Intel X86 32位CPU内存管理----《Linux内核源码情景分析》笔记(一)
Intel X86 32位CPU内存管理
在X86系列中,8086和8088是16为处理器,而从80386开始为32为处理器,80286则是该系列从8088到80386,也就是16位处理器到32位处理器的一个过渡。
段式内存管理
Intel决定在16位CPU,也就是8086CPU,中使用1M的内存空间,地址总线的宽度也就为20位,但是CPU的ALU(算术逻辑单元)的宽度只有16位,因此采用了“分段”的设计方法。
Intel在8086CPU内置了四个段寄存器:CS,DS,SS和ES,分别用于可执行代码既指令、数据、堆栈和其它。每个段寄存器是16位的,对应于地址总线的高16位。在汇编语言中,访问一个内存的位置使用ES:AX这样的语句,实际访问的位置为 ES*2^4+AX处。这样完成了16位内部地址到20位实际地址的转换。
这种方式没有地址空间的把保护机制,用来改变段寄存器内容的指令不是什么”特权指令“,而就是MOV,因此进程可以随意修改段寄存器,从而访问整个内存空间的内容。这种缺乏对内存空间保护的内存寻址模式被称为 实模式,与保护模式对应。
针对8086的缺陷,Intel从80286开始实现保护模式。同时,不久之后32位的80386CPU也研发成功了。从80386之后Intel的CPU历经80486、Pentium、Pentium Ⅱ等型号,虽然速度提升,但是结构并无重大改变,因此统称i386CPU。下面介绍i386系列的保护模式。
Intel选择了再段寄存器的基础上构筑保护模式的构思,并且保留段寄存器为16位(这样才可以利用原来的四个寄存器),但是又增添了2个新的段寄存器FS和GS。基本思路为:在保护模式下改变段寄存器的功能,使其从一个单纯的基地址(变相的基地址)变成指向这样一个数据结构的指针。这样,当一条访问内存指令发出一个内存地址时,CPU就可以这样归纳出实际应放上总线的地址:
根据指令的性质来确定应该使用哪一个段寄存器,例如转移指令中的地址在代码段(CS),而取数指令中的代码在数据段(DS),这一点和实模式相同。
根据段寄存器的内容,找出相应的”地址段描述结构“。
从地址段描述结构中的到基地址。
将指令中发出的地址作为位移,与段描述结构中规定的长度相比,查看是否越界。(保护模式)
根据指令的性质和段描述结构中的访问权限来确定是否越权。
将指令中的地址作为位移,与基地相加得出实际的“物理地址”。
在80386CPU中增加了2个寄存器,全局性的段描述表寄存器GDTR,和局部性的段描述表寄存器LDTR。访问这两个寄存器的指令被设置为专有指令,起到了保护作用。段寄存器的高13为用作访问段描述表中具体描述结构的下标。
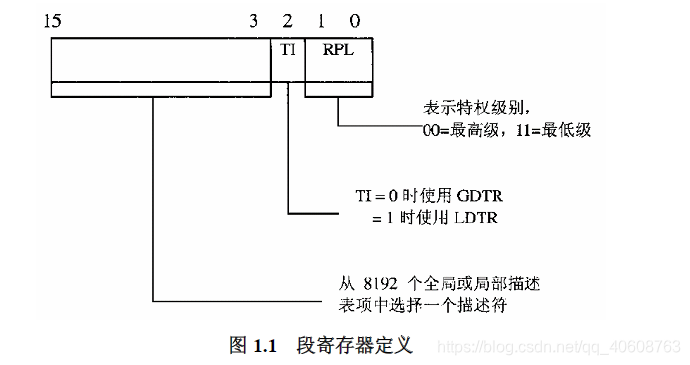
每个段描述表项的大小是8字节,每个描述表项含有段的基地址和段的大小,在加上其他的一些信息。

