趣谈Linux操作系统学习笔记:第二十六讲
一、内核页表
和用户态页表不同,在系统初始化的时候,我们就要创建内核页表了
我们从内核页表的根swapper_pg_dir开始找线索,在linux-5.1.3/arch/x86/include/asm/pgtable_64.h中就能找到它的定义
extern pud_t level3_kernel_pgt[512];
extern pud_t level3_ident_pgt[512];
extern pmd_t level2_kernel_pgt[512];
extern pmd_t level2_fixmap_pgt[512];
extern pmd_t level2_ident_pgt[512];
extern pte_t level1_fixmap_pgt[512];
extern pgd_t init_top_pgt[]; #define swapper_pg_dir init_top_pgt
1、swapper_pg_dir指向内核最顶级的目录pgd,同时出现的还有几个页表目录。我们可以回忆一下,64位系统的虚拟地址空间的布局
1、期中其中 XXX_ident_pgt 对应的是直接映射区
2、XXX_kernel_pgt 对应的是内核代码区
3、XXX_fixmap_pgt 对应的是固定映射区
2、它们是在哪里初始化的呢?
在汇编语言的文件里面的linux-5.1.3/arch/x86/kernel/head_64.S,这段代码比较难看懂,你只要明白它是干什么的就行了
__INITDATA NEXT_PAGE(init_top_pgt)
.quad level3_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE
.org init_top_pgt + PGD_PAGE_OFFSET*8, 0
.quad level3_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE
.org init_top_pgt + PGD_START_KERNEL*8, 0
/* (2^48-(2*1024*1024*1024))/(2^39) = 511 */
.quad level3_kernel_pgt - __START_KERNEL_map + _PAGE_TABLE NEXT_PAGE(level3_ident_pgt)
.quad level2_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE
.fill 511, 8, 0
NEXT_PAGE(level2_ident_pgt)
/* Since I easily can, map the first 1G.
* Don't set NX because code runs from these pages.
*/
PMDS(0, __PAGE_KERNEL_IDENT_LARGE_EXEC, PTRS_PER_PMD) NEXT_PAGE(level3_kernel_pgt)
.fill L3_START_KERNEL,8,0
/* (2^48-(2*1024*1024*1024)-((2^39)*511))/(2^30) = 510 */
.quad level2_kernel_pgt - __START_KERNEL_map + _KERNPG_TABLE
.quad level2_fixmap_pgt - __START_KERNEL_map + _PAGE_TABLE NEXT_PAGE(level2_kernel_pgt)
/*
