Spring Boot Quartz 分布式集群任务调度实现
Spring Boot Quartz
主要内容
- Spring Scheduler 框架
- Quartz 框架,功能强大,配置灵活
- Quartz 集群
- mysql 持久化定时任务脚本(tables_mysql.sql)
介绍
在工程中时常会遇到一些需求,例如定时刷新一下配置、隔一段时间检查下网络状态并发送邮件等诸如此类的定时任务。
定时任务本质就是一个异步的线程,线程可以查询或修改并执行一系列的操作。由于本质是线程,在 Java 中可以自行编写一个线程池对定时任务进行控制,但这样效率太低了,且功能有限,属于重复造轮子。
分布式任务调度应用场景
Quartz的集群功能通过故障转移和负载平衡功能为您的调度程序带来高可用性和可扩展性。
调度程序中会有很多定时任务需要执行,一台服务器已经不能满足使用,需要解决定时任务单机单点故障问题。
用Quartz框架,在集群环境下,通过数据库锁机制来实现定时任务的执行;独立的 Quartz 节点并不与另一其的节点或是管理节点通信。
Spring Scheduler 实现定时任务
1.定义 Task 类
/**
* Spring Scheduled示例
*/
@Component
public class ScheduledTask {
private static final SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
private Integer count0 = 1;
private Integer count1 = 1;
private Integer count2 = 1;
@Scheduled(fixedRate = 5000)
public void reportCurrentTime() throws InterruptedException {
System.out.println(String.format("reportCurrentTime第%s次执行,当前时间为:%s", count0++, dateFormat.format(new Date())));
}
@Scheduled(fixedDelay = 5000)
public void reportCurrentTimeAfterSleep() throws InterruptedException {
System.out.println(String.format("reportCurrentTimeAfterSleep第%s次执行,当前时间为:%s", count1++, dateFormat.format(new Date())));
}
@Scheduled(cron = "0 0 1 * * *")
public void reportCurrentTimeCron() throws InterruptedException {
System.out.println(String.format("reportCurrentTimeCron第%s次执行,当前时间为:%s", count2++, dateFormat.format(new Date())));
}
}
2.启动定时任务
在Spring Boot的主类中加入@EnableScheduling注解,启用定时任务的配置
@RunWith(SpringRunner.class)
@SpringBootTest
@Slf4j
@EnableScheduling
public class ScheduledTaskTests {
@Test
public void test() {
log.info("启动了ScheduledTask定时作业");
while (true) {
}
}
}
quartz实现分布式定时任务
quartz 是一个开源的分布式调度库,它基于java实现。
> 它有着强大的调度功能,支持丰富多样的调度方式,比如简单调度,基于cron表达式的调度等等。
> 支持调度任务的多种持久化方式。比如支持内存存储,数据库存储,Terracotta server 存储。
> 支持分布式和集群能力。
> 采用JDBCJobStore方式存储时,针对事务的处理方式支持全局事务(和业务服务共享同一个事务)和局部事务(quarzt 单独管理自己的事务)
> 基于plugin机制以及listener机制支持灵活的扩展。
1.pom.xml配置
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
<!-- mysql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- orm -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
2.spring-quartz.properties集群配置
#============================================================================
# 配置JobStore
#============================================================================
# JobDataMaps是否都为String类型,默认false
org.quartz.jobStore.useProperties=false
# 表的前缀,默认QRTZ_
org.quartz.jobStore.tablePrefix = QRTZ_
