阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建
准备:
两台配置CentOS 7.3的阿里云ECS服务器;
Hadoop:hadoop-2.7.3.tar.gz;
Java: jdk-8u77-linux-x64.tar.gz;
hostname及IP的配置:
更改主机名:
由于系统为CentOS 7,可以直接使用‘hostnamectl set-hostname 主机名’来修改,修改完毕后重新shell登录或者重启服务器即可。
hostnamectl set-hostname master
exit
ssh root@master
1 hostnamectl set-hostname slave1
2 exit
3 ssh root@slave1
设置本地域名:
设置本地域名这一步非常关键,ip的本地域名信息配置不好,即有可能造成Hadoop启动出现问题,又有可能造成在使用Hadoop的MapReduce进行计算时报错。在ECS上搭建Hadoop集群环境需参考以下两篇文章:
阿里云ECS搭建Hadoop集群环境——启动时报错“java.net.BindException: Cannot assign requested address”问题的解决
阿里云ECS搭建Hadoop集群环境——计算时出现“java.lang.IllegalArgumentException: java.net.UnknownHostException”错误的解决
总结一下那就是,在“/etc/hosts”文件中进行域名配置时要遵从2个原则:
- 新加域名在前面: 将新添加的Master、Slave服务器ip域名(例如“test7972”),放置在ECS服务器原有本地域名(例如“iZuf67wb***************”)的前面。但是注意ECS服务器原有本地 域名(例如“iZuf67wb***************”)不能被删除,因为操作系统别的地方还会使用到。
- IP本机内网,其它外网: 在本机上的操作,都要设置成内网ip;其它机器上的操作,要设置成外网ip。
master

slave1

此处摘自 https://blog.csdn.net/dongdong9223/article/details/81275360
配置好后需要在各个节点上执行如下命令,测试是否相互 ping 得通,如果 ping 不通,后面就无法顺利配置成功:
1 ping master -c 3
2 ping slave1 -c 3
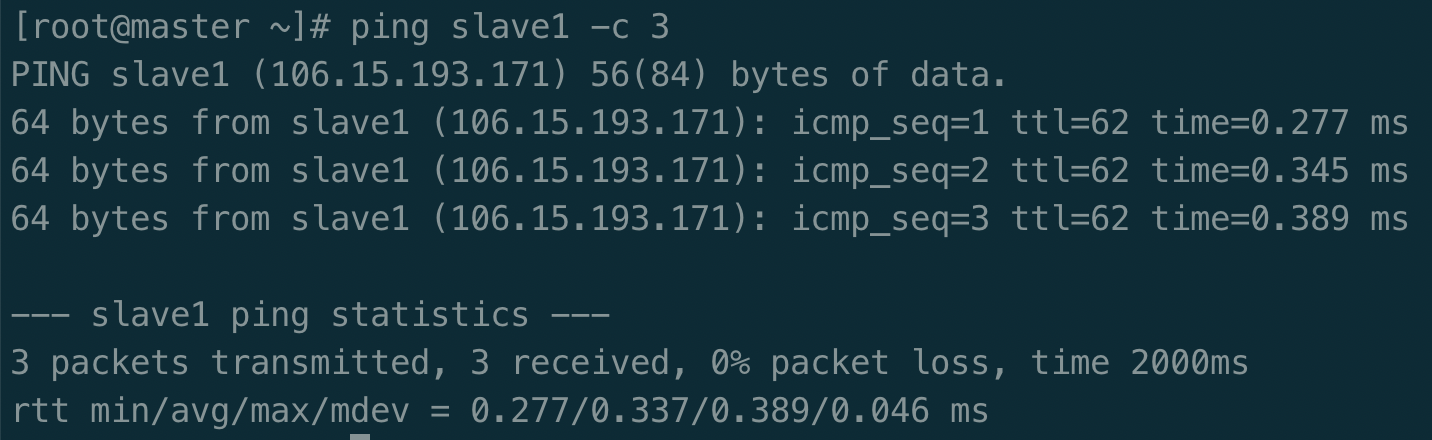
例如我在 master 节点上 ping slave1 ,ping 通的话会显示 time,显示的结果如下图所示:
各节点角色分配
master: NameNode ResourceManager
slave1: DataNode NodeManager
免密码登录配置
分别在 master 和 slave1 上做如下操作
1 ssh-keygen -t rsa
2 ssh-copy-id master
3 ssh-copy-id slave1
验证
ssh master date;ssh slave1 date