* 512 MB kernel mapping. We spend a full page on this pagetable
* anyway.
*
* The kernel code+data+bss must not be bigger than that.
*
* (NOTE: at +512MB starts the module area, see MODULES_VADDR.
* If you want to increase this then increase MODULES_VADDR
* too.)
*/
PMDS(0, __PAGE_KERNEL_LARGE_EXEC,
KERNEL_IMAGE_SIZE/PMD_SIZE) NEXT_PAGE(level2_fixmap_pgt)
.fill 506,8,0
.quad level1_fixmap_pgt - __START_KERNEL_map + _PAGE_TABLE
/* 8MB reserved for vsyscalls + a 2MB hole = 4 + 1 entries */
.fill 5,8,0 NEXT_PAGE(level1_fixmap_pgt)
.fill 51
1、为什么要减去__START_KERNEL_map
1、因为level3_ident_pgt是定义在内核代码里的,写代码的时候,写的都是虚拟地址,谁写代码的时候页不知道将来加载的物理地址是多少呀,对不对
2、因为level3_ident_pgt是在虚拟地址的内核代码里的,而__START_KERNEL_map正是虚拟地址空间内核代码段的其实地址,
3、level3_ident_pgt 减去 __START_KERNEL_map才是物理地址
第一项定义完了以后,接下来我们跳到PGD_PAGE_OFFSET的位置,再定义一项,从定义可以看出
这一项就应该是__PAGE_OFFSET_BASE对应的,__PAGE_OFFSET_BASE 是虚拟地址空间里面内核的起始地址
第二项也指向level3_ident_pgt 直接映射区
PGD_PAGE_OFFSET = pgd_index(__PAGE_OFFSET_BASE)
PGD_START_KERNEL = pgd_index(__START_KERNEL_map)
L3_START_KERNEL = pud_index(__START_KERNEL_map)
第二项定义完了以后,接下来跳到PGD_START_KERNEL的位置,再定义一项,从定义可以看出,这一项应该是_START_KERNEL_map对应的项,
_START_KERNEL_map是虚拟地址空间里面内核代码段的起始地址。第三项指向level3_kernel_pgt,内核代码区
接下来的代码就很类似了,就是初始化个表项,然后指向下一级目录,最终形成下面这张图
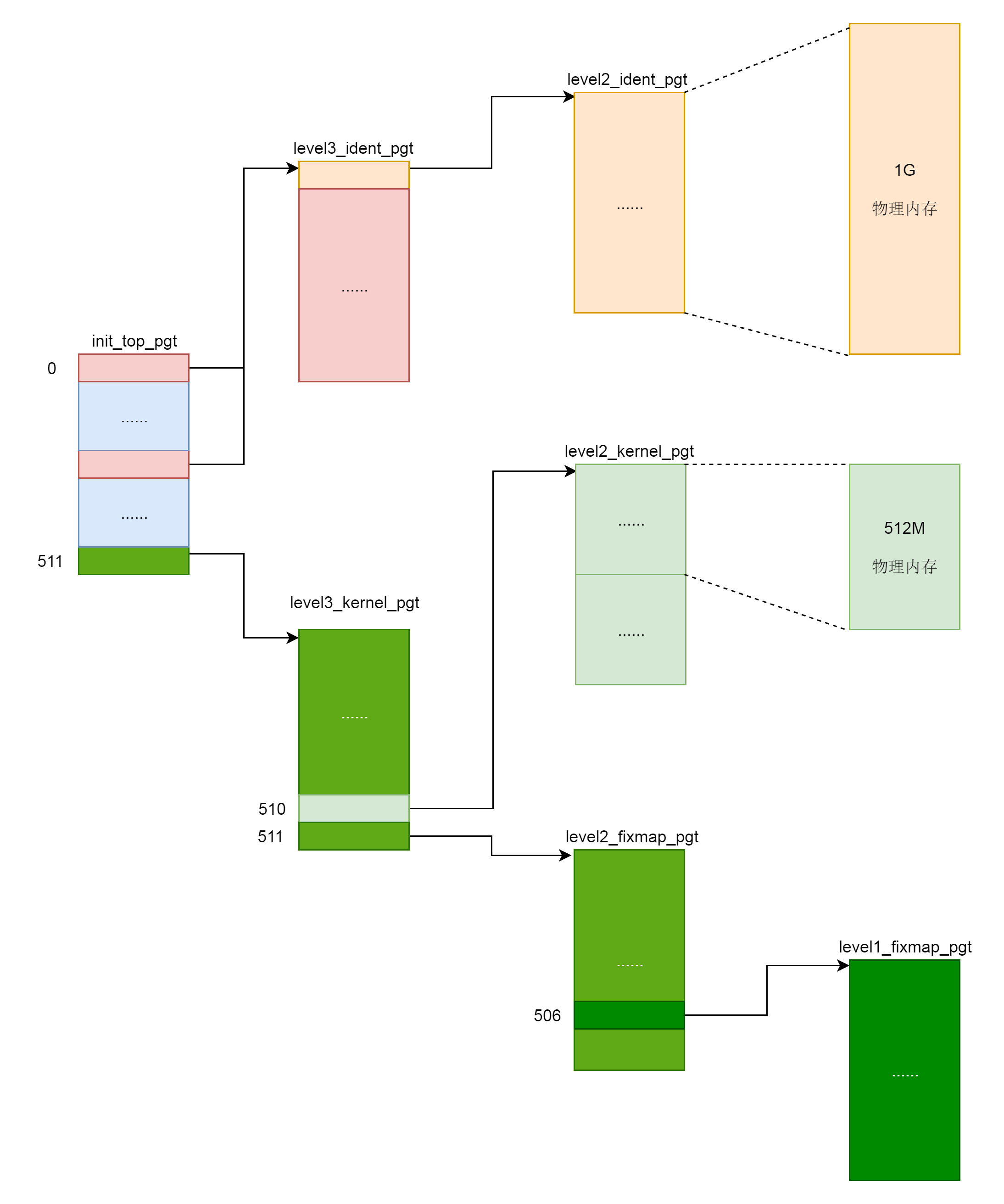
内核页表定完了,一开始这里面的页表能够覆盖的内存范围比较小,例如,内核代码区512M,直接映射区1G,这个时候,其实只要能够映射基本的内核代码和数据结构解可以了。可以看出,里面还空着很多项,
可以用于将来映射巨大的内核虚拟地址空间,等用到的时候再进行映射
如果是用户态进程页表,会有mm_struct指向进程项目录pgd,对于内核来讲,定义了一个mm_stuct,指向swapper_pg_dir
struct mm_struct init_mm = {
.mm_rb = RB_ROOT,
.pgd = swapper_pg_dir,
.mm_users = ATOMIC_INIT(2),
.mm_count = ATOMIC_INIT(1),
.mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