# 是否加入集群
org.quartz.jobStore.isClustered = true
# 调度实例失效的检查时间间隔 ms
org.quartz.jobStore.clusterCheckinInterval = 5000
# 当设置为“true”时,此属性告诉Quartz 在非托管JDBC连接上调用setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED)。
org.quartz.jobStore.txIsolationLevelReadCommitted = true
# 数据保存方式为数据库持久化
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
# 数据库代理类,一般org.quartz.impl.jdbcjobstore.StdJDBCDelegate可以满足大部分数据库
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#============================================================================
# Scheduler 调度器属性配置
#============================================================================
# 调度标识名 集群中每一个实例都必须使用相同的名称
org.quartz.scheduler.instanceName = ClusterQuartz
# ID设置为自动获取 每一个必须不同
org.quartz.scheduler.instanceId= AUTO
#============================================================================
# 配置ThreadPool
#============================================================================
# 线程池的实现类(一般使用SimpleThreadPool即可满足几乎所有用户的需求)
org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool
# 指定线程数,一般设置为1-100直接的整数,根据系统资源配置
org.quartz.threadPool.threadCount = 5
# 设置线程的优先级(可以是Thread.MIN_PRIORITY(即1)和Thread.MAX_PRIORITY(这是10)之间的任何int 。默认值为Thread.NORM_PRIORITY(5)。)
org.quartz.threadPool.threadPriority = 5
3.定义两个job
- QuartzJob.java
//持久化
@PersistJobDataAfterExecution
//禁止并发执行(Quartz不要并发地执行同一个job定义(这里指一个job类的多个实例))
@DisallowConcurrentExecution
@Slf4j
public class QuartzJob extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext context) throws JobExecutionException {
String taskName = context.getJobDetail().getJobDataMap().getString("name");
log.info("---> Quartz job {}, {} <----", new Date(), taskName);
}
}
- QuartzJob2.java
@PersistJobDataAfterExecution
@DisallowConcurrentExecution
@Slf4j
public class QuartzJob2 extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext context) throws JobExecutionException {
String taskName = context.getJobDetail().getJobDataMap().getString("name");
log.info("---> Quartz job 2 {}, {} <----", new Date(), taskName);
}
}
4.初始化触发器等信息,这里通过Listener初始化
@Slf4j
public class StartApplicationListener implements ApplicationListener<ContextRefreshedEvent> {
@Autowired
SchedulerConfig schedulerConfig;
public static AtomicInteger count = new AtomicInteger(0);
private static String TRIGGER_GROUP_NAME = "test_trriger";
private static String JOB_GROUP_NAME = "test_job";
@Override
