数据结构-哈夫曼树(python实现)
好,前面我们介绍了一般二叉树、完全二叉树、满二叉树,这篇文章呢,我们要介绍的是哈夫曼树。
哈夫曼树也叫最优二叉树,与哈夫曼树相关的概念还有哈夫曼编码,这两者其实是相同的。哈夫曼编码是哈夫曼在1952年提出的。现在哈夫曼编码多应用在文本压缩方面。接下来,我们就来介绍哈夫曼树到底是个什么东西?哈夫曼编码又是什么,以及它如何应用于文本压缩。
哈夫曼树(Huffman Tree)
给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
首先,我们有这样一些数据:
sourceData = [('a', 8), ('b', 5), ('c', 3), ('d', 3), ('e', 8), ('f', 6), ('g', 2), ('h', 5), ('i', 9), ('j', 5), ('k', 7), ('l', 5), ('m', 10), ('n', 9)]
每一个数据项是一个元组,元组的第一项是数据内容,第二项是该数据的权重。也就是说,用于构建哈夫曼树的数据是带权重的。假设这些数据里面的字母a-n的权重是根据这些字母在y一个文本出出现的概率计算得出的,字母出现的概率越高,则该字母的权重越大。例如字母 a 的权重为 8 .
好,拿到数据我们就可以来构建哈夫曼树了。
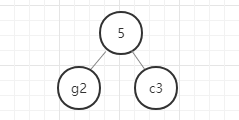
- 首先,找出所有元素中权重最小的两个元素,即g(2)和c(3),
- 以g和c为子节点构建二叉树,则构建的二叉树的父节点的权重为 2+3 = 5.