.page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
.user_ns = &init_user_ns,
INIT_MM_CONTEXT(init_mm)
};
在setup_arch中,load_cr3(swapper_pg_dir)说明内核页表要开始起作用了,并且刷新了TLB,初始化init_mm的成员变量,最重要的及时init_mem_mapping,最终它会调用kernel_physical_mapping_init
void __init setup_arch(char **cmdline_p)
{
/*
* copy kernel address range established so far and switch
* to the proper swapper page table
*/
clone_pgd_range(swapper_pg_dir + KERNEL_PGD_BOUNDARY,
initial_page_table + KERNEL_PGD_BOUNDARY,
KERNEL_PGD_PTRS); load_cr3(swapper_pg_dir);
__flush_tlb_all();
......
init_mm.start_code = (unsigned long) _text;
init_mm.end_code = (unsigned long) _etext;
init_mm.end_data = (unsigned long) _edata;
init_mm.brk = _brk_end;
......
init_mem_mapping();
......
}
在 kernel_physical_mapping_init里,我们先通过 __va 将物理地址转换为虚拟地址,,然后在创建虚拟地址和物理地址的映射页表。
1、既然对于内核来讲,我们可以用 __va 和 __pa 直接在虚拟地址和物理地址之间转来转去?
因为这是CPU和内存的硬件的需求,也就是说。CPU在保护模式下访问虚拟地址的时候,就会用CR3这个寄存器,这个寄存器是CPU定义的
作为操作系统,我们是软件,只能按照硬件的要求来。
2、按照咱们将初始化的时候的过程,系统早早就进入了保护模式,到了 setup_arch 里面才 load_cr3,如果使用 cr3 是硬件的要求,那之前是怎么办的呢?
如果你仔细去看 arch\x86\kernel\head_64.S,这里面除了初始化内核页表之外,在这之前,还有另一个页表 early_top_pgt。
看到关键字 early 了嘛?这个页表就是专门用在真正的内核页表初始化之前,为了遵循硬件的要求而设置的
二、vmalloc 和 kmap_atomic 原理
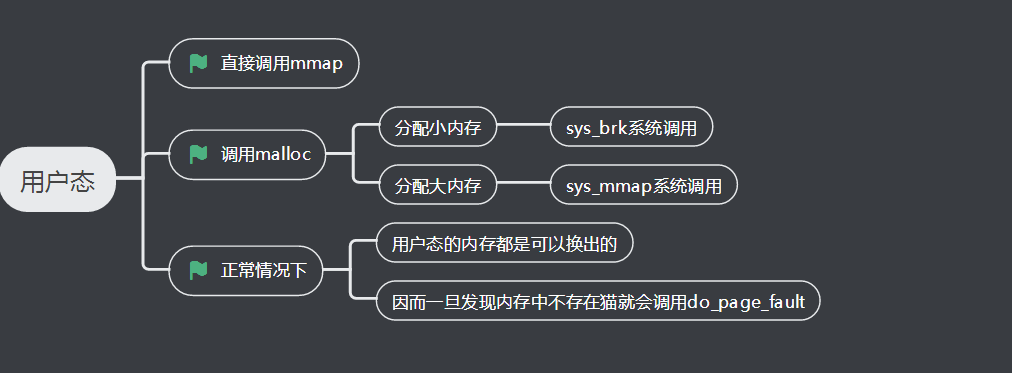
用户态可以通过malloc函数分配内存,当然malloc在分分配比较大的内存的时候,底层调用的是mmap,当然也可以直接通过mmap做内存映射、在内核里面也有相应的函数
在虚拟地址空间里,有个vmalloc区域,从VMALLOC_START开始VMALLOC_END,可以用于映射一段物理内存
/**
* vmalloc - allocate virtually contiguous memory
* @size: allocation size
* Allocate enough pages to cover @size from the page level
* allocator and map them into contiguous kernel virtual space.