配置JDK
解压JDK安装包到/usr/local/下
tar -zxvf jdk-8u77-linux-x64.tar.gz -C /usr/local/
将解压目录改为 jdk1.8
mv jdk1.8.0_77/ jdk1.8/
设置JAVA_HOME到系统环境变量
vim /etc/profile
在最后加入以下两行代码
export JAVA_HOME=/usr/local/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
重新加载环境
source /etc/profile
这样 master 的jdk就配置好了,可以用命令 java -version 测试下。
java -version

下面只需将 master 上配置好的文件分发到 slave1 上即可。
将/usr/local/jdk1.8分发到 slave1 的/usr/local/下(建议压缩后再分发)
scp -r /usr/local/jdk1.8/ slave1:/usr/local/
将/etc/profile分发到 slave1 的/etc/下
scp /etc/profile slave1:/etc/
然后重新加载 slave1 环境便完成了 slave1 的jdk配置
source /etc/profile
hadoop集群配置
cd ~
tar -zxvf hadoop-2.7..tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
mv ./hadoop-2.7./ ./hadoop # 将文件夹名改为hadoop
输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
1 cd /usr/local/hadoop
2 ./bin/hadoop version
添加 HADOOP_HOME 到系统环境变量
vim /etc/profile
在后面添加如下两行
1 export HADOOP_HOME=/usr/local/hadoop
2 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
重新加载环境,并输出变量 HADOOP_HOME 验证

进入/user/local/hadoop/etc/hadoop/可以看到如下配置文件
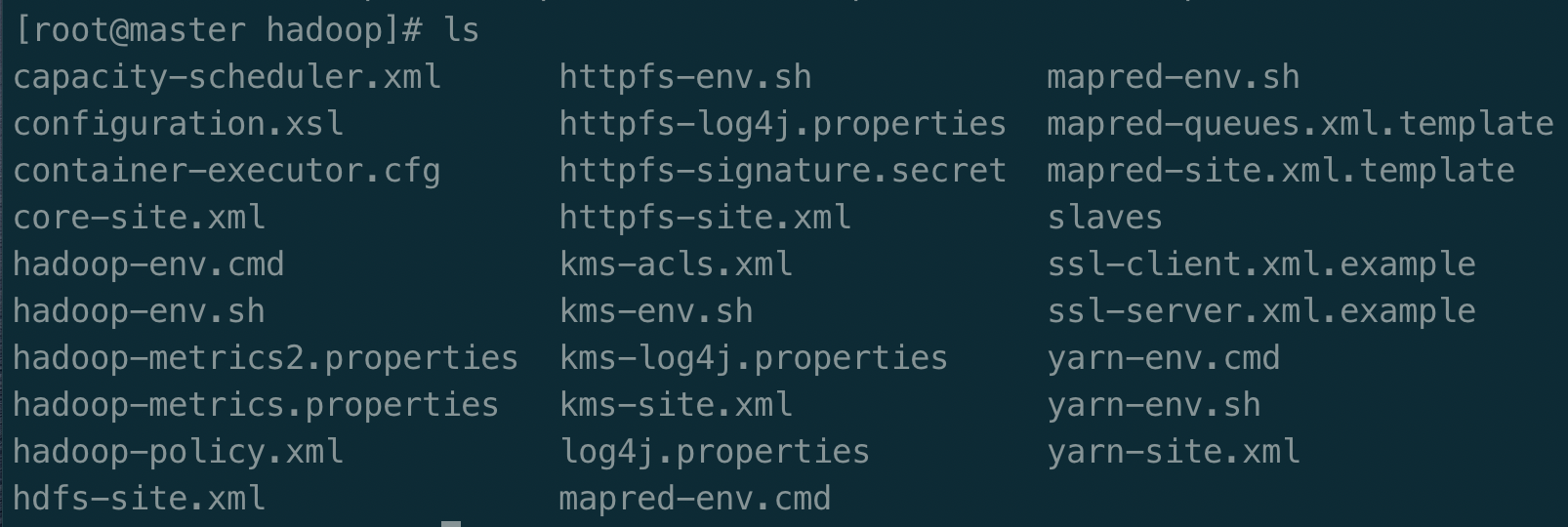
集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的6个配置文件,更多设置项可点击查看官方说明,这里仅设置了我完成课堂作业所必须的设置项:hadoop-env.sh, slaves, core-default.xml, hdfs-default.xml, mapred-default.xml, yarn-default.xml 。
1.首先来配置 hadoop-env.sh ,只需要设置一下JAVA_HOME即可