B31--B24表示基地址(base)的高8位,B23-B0表示基地址的地24位。因为在一开始的实际中,Intel是采用了24位地址线,后来又改为32位地址。L19--L16 和 L15--L0表示段长,DPL是个2位的位段,代表访问本段需要的特权。
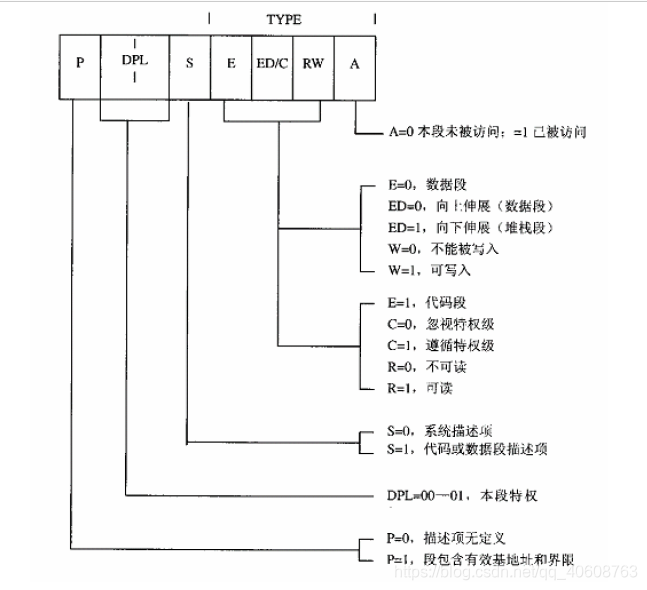
在80386的段内存管理的基础上,如果把每个段寄存器都指向同一个描述项,而将该描述项的基地址设为0,并将段长度设为最大,这样便形成了从0开始覆盖整个32位地址空间的一个整段,此时物理地址与逻辑地址相同。因为32位CPU的寄存器也为32位,可以对整个32位内存寻址。
i386的页式内存管理机制
因为在之前的设计中保护模式依赖于段式管理,所以Intel决定在段式内存的机制之上实现页式内存管理。80386把线性地址空间划分为4K字节的页面,每个页面可以被映射为物理存储空间中任意一块4K字节大小的空间(边界必须与4K字节对齐)。
由于页式管理的引入,对32位线性地址有了新的解释(以前就是物理地址):

可以看出,在页面目录中共有$2^{10}=1024$个目录项,每个目录项指向一个页面表,而每个页面表又共有1024个页面描述项。类似于GDTR和LDTR,又增加了一个新的寄存器CR3作为指向当前页面目录的指针,这样,从线性地址到物理地址的映射为:
- 从CR3取得页面目录的基地址。
- 以线性地址中的dir位段(22-31)为下标,在目录中取得相应页面表的基地址。
- 以线性地址中的page(12-21)位段为下标,在所得到的页面表中取得相应的页面描述项。
- 将页面描述项中的基地址与线性地址中的offset段相加,获得物理地址。
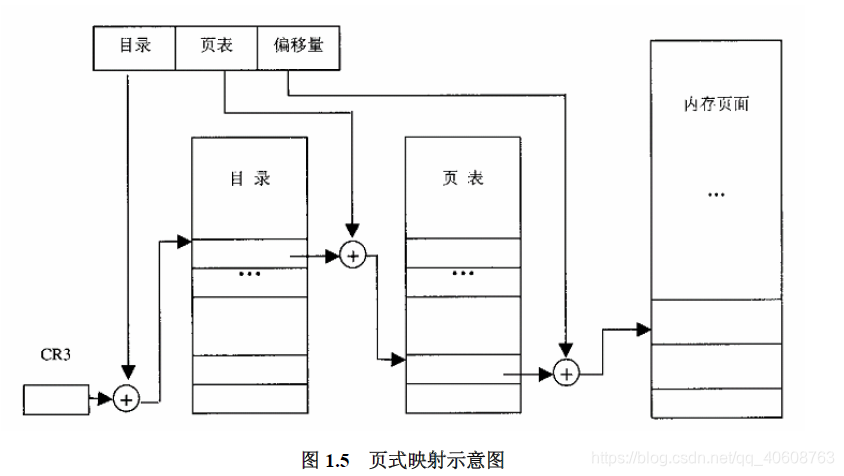
采用目录加页表的双层机制是处于节省空间的考虑。这样,我们只需留出必要的1024个目录项的空间,而没有被下使用的页表可以不创建。而如果采用单层记录,则需要留出必要的1024*1024个页表的空间,因为目录和页表都是基于偏移量来寻址的,必须留出整个数组的空间。
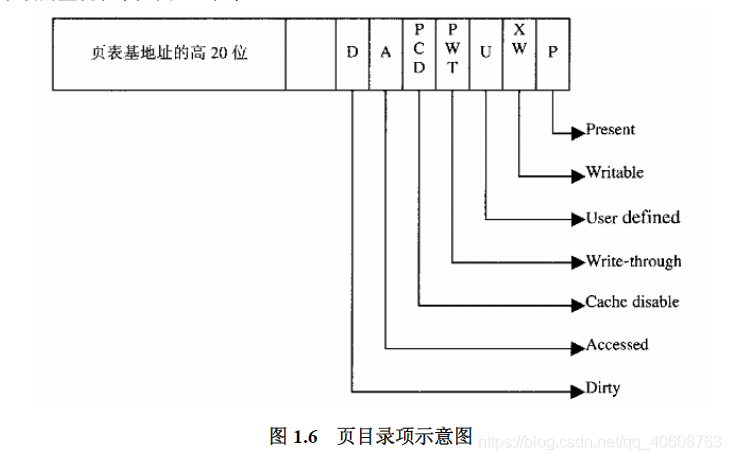
如前所述,目录项中含有一个指向页表的指针,而页表项中含有指向一个页面其实地址的指针。由于页面表和页面的起始位置总是在4K的边界上,所以低12位一定为0。这样,目录项和页表项中只要用20为用于指针就可以了。
Intel X86 32位CPU内存管理----《Linux内核源码情景分析》笔记(一)的更多相关文章
- Linux 内核源码情景分析 chap 2 存储管理 (四)
物理页面的使用和周转 1. 几个术语 1.1 虚存页面 指虚拟地址空间中一个固定大小, 边界与页面大小 4KB 对齐的区间及其内容 1.2 物理页面 与虚存页面相对的, 须要映射到某种物理存储介质上面 ...