*
* For tight control over page level allocator and protection flags
* use __vmalloc() instead.
*/
void *vmalloc(unsigned long size)
{
return __vmalloc_node_flags(size, NUMA_NO_NODE,
GFP_KERNEL);
} static void *__vmalloc_node(unsigned long size, unsigned long align,
gfp_t gfp_mask, pgprot_t prot,
int node, const void *caller)
{
return __vmalloc_node_range(size, align, VMALLOC_START, VMALLOC_END,
gfp_mask, prot, 0, node, caller);
}
我们再来看内核的临时映射函数kmap_atomic的实现,从下面的代码我们可以看出:
1、如果是32位有高端地址的就需要调用set_pte通过内核页表进行临时映射;
2、如果是64位没有高端地址的,就调用page_address,里面会调用lowmen_page_address,
3、其实低端内存的映射,会直接使用_va进行临时映射
void *kmap_atomic_prot(struct page *page, pgprot_t prot)
{
......
if (!PageHighMem(page))
return page_address(page);
......
vaddr = __fix_to_virt(FIX_KMAP_BEGIN + idx);
set_pte(kmap_pte-idx, mk_pte(page, prot));
......
return (void *)vaddr;
} void *kmap_atomic(struct page *page)
{
return kmap_atomic_prot(page, kmap_prot);
} static __always_inline void *lowmem_page_address(const struct page *page)
{
return page_to_virt(page);
} #define page_to_virt(x) __va(PFN_PHYS(page_to_pfn(x)
三、内核态缺页异常
1、vmalloc 和 kmap_atomic 不同
kmap_atomic发现,没有页表的时候,就直接创建也表进行映射了、而vmalloc没有,它只分配了内核的虚拟地址、所以,访问它的时候,会产生缺页异常
2、内核态的缺页异常
内核态的缺页异常还是会调用do_page_fault,但是会走到咱们上面用户态缺页异常中没有解析的部分vmalloc_fault。这个函数并不复杂,主要用于关联内核页表项
/*
* 32-bit:
*
* Handle a fault on the vmalloc or module mapping area
*/
static noinline int vmalloc_fault(unsigned long address)
{
unsigned long pgd_paddr;
pmd_t *pmd_k;
pte_t *pte_k; /* Make sure we are in vmalloc area: */
if (!(address >= VMALLOC_START && address < VMALLOC_END))
return -1; /*
* Synchronize this task's top level page-table
* with the 'reference' page table.
*
* Do _not_ use "current" here. We might be inside
* an interrupt in the middle of a task switch..