注:之前在配置jdk中配置的是基于系统的JAVA_HOME变量,这里需要配置基于Hadoop集群的JAVA_HOME变量。
hadoop-env.sh 是Hadoop的环境变量配置脚本。
所以应做以下修改 vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8

2.配置 slave , 指定 slave 节点
sudo vi slaves
删去原有的 localhost , 添加将作为 slave 节点的 slave1

3.配置 core-site.xml
1 <configuration>
2
3 <property>
4 <name>fs.defaultFS</name>
5 <value>hdfs://master:9000</value>
6 <description>The name of the default file system.</description>
7 </property>
8 # 设置访问hdfs的默认名,9000是默认端口
9
10 <property>
11 <name>hadoop.tmp.dir</name>
12 <value>/usr/local/hadoop/tmp</value>
13 <description>Abase for other temporary directories.</description>
14 </property>
15 # 在hdfs格式化的时候会自动创建相应的目录 'tmp/'
16
17 <property>
18 <name>fs.trash.interval</name>
19 <value>4320</value>
20 <description>Number of minutes after which the checkpoint gets deleted.</description>
21 </property>
22 # 设置回收站里的文件保留时间(单位:秒)
23
24 </configuration>
4.配置 hdfs-site.xml
1 <configuration>
2
3 <property>
4 <name>dfs.namenode.name.dir</name>
5 <value>/usr/local/hadoop/tmp/dfs/name</value>
6 </property>
7
8 <property>
9 <name>dfs.datanode.data.dir</name>
10 <value>/usr/local/hadoop/tmp/dfs/data</value>
11 </property>
12
13 <property>
14 <name>dfs.replication</name>
15 <value>1</value>
16 </property>
17 # 副本,因为有一个 slave 节点这里设置为1(一般伪分布模式设1个,三个或三个以上节点设3个)
18
19 <property>
20 <name>dfs.permissions.enabled</name>
21 <value>false</value>
22 <description>If "true", enable permission checking in HDFS. If "false", permission checking is turned off, but all other behavior is unchanged. Switching from one parameter value to the other does not change the mode, owner or group of files or directories.</description>
23 </property>
24
25 </configuration>
5.配置 mapred-site.xml (这个文件没有直接提供,而是提供了模版文件,需将模版文件转换为配置文件)
1 sudo mv mapred-site.xml.template mapred-site.xml
2 sudo vi mapred-site.xml
1 <configuration>
2
3 <property>
4 <name>mapreduce.framework.name</name>
5 <value>yarn</value>
6 <description>The runtime framework for executing MapReduce jobs.Can be one of local, classic or yarn.</description>
7 </property>
8 <property>
9 <name>mapreduce.jobtracker.http.address</name>
10 <value>master:50030</value>
11 </property>
12 <property>
13 <name>mapreduce.jobhisotry.address</name>
14 <value>master:10020</value>
15 </property>
16 <property>
17 <name>mapreduce.jobhistory.webapp.address</name>
18 <value>master:19888</value>
19 </property>
20 <property>
21 <name>mapreduce.jobhistory.done-dir</name>
22 <value>/jobhistory/done</value>
23 </property>
24 <property>
25 <name>mapreduce.jobhistory.intermediate-done-dir</name>
26 <value>/jobhisotry/done_intermediate</value>
27 </property>
28 <property>
29 <name>mapreduce.job.ubertask.enable</name>
30 <value>true</value>
31 <description>Whether to enable the small-jobs "ubertask" optimization,which runs "sufficiently small" jobs sequentially within a single JVM."Small" is defined by the following maxmaps, maxreduces, and maxbytes settings. Note that configurations for application masters also affect the "Small" definition - yarn.app.mapreduce.am.resource.mb must be larger than both mapreduce.map.memory.mb and mapreduce.reduce.memory.mb, and yarn.app.mapreduce.am.resource.cpu-vcores must be larger than both mapreduce.map.cpu.vcores and mapreduce.reduce.cpu.vcores to enable ubertask. Users may override this value.</description>
32 </property>
33
34 </configuration>
6.配置 yarn-site.xml
1 <configuration>
2
3 <property>
4 <name>yarn.resourcemanager.hostname</name>
5 <value>master</value>
6 </property>
7 <property>
8 <name>yarn.nodemanager.aux-services</name>
9 <value>mapreduce_shuffle</value>
10 <description>A comma separated list of services where service name should only contain a-zA-Z0-9_ and can not start with numbers</description>
11 </property>
12 <property>
13 <name>yarn.resourcemanager.address</name>
14 <value>master:18040</value>
15 </property>
16 <property>
17 <name>yarn.resourcemanager.scheduler.address</name>
18 <value>master:18030</value>
19 </property>
20 <property>
21 <name>yarn.resourcemanager.resource-tracker.address</name>
22 <value>master:18025</value>
23 </property>
24 <property>
25 <name>yarn.resourcemanager.admin.address</name>
26 <value>master:18141</value>
27 </property>
28 <property>
29 <name>yarn.resourcemanager.webapp.address</name>
30 <value>master:18088</value>
31 </property>
32 <property>
33 <name>yarn.log-aggregation-enable</name>
34 <value>true</value>
35 </property>
36 <property>
37 <name>yarn.log-aggregation.retain-seconds</name>
38 <value>86400</value>
39 </property>
40 <property>
41 <name>yarn.log-aggregation.retain-check-interval-seconds</name>
42 <value>86400</value>
43 </property>
44 <property>
45 <name>yarn.nodemanager.remote-app-log-dir</name>
46 <value>/tmp/logs</value>
47 </property>
48 <property>
49 <name>yarn.nodemanager.remote-app-log-dir-suffix</name>
50 <value>logs</value>
51 </property>
52
53 </configuration>
到这里 master 就已经配置好了,下面将该服务器的配置分发到 slave1 上去(建议压缩后再分发),在此使用压缩后分发的方法
在 master 节点上执行
1 cd /usr/local
2 tar -zcvf ~/hadoop.master.tar.gz ./hadoop
3 cd ~
4 scp ./hadoop.master.tar.gz slave1:/root/
5 scp /etc/profile slave1:/etc/
在 slave1 节点上执行
tar -zxvf ~/hadoop.master.tar.gz -C /usr/local
在 slave1 上重新加载环境并检查验证
source /etc/profile
echo $HADOOP_HOME
HDFS NameNode 格式化(只要在 master 上执行即可)
$HADOOP_HOME/bin/hdfs namenode -format
看到下面的输出,表明hdfs格式化成功
INFO common.Storage: Storage directory /usr/local/hadoop/tmp/dfs/name has been successfully formatted.
启动前检查防火墙状态
systemctl status firewalld