public void onApplicationEvent(ContextRefreshedEvent event) {
// 防止重复执行
if (event.getApplicationContext().getParent() == null && count.incrementAndGet() <= 1) {
initMyJob();
}
}
public void initMyJob() {
Scheduler scheduler = null;
try {
scheduler = schedulerConfig.scheduler();
TriggerKey triggerKey = TriggerKey.triggerKey("trigger1", TRIGGER_GROUP_NAME);
CronTrigger trigger = (CronTrigger) scheduler.getTrigger(triggerKey);
if (null == trigger) {
Class clazz = QuartzJob.class;
JobDetail jobDetail = JobBuilder.newJob(clazz).withIdentity("job1", JOB_GROUP_NAME).build();
CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule("0/10 * * * * ?");
trigger = TriggerBuilder.newTrigger().withIdentity("trigger1", TRIGGER_GROUP_NAME)
.withSchedule(scheduleBuilder).build();
scheduler.scheduleJob(jobDetail, trigger);
log.info("Quartz 创建了job:...:{}", jobDetail.getKey());
} else {
log.info("job已存在:{}", trigger.getKey());
}
TriggerKey triggerKey2 = TriggerKey.triggerKey("trigger2", TRIGGER_GROUP_NAME);
CronTrigger trigger2 = (CronTrigger) scheduler.getTrigger(triggerKey2);
if (null == trigger2) {
Class clazz = QuartzJob2.class;
JobDetail jobDetail2 = JobBuilder.newJob(clazz).withIdentity("job2", JOB_GROUP_NAME).build();
CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule("0/15 * * * * ?");
trigger2 = TriggerBuilder.newTrigger().withIdentity("trigger2", TRIGGER_GROUP_NAME)
.withSchedule(scheduleBuilder).build();
scheduler.scheduleJob(jobDetail2, trigger2);
log.info("Quartz 创建了job:...:{}", jobDetail2.getKey());
} else {
log.info("job已存在:{}", trigger2.getKey());
}
scheduler.start();
} catch (Exception e) {
log.info(e.getMessage());
}
}
}
5.启动定时器
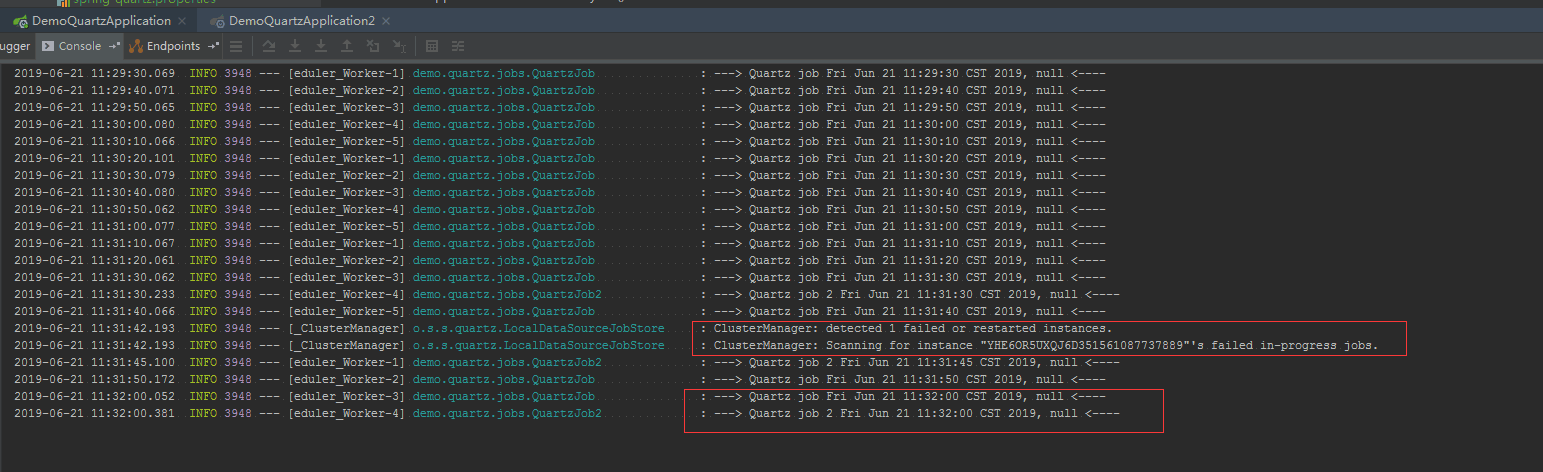
启动两个Application,分别是示例中的DemoQuartzApplication和DemoQuartzApplication2,会发现,两个Job会分别在两个应用执行。
当手动停止一个应用的时候,另一个应用会自动接管所有任务并继续执行,如果任务太多,我们可以再开一台服务即可。实现了调度任务的高可用性和可扩展性
运行效果如图:
资料
Spring Boot Quartz 分布式集群任务调度实现的更多相关文章
- Spring Boot MyBatis 数据库集群访问实现
Spring Boot MyBatis 数据库集群访问实现 本示例主要介绍了Spring Boot程序方式实现数据库集群访问,读库轮询方式实现负载均衡.阅读本示例前,建议你有AOP编程基础.mybat ...
- spring结合Quartz的集群功能实现
一:前沿 在上一篇(http://www.cnblogs.com/wuhao1991/p/4331613.html)的博客中记载了定时的功能,但是集成是没有成功的,在这篇中,我在解释下这里的”集成的含 ...
- Spring Boot集成Redis集群(Cluster模式)
目录 集成jedis 引入依赖 配置绑定 注册 获取redis客户端 使用 验证 集成spring-data-redis 引入依赖 配置绑定 注册 获取redis客户端 使用 验证 异常处理 同样的, ...
- spring和Quartz的集群(二)
一:前沿 写完了这两篇才突然想起来,忘记了最关键的东西,那就是在配置文件这里的配置,还有数据库的配置.这是郁闷啊!继续吧! 二:内容配置 我们在集成的时候需要自己配置一个quartz.properti ...