*/
pgd_paddr = read_cr3_pa();
pmd_k = vmalloc_sync_one(__va(pgd_paddr), address);
if (!pmd_k)
return -1; pte_k = pte_offset_kernel(pmd_k, address);
if (!pte_present(*pte_k))
return -1; return 0
四、总结时刻
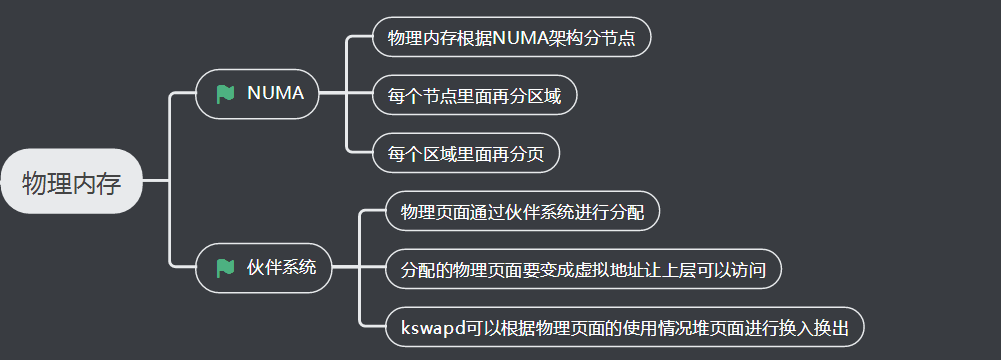
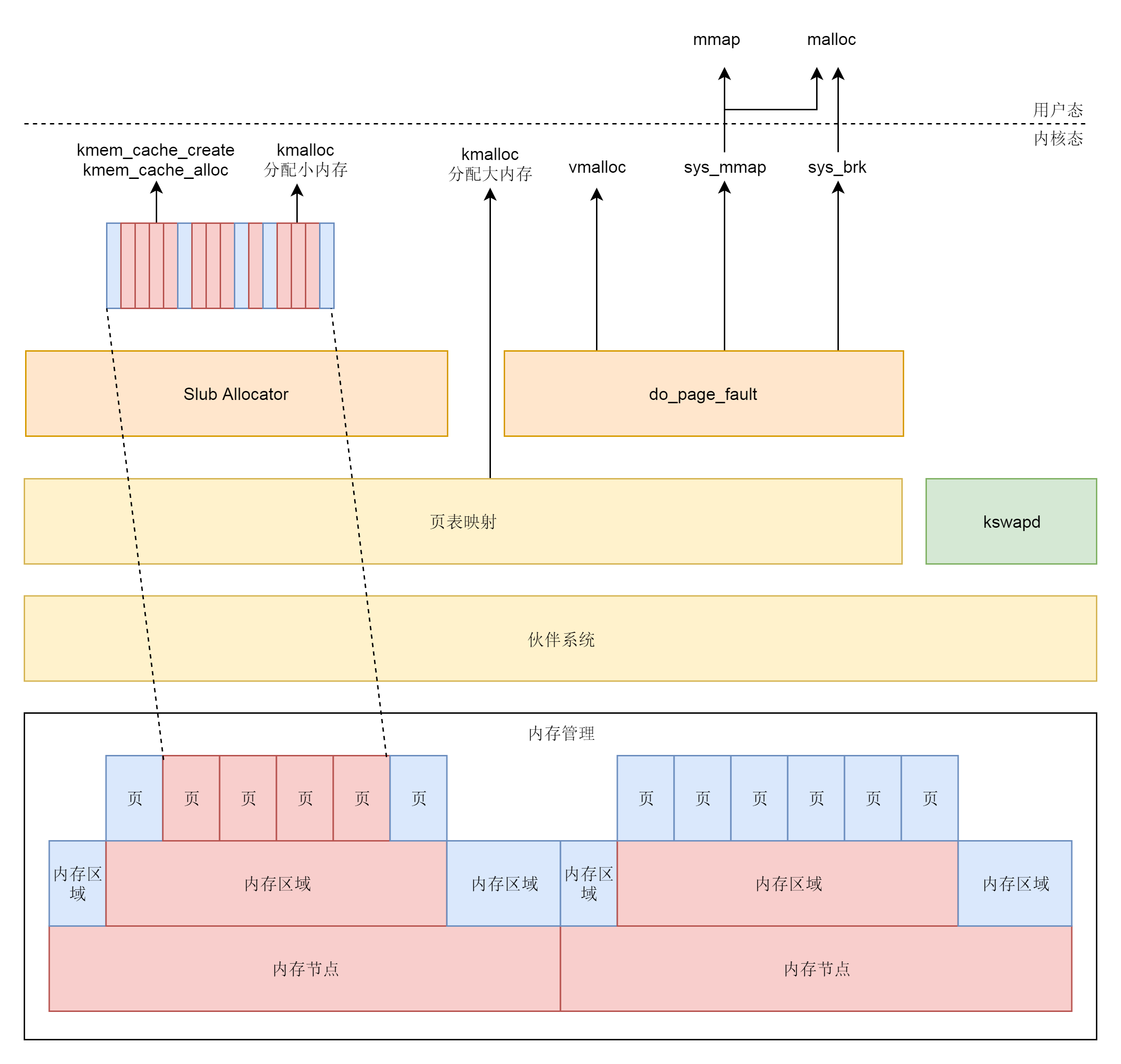
1、物理内存管理
2、内存分配内核态
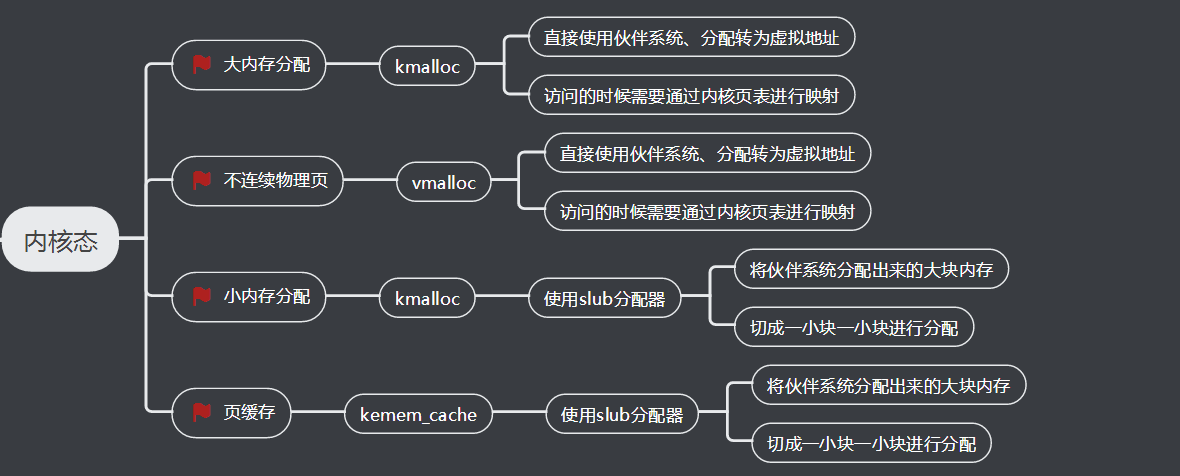
kemem_cache和kmalloc的部分不会被换出、因为用这两个函数分配的内存多用于保存内核关键的数据结构,内核中vmalloc分配的部分会被换出,因而当访问的时候、发现不再
就会调用do_page_fault
3、内存分配用户态
4、内存分配体系总图
趣谈Linux操作系统学习笔记:第二十六讲的更多相关文章
- 深挖计算机基础:趣谈Linux操作系统学习笔记
参考极客时间专栏<趣谈Linux操作系统>学习笔记 核心原理篇:内存管理 趣谈Linux操作系统学习笔记:第二十讲 趣谈Linux操作系统学习笔记:第二十一讲 趣谈Linux操作系统学习笔 ...
- 趣谈Linux操作系统学习笔记:第二十讲
一.引子 1.计算两方面的原因 2.内存管理机制 二.独享内存空间的原理 1.会议室和物理内存的关系 和会议室一样,内存都被分成一块块儿的,都编号了号,例如3F-10就是三楼十号会议室.内存页有这样一 ...
- 趣谈Linux操作系统学习笔记:第二十四讲
一.小内存的分配基础 1.kmem_cache_alloc_node的作用 通过这段代码可以看出,它调用了kmem_cache_alloc_node函数,在task_struct的缓存区域task_s ...
- 趣谈Linux操作系统学习笔记:第二十五讲
一.mmap原理 在虚拟内存空间那一节,我们知道,每一个进程都有一个列表vm_area_struct,指向虚拟地址空间的不同内存块,这个变量名字叫mmap struct mm_struct { str ...