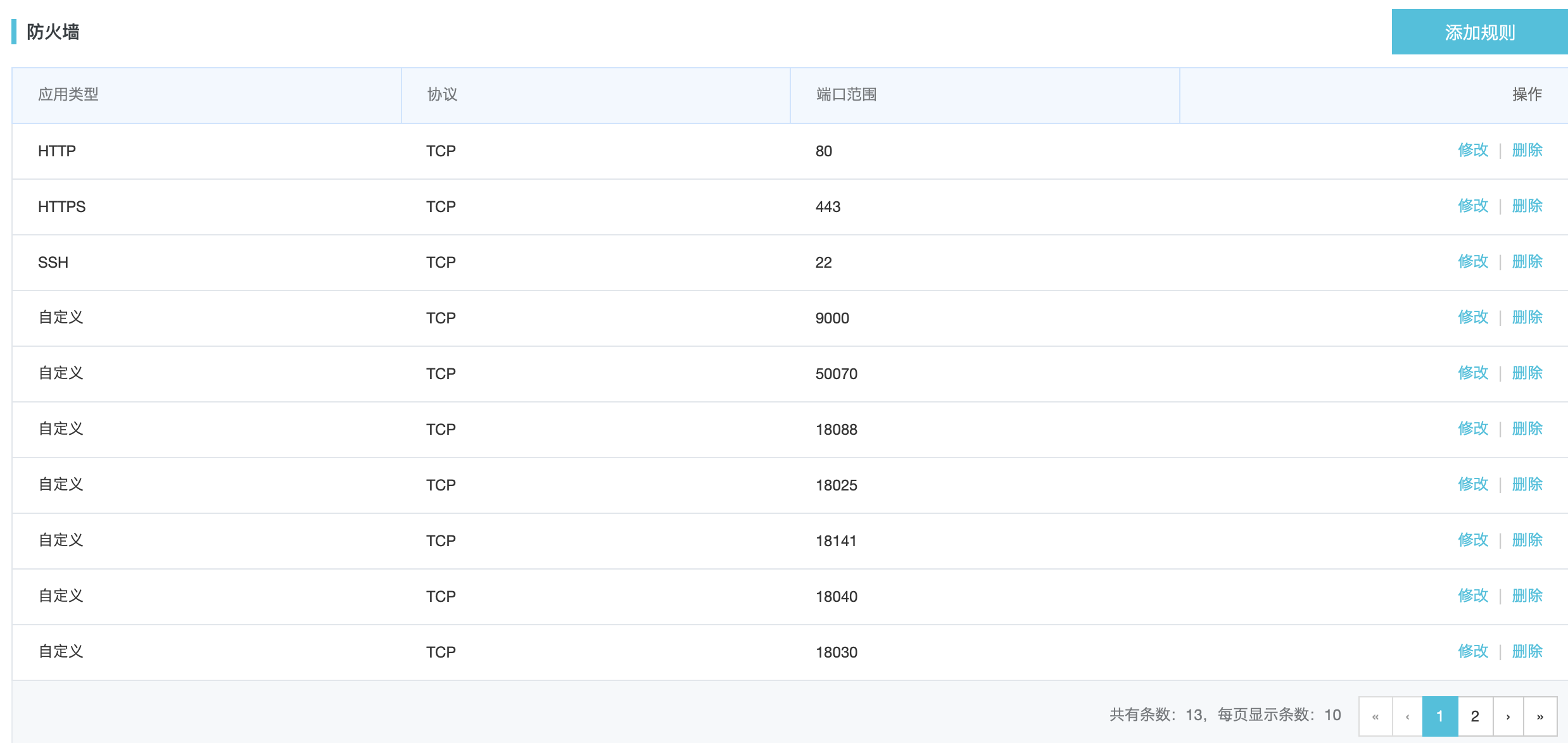
我这里是已经关闭的,若未关闭,可以参考下图(来自http://dblab.xmu.edu.cn/blog/install-hadoop-cluster/)