- Linux内核源码情景分析-wait()、schedule()
父进程执行wait4,并调用schedule切换到子进程: wait4(child, NULL, 0, NULL); 像其它系统调用一样.wait4()在内核中的入口是sys_wait4().代码例如 ...
- Linux内核源码情景分析-系统调用
一.系统调用初始化 void __init trap_init(void) { ...... set_system_gate(SYSCALL_VECTOR,&system_call);//0x ...
- Linux内核源码分析方法
一.内核源码之我见 Linux内核代码的庞大令不少人“望而生畏”,也正因为如此,使得人们对Linux的了解仅处于泛泛的层次.如果想透析Linux,深入操作系统的本质,阅读内核源码是最有效的途径.我们都 ...
- 【转】Linux内核源码分析方法
一.内核源码之我见 Linux内核代码的庞大令不少人“望而生畏”,也正因为如此,使得人们对Linux的了解仅处于泛泛的层次.如果想透析Linux,深入操作系统的本质,阅读内核源码是最有效的途径.我们都 ...
- Linux内核源码分析方法_转
Linux内核源码分析方法 转自:http://www.cnblogs.com/fanzhidongyzby/archive/2013/03/20/2970624.html 一.内核源码之我见 Lin ...
- Linux内核源码分析 day01——内存寻址
前言 Linux内核源码分析 Antz系统编写已经开始了内核部分了,在编写时同时也参考学习一点Linux内核知识. 自制Antz操作系统 一个自制的操作系统,Antz .半图形化半命令式系统,同时嵌入 ...
- Linux内核源码特殊用法
崇拜并且转载的: http://ilinuxkernel.com/files/5/Linux_Kernel_Source_Code.htm Linux内核源码特殊用法 1 前言 Linux内核源码主要 ...
- linux内核源码注解
轻松学习Linux操作系统内核源码的方法 针对好多Linux 爱好者对内核很有兴趣却无从下口,本文旨在介绍一种解读linux内核源码的入门方法,而不是解说linux复杂的内核机制:一.核心源程序的文件 ...
随机推荐
- react学习(二)--元素渲染
元素用来描述你在屏幕上看到的内容: const element = <h1>Hello, world</h1>; 与浏览器的 DOM 元素不同,React 当中的元素事实上是普 ...
- HTML/CSS:block,inline和inline-block概念和区别
总体概念 block和inline这两个概念是简略的说法,完整确切的说应该是 block-level elements (块级元素) 和 inline elements (内联元素).block元素通 ...
- iview自定义实现多级表头
最近更新: 2018-07-19 注意:最新版iview已经提供多级表头功能 参考 原理:利用多个Table组件通过显示和隐藏thead和tbody来拼接表格(较粗暴) html <div st ...
- Mina实现Socket通信完整过程
目录 服务端 客户端 通信 自定义工厂编解码 解码器 编码器 总结 # 加入战队 微信公众号 title: Mina服务端客户端通信 date: 2018-09-30 09:00:30 tags: - ...
- 《Java 8 in Action》Chapter 2:通过行为参数化传递代码
你将了解行为参数化,这是Java 8非常依赖的一种软件开发模式,也是引入 Lambda表达式的主要原因.行为参数化就是可以帮助你处理频繁变更的需求的一种软件开发模式.一言以蔽之,它意味 着拿出一个代码 ...
- 高并发下,调整IIS相关的设置,以提高服务器并发量
1.修改 IIS 队列长度 参考资料:https://docs.microsoft.com/zh-cn/previous-versions/office/communications-server/d ...
- Spring MVC内置支持的4种内容协商方式【享学Spring MVC】
每篇一句 十个光头九个富,最后一个会砍树 前言 不知你在使用Spring Boot时是否对这样一个现象"诧异"过:同一个接口(同一个URL)在接口报错情况下,若你用rest访问,它 ...
- CentOS -- RocketMQ HA & Monitoring
RocketMQ Architecture NameServer Cluster Name Servers provide lightweight service discovery and rout ...
- java日志框架笔记-log4j-springboot整合
# 日志框架slf4j log4j logback之间的关系 简答的讲就是slf4j是一系列的日志接口,而log4j logback是具体实现了的日志框架. ```java SLF4J获得logger ...
- Leetcode之回溯法专题-79. 单词搜索(Word Search)
Leetcode之回溯法专题-79. 单词搜索(Word Search) 给定一个二维网格和一个单词,找出该单词是否存在于网格中. 单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元 ...