- 趣谈Linux操作系统学习笔记:第二十八讲
一.引子 磁盘→盘片→磁道→扇区(每个 512 字节) ext* 定义文件系统的格式 二.inode 与块的存储 1.块 2.不用给他分配一块连续的空间 我们可以分散成一个个小块进行存放 1.优点 2 ...
- 趣谈Linux操作系统学习笔记:第二十九讲
一.引子 在这之前,有一点你需要注意.解析系统调用是了解内核架构最有力力的一把钥匙,这里我们只要重点关注这几个最重要的系统调用就可以了 1.mount 系统调用用于挂载文件系统:2.open 系统调用 ...
- 趣谈Linux操作系统学习笔记:第二十七讲
一.文件系统的功能规划 1.引子 咱们花了这么长的时间,规划了会议室管理系统,这样多个项目执行的时候,隔离性可以得到保证. 但是,会议室里面被回收,会议室里面的资料就丢失了.有一些资料我们希望项目结束 ...
- 趣谈Linux操作系统学习笔记:第二十一讲
一.分段机制 1.分段机制的原理图 2.段选择子 3.段偏移量 例如,我们将上面的虚拟空间分成以下 4 个段,用 0-3 来编号.每个段在段表中有一个项,在物理空间中,段的排列如下图的右边所示. 4. ...
- Python学习笔记第二十六周(Django补充)
一.基于jQuery的ajax实现(最底层方法:$.jax()) $.ajax( url: type:''POST“ ) $.get(url,[data],[callback],[type]) #c ...
随机推荐
- 分布式缓存 Redis 集群搭建
Redis 集群简介 Redis Cluster 即 Redis 集群,是 Redis 官方在 3.0 版本推出的一套分布式存储方案.完全去中心化,由多个节点组成,所有节点彼此互联.Redis 客户端 ...
- 解决idea中mysql连接失败Could not create connection to database server. Attempted reconnect 3 times. Giving up.
原因是少一个参数,设置时区的. 解决方法: 加一个参数: serverTimezone=UTC jdbc:mysql://localhost:3306/SshProject?useUnicode=t ...
- 实训第六天(mybatis)
今天实训第六天,我们学习了mybatis这个数据库框架,虽然说框架的环境搭建非常的繁琐,但是在了解原理和流程之后是非常的舒服的.因为有一个强大的工具被我掌握了,所以今天感觉非常的开心. 首先我们是在s ...
- React每隔0.2s颜色变淡 之settimeOut变成setInterval
案例 每隔0.2s颜色变淡 公共数据是放在state中的哦! 代码如下 import React, { Component } from "react"; import { set ...
- java基础 - 什么是hashmap的负载因子,hashmap的容量(即桶个数)为什么是2的幂次
HashMap的负载因子是指,比如容量为16,负载因子为0.75,则当HashMap的元素个数达到16*0.75=12时,触发扩容.(16和0.75是初始默认的容量和负载因子). HashMap的容量 ...
- ubuntu18.04因java路径原因启动jenkins失败
我的云服务器ubuntu18.04上本来装了jenkins,今天安装完tomcat后,将原有的openjdk卸载了,安装了jdk8u192, 此时浏览器访问8080端口显示的就是tomcat安装成功的 ...
- java之操作集合的工具类--Collections
Collections是一个操作Set.List和Map等集合的工具类. Collections中提供了大量方法对集合元素进行排序.查询和修改等操作,还提供了对集合对象设置不可变.对集合对象实现同步控 ...
- Java 后台请求第三方系统接口详解
//调用第三方系统接口 PrintWriter out = null; BufferedReader in = null; JSONObject jsonObject = null; Closeabl ...
- java 与 iOS 平台概念比较
java oc/swift jvm iphone jre runtime? jdk ios SDK spring xcode 生成的应用模版 服务器(tomcat) 系统的事件调度派发部分 class ...
- Slickflow.NET 开源工作流引擎高级开发(五) -- 引擎和外部事件的交互
前言:引擎组件的基本职责是负责流程流转,但是在流转过程中,除了对内部控制逻辑进行实现外,也不可避免的要去调用或者响应外部事件.本文主要描述外部事件的类型,以及调用方法过程. 1. 外部事件的类型 外部 ...