阿里云服务器还需要在服务器安全组里配置防火墙,需将配置文件里的相关端口全部添加,否则会出现 web 页面打不开,以及 DataNode 启动但 Live datenode 为 0 等问题
启动 Hadoop 集群
$HADOOP_HOME/sbin/start-all.sh

- 第一次启动 hadoop 时会出现 ssh 提示,提示是否要连入 0.0.0.0 节点,输入 yes 即可
- 若出现 hadoop 启动时 datanode 没有启动,可以参考阿里云ECS搭建Hadoop集群环境——“启动Hadoop时,datanode没有被启动”问题的解决来解决
启动 job history server
在 master 上执行
$HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver

成功后在两个节点上验证
在 master 上 执行
jps
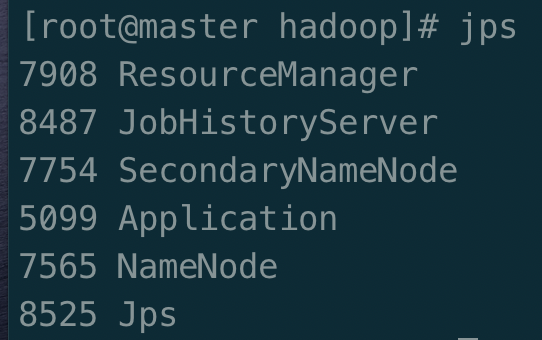
可以看到 ResourceManager、SecondaryNameNode、NameNode、JobHistoryServer 四个进程全部启动
在 slave1 上执行
jps

可以看到 NodeManager、DataNode 两个进程全部启动
缺少任一进程都表示出错。另外还需要在 Master 节点上通过命令 hdfs dfsadmin -report 查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。例如我这边一共有 1 个 Datanodes:

