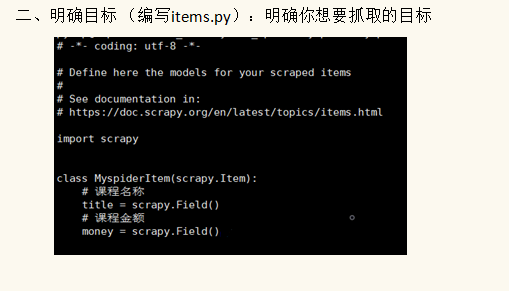
scrapy框架介绍及安装
什么是scrapy框架?

scrapy框架的安装
1.windowes下的安装
Python 2 / 3
升级pip版本:
pip install --upgrade pip
通过pip 安装 Scrapy 框架
pip install scrapy
2.Ubuntu下的安装
Ubuntu 需要9.10或以上版本安装方式
Python 2 / 3
安装非Python的依赖
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
通过pip 安装 Scrapy 框架
sudo pip install scrapy
具体Scrapy安装流程参考:http://doc.scrapy.org/en/latest/intro/install.html#intro-install-platform-notes 里面有各个平台的安装方法
3.scrapy的运行流程

Scrapy构架解析:Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
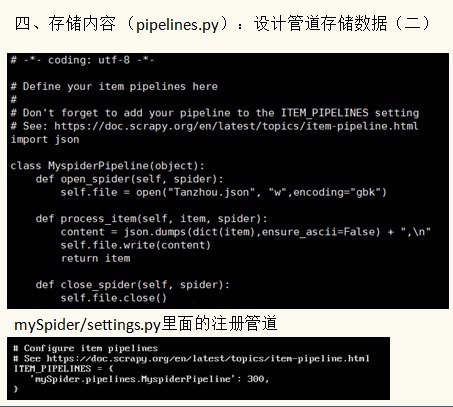
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
4.部分问题解答



scrapy框架介绍及安装的更多相关文章
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- Scrapy框架——介绍、安装、命令行创建,启动、项目目录结构介绍、Spiders文件夹详解(包括去重规则)、Selectors解析页面、Items、pipelines(自定义pipeline)、下载中间件(Downloader Middleware)、爬虫中间件、信号
一 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Scrapy的用途十分广泛,可 ...
- hue框架介绍和安装部署
大家好,我是来自内蒙古的小哥,我现在在北京学习大数据,我想把学到的东西分享给大家,想和大家一起学习 hue框架介绍和安装部署 hue全称:HUE=Hadoop User Experience 他是cl ...
- 爬虫之Scrapy框架介绍
Scrapy介绍 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内 ...
- scrapy框架介绍
一,介绍 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性 ...
- python爬虫之scrapy框架介绍
一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等) ...
- 爬虫相关-scrapy框架介绍
性能相关-进程.线程.协程 在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下请求URL时必然会引起等待,从而使得请求整体变慢. 串行执行 import requests def fetc ...
- Scrapy框架学习(一)Scrapy框架介绍
Scrapy框架的架构图如上. Scrapy中的数据流由引擎控制,数据流的过程如下: 1.Engine打开一个网站,找到处理该网站的Spider,并向该Spider请求第一个要爬取得URL. 2.En ...
- Scrapy 框架介绍
Scrapy 框架 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试. ...
随机推荐
- NetworkManager网络通讯_NetworkLobbyManager(三)
此部分可以先建立游戏大厅,然后进入游戏,此处坑甚多耗费大量时间.国内百度出来的基本没靠谱的,一些专栏作家大V也不过是基本翻译了一下用户手册(坑啊),只能通过看youtube视频以及不停的翻阅用户手册解 ...
- IoTClient开发3 - ModBusTcp协议客户端实现
前言 进过前面两章的介绍,今天开始正式的实战. 进制转换 很多朋友对于进制转换可能是在刚学计算机的时候有接触,后来做高级语言开发可能就慢慢忘记了.我们做工控开发的时候需要经常进行进制转换,这里和大家一 ...
- [转载]制作QT字库文件
原文地址:http://www.cnblogs.com/liu_xf/archive/2011/07/05/2098144.htm 摘要: QT4.7.0在移植到开发板上的时候,中文支持是必不可少的, ...
- python3 range 倒序
话不多说上代码,要求简单,从100到1遍历操作. //第三个参数表示的是100所有进行的操作,每次加上-1,直到0 for i in range(100,0,-1): print(i)
- 爬取bing背景图片
因为工作环境的原因,没办法用梯子,也不喜欢用某度,只能用bing,发现背景图片蛮好看的,刚好最近在学习摄影,需要提高审美,就想着把bing背景图片都爬去下来做桌面背景.写的代码比较入门,只是做个记录, ...
- 学习笔记30_ORM框架
*在以往DAL层中,操作数据库使用DataTable,如果使得数据表DataTable转为List<>的话,写错属性名,在编译阶段是查不出来的,而ORM框架能解决此问题. *ORM是指面向 ...
- NOIP模拟 11
差点迟到没赶上开题 开题后看了T1,好像一道原题,没分析复杂度直接敲了个NC线段树,敲了个暴力,敲了个对拍,就1h了.. 对拍还对出错了,发现标记下传有点问题,改了以后对拍通过,就把T1扔掉看T2 觉 ...
- 搜索框(SearchView)用法
SearchView是Android原生的搜索框控件,它提供了一个用户界面,可以让用户在文本框内输入文字,并允许通过看监听器监控用户输入,当用户输入完成后提交搜索时,也可通过监听器执行实际的搜索. S ...
- Linux 学习(1) | 学习方向导图
方向导图 文件系统导图 内核导图
- LINQ学习——Group
一.Group的作用 1.Group字句把select的对象根据一些标准进行分组. 2.从查询表达式返回的对象是从查询中枚举分组结果的可枚举类型. 3.每一个分组由一个叫做键的字段区分. 4.每一个分 ...