- Spring boot连接MongoDB集群
主要问题是:MongoDB集群分为复制集(replicaSet)与分片集(shardingSet),那么如何去连接这两种集群: 参考官方文档,我使用了最通用的方法:通过构造connection str ...
- Quartz Spring分布式集群搭建Demo
注:关于单节点的Quartz使用在这里不做详细介绍,直接进阶为分布式集群版的 1.准备工作: 使用环境Spring4.3.5,Quartz2.2.3,持久化框架JDBCTemplate pom文件如下 ...
- Kafka 完全分布式集群环境搭建
思路: 先在主机s1上安装配置,然后远程复制到其它两台主机s2.s3上, 并分别修改配置文件server.properties中的broker.id属性. 1. 搭建前准备 示例共三台主机,主机IP映 ...
- MinIO分布式集群的扩展方案及实现
目录 一.命令行方式扩展 1. MinIO扩展集群支持的命令语法 2. 扩容示例 二.etcd扩展方案 1. 环境变量 2. 运行多个集群 3. 示例 相关链接 MinIO 支持两种扩展方式: 通过修 ...
- #数据技术选型#即席查询Shib+Presto,集群任务调度HUE+Oozie
郑昀 创建于2014/10/30 最后更新于2014/10/31 一)选型:Shib+Presto 应用场景:即席查询(Ad-hoc Query) 1.1.即席查询的目标 使用者是产品/运营/销售 ...
随机推荐
- SpringBoot使用拦截器、过滤器、监听器
目录 ## 过滤器 PS: 原文链接https://www.cnblogs.com/haixiang/p/12000685.html,转载请注明出处 过滤器简介 过滤器的使用 拦截器 拦截器介绍 使用 ...
- Linux-Ubuntu学习笔记
因学习Python需求,特开此贴用于记录Linux-Ubuntu操作系统的学习笔记. Linux命令-基础版 Linux命令-高级版 此贴终结了,主要用于开发过程中忘记命令时使用.
- Create an Embedded Framework in Xcode with Swift
转自:http://zappdesigntemplates.com/create-an-embedded-framework-in-xcode-with-swift/ Post Series: Cre ...
- 声明式服务调用Feign
什么是 Feign Feign 是种声明式.模板化的 HTTP 客户端(仅在 consumer 中使用). 什么是声明式,有什么作用,解决什么问题? 声明式调用就像调用本地方法一样调用远程方法;无 ...
- 数据库Oracle组函数和分组函数
组函数: 组函数操作行集,给出每组的结果.组函数不象单行函数,组函数对行的集合进行操作,对每组给出一个结果.这些集合可能是整个表或者是表分成的组. 组函数与单行函数区别: 单行函数对查询到每个结果集做 ...
- 大数据之Linux用户权限设置
用户 是Linux系统工作中重要的一环, 用户管理包括 用户 与 组 管理,在Linux系统中, 不论是由本级或是远程登录系统, 每个系统都必须拥有一个账号, 并且对于不同的系统资源拥有不同的使用权限 ...
- cf1119d Frets On Fire 前缀和+二分
题目:http://codeforces.com/problemset/problem/1119/D 题意:给一个数n,给出n个数组的第一个数(a[0]=m,a[1]=m+1,a[2]=m+2,... ...
- Grafana基础
一.Grafana基础 Grafana是一个开源的指标量监测和可视化工具.官方网站为:https://grafana.com/, 常用于展示基础设施的时序数据和应用程序运行分析.Grafana的das ...
- 在VS2017中连接到SQLite数据源(dbfist)
在VS2017中配置.连接到SQLite数据源(dbfist) 需要安装的VS插件 SQLite/SQL Server Compact ToolBox 这个插件安装后,在选择数据源时已经可以选择SQL ...
- 【Java Web开发学习】Spring加载外部properties配置文件
[Java Web开发学习]Spring加载外部properties配置文件 转载:https://www.cnblogs.com/yangchongxing/p/9136505.html 1.声明属 ...