全部配置完成之后查看 web 页面
hdfs: http://master:50070/

hdfs Datanode 节点信息
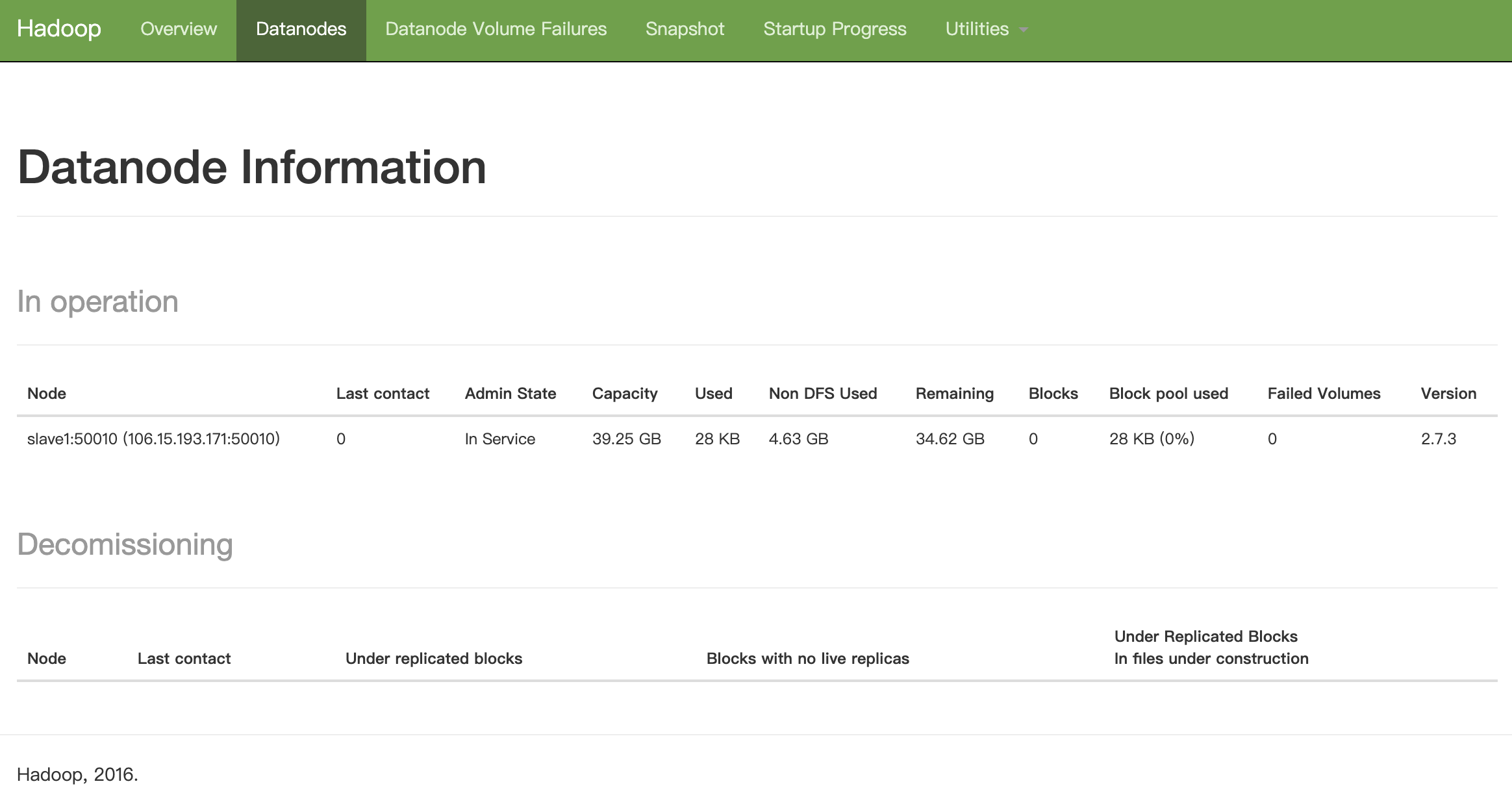
hdfs 的情况
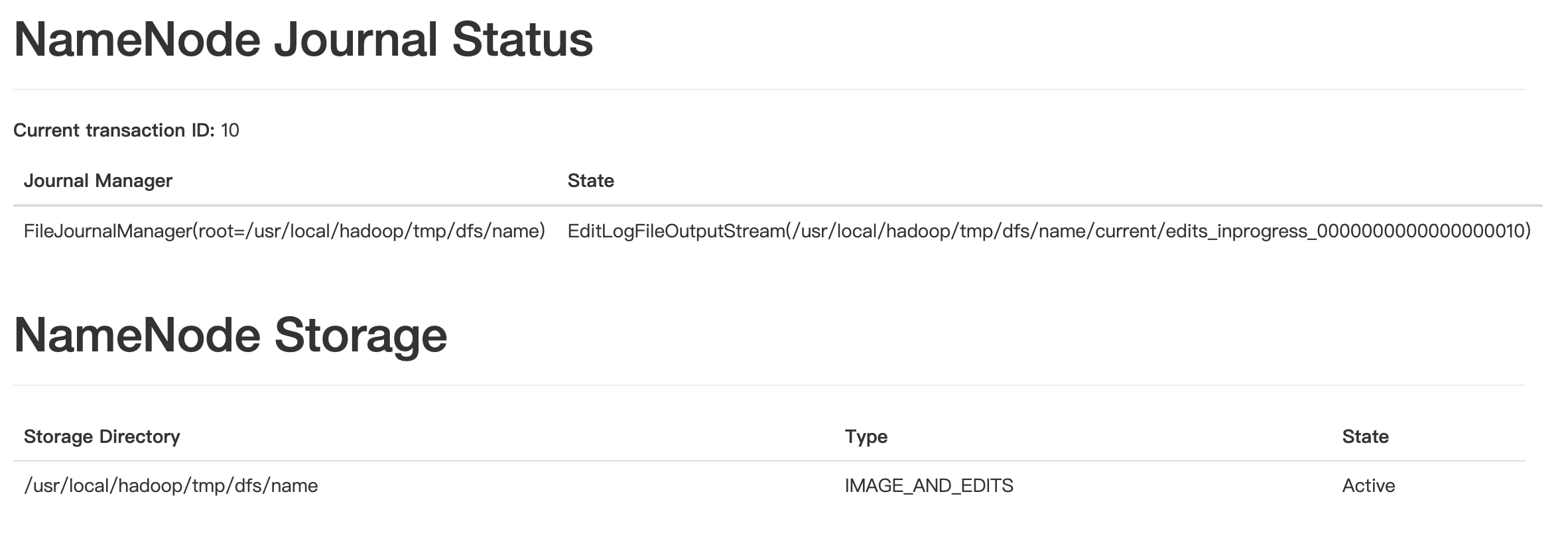
hdfs 的文件情况