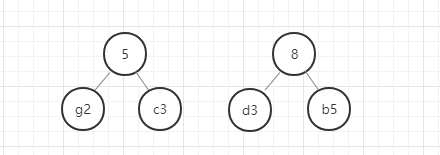
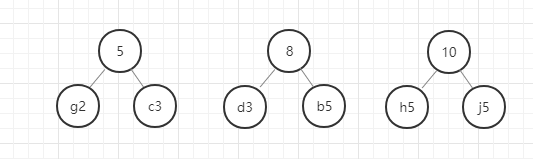
- 从除g和c以外剩下的元素和新构建的权重为5的节点中选出权重最小的两个节点,
- 进行第 2 步操作。
以此类推,直至最后合成一个二叉树就是哈夫曼树。
我们用图例来表示一下:
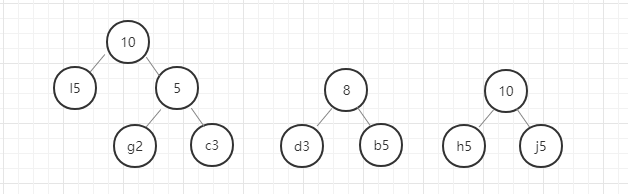
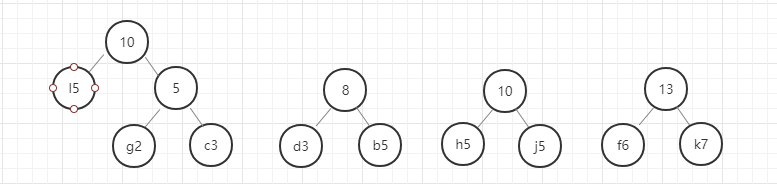
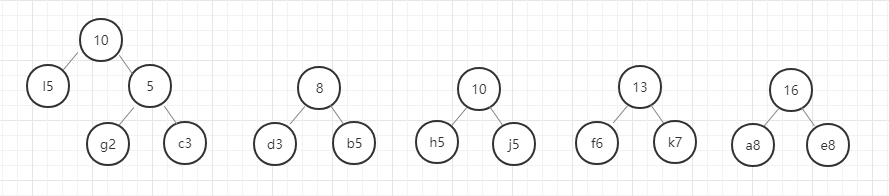
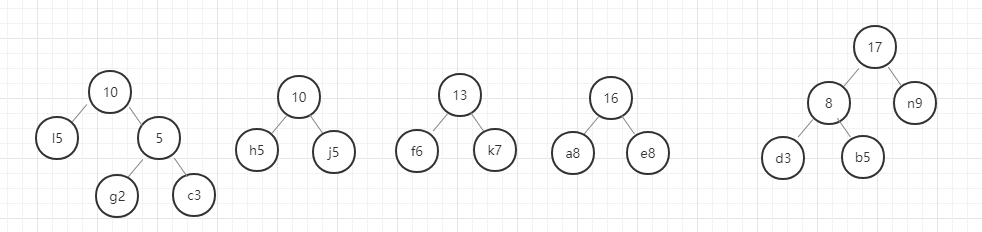
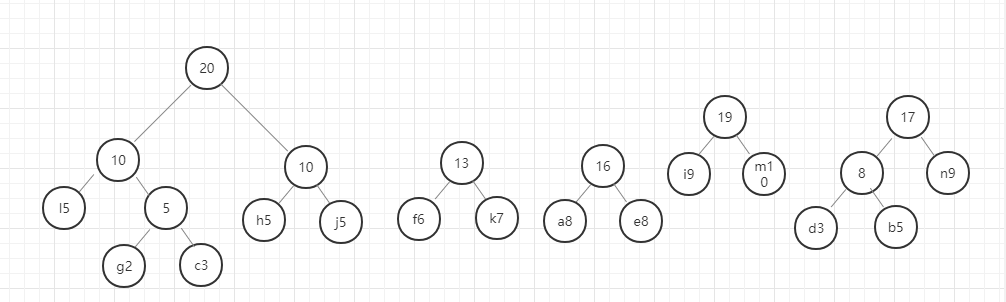
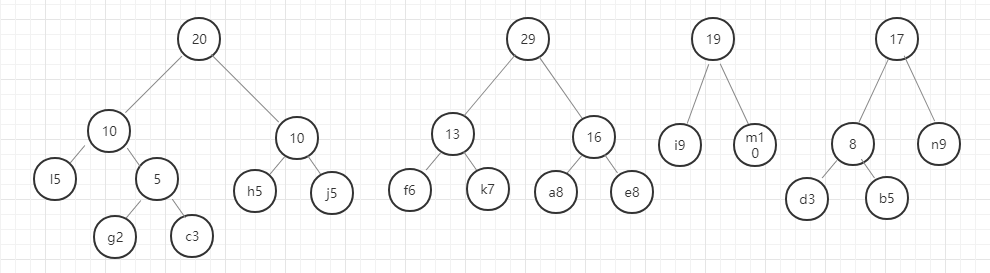
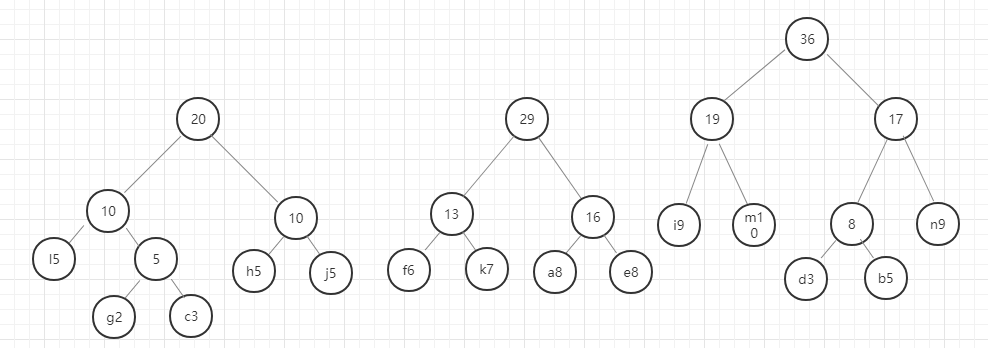
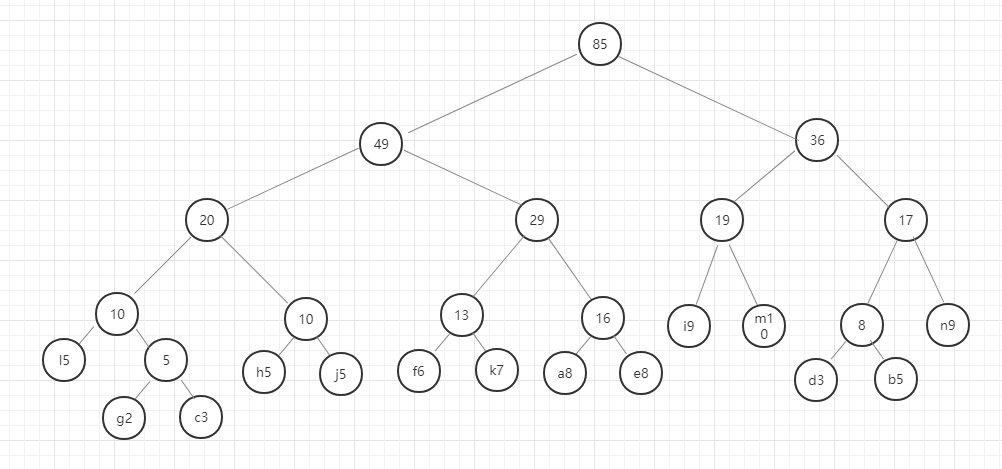
好,这里我们的哈夫曼树就构建好了,节点中字母后面的数字表示该字母的权重,就是前面给定的数据。在这里我要强调的是,同样的数据创建的哈夫曼树并不是唯一的,所以只要按照规则一步一步没有出错,你的哈夫曼树就是正确的。
我们现在将访问左节点定义为0,访问右节点定义为1.则我们现在访问字母a,则它的编码为0110,访问字母n的编码为111,这个编码就是哈夫曼编码。
通过比对不同字母的哈夫曼编码,你发现了什么?