yarn:http://master:18088/
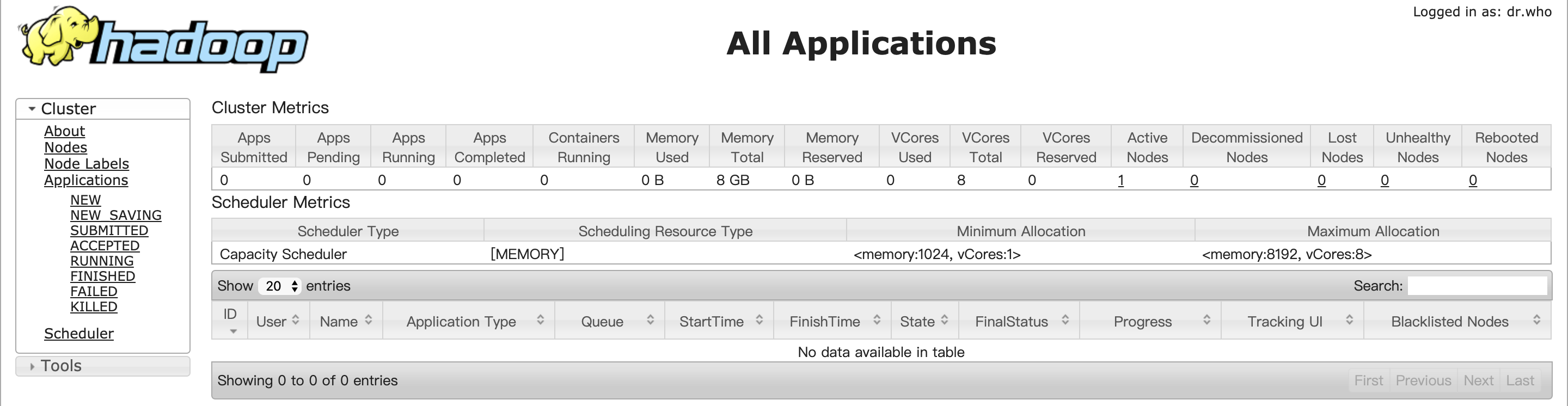
阿里云ECS服务器部署HADOOP集群系列:
- 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper)
- 阿里云ECS服务器部署HADOOP集群(三):ZooKeeper 完全分布式集群搭建
- 阿里云ECS服务器部署HADOOP集群(四):Hive本地模式的安装
- 阿里云ECS服务器部署HADOOP集群(五):Pig 安装
- 阿里云ECS服务器部署HADOOP集群(六):Flume 安装
- 阿里云ECS服务器部署HADOOP集群(七):Sqoop 安装
阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的更多相关文章
- 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper)
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- 阿里云ECS服务器部署HADOOP集群(三):ZooKeeper 完全分布式集群搭建
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- 阿里云ECS服务器部署HADOOP集群(六):Flume 安装
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建. 1 环境介绍 一台阿里云ECS服务器:master 操作系统:CentOS 7.3 Hadoop ...
- 阿里云ECS服务器部署HADOOP集群(七):Sqoop 安装
本篇将在 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper) 阿 ...
- 阿里云ECS服务器部署HADOOP集群(五):Pig 安装
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建. 1 环境介绍 一台阿里云ECS服务器:master 操作系统:CentOS 7.3 Hadoop ...
- 阿里云ECS服务器部署HADOOP集群(四):Hive本地模式的安装
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建. 本地模式需要采用MySQL数据库存储数据. 1 环境介绍 一台阿里云ECS服务器:master ...
- thinkphp项目阿里云ECS服务器部署
[日记]thinkphp项目阿里云ECS服务器部署 项目本地开发告一段落.准备上传到服务器上测试 技术组成 thinkphp+mysql+阿里ECS 代码管理方式git 一.阿里ECS服务器配置 ...
- 阿里云ECS服务器部署Node.js项目全过程详解
本文详细介绍如何部署NodeJS项目到阿里云ECS上,以及本人在部署过程中所遇到的问题.坑点和解决办法,可以说是全网最全最详细的教程了.同时讲解了如何申请阿里云免费SSL证书,以及一台ECS服务器配置 ...
- 【日记】thinkphp项目阿里云ECS服务器部署
项目本地开发告一段落.准备上传到服务器上测试 技术组成 thinkphp+mysql+阿里ECS 代码管理方式git 一.阿里ECS服务器配置 1.因为线上已经有几个站点了.所以要配置ngnix多站 ...
随机推荐
- python 可变数量参数 ( 多参数返回求 参数个数,最大值,最大值)
一. 自定义一串数字求 参数个数,最大值,最大值()---------方法一: def max(*a): m=a[0] p=a[0] n=0 for x in a: if x>m: m=x n+ ...
- Django之CBV视图源码分析(工作原理)
1.首先我们先在urls.py定义CBV的路由匹配. FBV的路由匹配: 2.然后,在views.py创建一名为MyReg的类: 注意:该类必须继续View类,且方法名必须与请求方式相同(后面会详解) ...
- 【阿里云IoT+YF3300】7.物联网设备表达式运算
很多时候从设备采集的数据并不能直接使用,还需要进行处理一下.如果采用脚本处理,有点太复杂了,而采用表达式运算,则很方便地解决了此类问题. 一. 设备连接 运行环境搭建:Win7系统请下载相关的设备驱 ...
- win32API多线程编程
win32线程API 在Windows平台下可以通过Windows的线程库来实现多线程编程. 对于多线程程序可以使用Visual Studio调试工具进行调试,也可以使用多核芯片厂家的线程分析调试工具 ...
- Leetcode(3)无重复字符的最长子串
Leetcode(3)无重复字符的最长子串 [题目表述]: 给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度. 第一种方法:暴力 执行用时:996 ms: 内存消耗:12.9MB 效果: ...
- OptimalSolution(3)--链表问题(1)简单
单链表Node节点类 public class Node { public int val; public Node next; public Node(int val) { this.val = v ...
- Unity资源加载路径及加载方式小结
Unity3D中的资源路径路径属性 路径说明Application.dataPath 此属性用于返回程序的数据文件所在文件夹的路径.例如在Editor中就是Assets了.Application.st ...
- 汇编语言——物理地址=段地址x16+偏移地址,检测点2.2
一.为什么 物理地址=段地址x16+偏移地址? 刚开始学时,我都笨到不明白为什么是2的N次方,咱把物理地址就当数字,计算机中数字是由很多位0或1自由组合的, 而每一位上要么是0要么是1,只有这两种情况 ...
- 学习笔记59_python字符串处理
python中,字符串可以使用 '或"括起来 1. 要想写成 "hellow "aaaa" ",在python中,可以"hellow ' ...
- [考试反思]0921csp-s模拟测试49:困顿
太弱.还是太弱. 拉不开分差,离第一机房分数线估计还是300多分. 但是,还是要骂:XX出题人. 部分分非常少且没有意义,T1基本只有0/纯暴力20/100三个档, T2正解是n2但是n3一分不给,还 ...