权重越大的字母对应的哈夫曼编码越短,权重越小的字母对应的哈夫曼编码则越长。也就是说文本中出现概率大的字母编码短,出现概率小的字母编码长。通过这种编码方式来表示文本中的字母,那所得整个文本的编码长度也会缩短。
这就是哈夫曼树也就是哈夫曼编码在文本压缩中的应用。
下面我们用代码来实现:
定义一个二叉树类:
class BinaryTree:
def __init__(self, data, weight):
self.data = data
self.weight = weight
self.left = None
self.right = None
获取节点列表中权重最小的两个节点:
# 定义获取列表中权重最大的两个节点的方法:
def min2(li):
result = [BinaryTree(None, float('inf')), BinaryTree(None, float('inf'))]
li2 = []
for i in range(len(li)):
if li[i].weight < result[0].weight:
if result[1].weight != float('inf'):
li2.append(result[1])
result[0], result[1] = li[i], result[0]
elif li[i].weight < result[1].weight:
if result[1].weight != float('inf'):
li2.append(result[1])
result[1] = li[i]
else:
li2.append(li[i])
return result, li2
定义生成哈夫曼树的方法:
def makeHuffman(source):
m2, data = min2(source)
print(m2[0].data, m2[1].data)
left = m2[0]
right = m2[1]
sumLR = left.weight + right.weight
father = BinaryTree(None, sumLR)
father.left = left
father.right = right
if data == []:
return father
data.append(father)
return makeHuffman(data)
定义广度优先遍历方法:
# 递归方式实现广度优先遍历
def breadthFirst(gen, index=0, nextGen=[], result=[]):
if type(gen) == BinaryTree:
gen = [gen]
result.append((gen[index].data, gen[index].weight))
if gen[index].left != None:
nextGen.append(gen[index].left)
if gen[index].right != None:
nextGen.append(gen[index].right)
if index == len(gen)-1:
if nextGen == []:
return
else:
gen = nextGen
nextGen = []
index = 0
else:
index += 1
breadthFirst(gen, index, nextGen,result)
return result
输入数据:
# 某篇文章中部分字母根据出现的概率规定权重
sourceData = [('a', 8), ('b', 5), ('c', 3), ('d', 3), ('e', 8), ('f', 6), ('g', 2), ('h', 5), ('i', 9), ('j', 5), ('k', 7), ('l', 5), ('m', 10), ('n', 9)]
sourceData = [BinaryTree(x[0], x[1]) for x in sourceData]
创建哈夫曼树并进行广度优先遍历:
huffman = makeHuffman(sourceData)
print(breadthFirst(huffman))
OK ,我们的哈夫曼树就介绍到这里了,你还有什么不懂的问题记得留言给我哦。
数据结构-哈夫曼树(python实现)的更多相关文章
- C#数据结构-赫夫曼树
什么是赫夫曼树? 赫夫曼树(Huffman Tree)是指给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小.哈夫曼树(也称为最优二叉树)是带权路径长度最短的树,权值较大的结点 ...
- Java数据结构和算法(四)赫夫曼树
Java数据结构和算法(四)赫夫曼树 数据结构与算法目录(https://www.cnblogs.com/binarylei/p/10115867.html) 赫夫曼树又称为最优二叉树,赫夫曼树的一个 ...
- 数据结构图文解析之:哈夫曼树与哈夫曼编码详解及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- 【数据结构】赫夫曼树的实现和模拟压缩(C++)
赫夫曼(Huffman)树,由发明它的人物命名,又称最优树,是一类带权路径最短的二叉树,主要用于数据压缩传输. 赫夫曼树的构造过程相对比较简单,要理解赫夫曼数,要先了解赫夫曼编码. 对一组出现频率不同 ...
- Android版数据结构与算法(七):赫夫曼树
版权声明:本文出自汪磊的博客,未经作者允许禁止转载. 近期忙着新版本的开发,此外正在回顾C语言,大部分时间没放在数据结构与算法的整理上,所以更新有点慢了,不过既然写了就肯定尽力将这部分完全整理好分享出 ...
- 6-9-哈夫曼树(HuffmanTree)-树和二叉树-第6章-《数据结构》课本源码-严蔚敏吴伟民版
课本源码部分 第6章 树和二叉树 - 哈夫曼树(HuffmanTree) ——<数据结构>-严蔚敏.吴伟民版 源码使用说明 链接☛☛☛ <数据结构-C语言版> ...
- 20172332 2017-2018-2 《程序设计与数据结构》Java哈夫曼编码实验--哈夫曼树的建立,编码与解码
20172332 2017-2018-2 <程序设计与数据结构>Java哈夫曼编码实验--哈夫曼树的建立,编码与解码 哈夫曼树 1.路径和路径长度 在一棵树中,从一个结点往下可以达到的孩子 ...
- hdu 2527:Safe Or Unsafe(数据结构,哈夫曼树,求WPL)
Safe Or Unsafe Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)To ...
- 数据结构之C语言实现哈夫曼树
1.基本概念 a.路径和路径长度 若在一棵树中存在着一个结点序列 k1,k2,……,kj, 使得 ki是ki+1 的双亲(1<=i<j),则称此结点序列是从 k1 到 kj 的路径. 从 ...
随机推荐
- IIS上.net注册
如果先安装了.Net平台,后再安装IIS,那么在IIS中可能就没有出现ASP.NET版本的下拉菜单,这是我们可手动注册.Net 一般.Net版本都存放在:C:\WINDOWS\Microsoft.NE ...
- UILabel实现自适应宽高需要注意的地方
需求如下: 需要显示2行文字,宽度为 SCREEN_Width - 40 高度为两行文本的自适应高度 需要在此UILabel 下面添加imageView , 因此UIlabel 的高度需要准确,不 ...
- 快速开发平台 WebBuilder 8.6发布
WebBuilder下载:http://www.geejing.com/download.html WebBuilder快速开发平台是基于Web面向服务的应用系统开发平台,可以方便快捷的搭建各类型企业 ...
- Qt动画效果的幕后英雄:QTimeLine
其实动画的本质就是在每一定时间间隔内显示一帧图像,当这个间隔较短的时候人眼就感觉不出来了,觉得看到的是连续的影像.Qt为开发动画效果的人员提供了一个很好的时间控制类QTimeLine. QTimeLi ...
- 闰平年简介及计算过程描述 - Java代码实现
import java.util.Scanner; /** * @author Shelwin Wei * 分析过程请参照<闰平年简介及计算过程描述>,网址 http://www.cnbl ...
- 如何理解<T extends Comparable<? super T>>
在看java容器类的时候经常可以看到<T extends Comparable<? super T>>,感觉十分不解? 我们觉得<T extends Comparable ...
- 打包成war包之后如何读取配置文件
今天工作开发中遇到一个问题:在idea运行的项目读取配置文件没有问题,打包成war包之后就会报错java.io.FileNotFoundException: class path resource 原 ...
- Fabric1.4源码解析: 链码容器启动过程
想写点东西记录一下最近看的一些Fabric源码,本文使用的是fabric1.4的版本,所以对于其他版本的fabric,内容可能会有所不同. 本文想针对Fabric中链码容器的启动过程进行源码的解析.这 ...
- html、jsp页面标签的遍历
应用场景:最近的项目中二级子页面遍历生成.操作表格比较多,记录一下一直用的遍历方法. 一般此类表格都是通过ajax请求数据,然后从callbackFunction中获取数据集合,遍历生成表: eg: ...
- 在java项目启动时就执行某操作
在java启动时大概有四种,此处只介绍3种 1.在启动的方法上使用通过@PostConstruct方法实现初始化bean进行操作 2.通过bean实现InitializingBean接口 @Overr ...