使用python划分数据集
无论是训练机器学习或是深度学习,第一步当然是先划分数据集啦,今天小白整理了一些划分数据集的方法,希望大佬们多多指教啊,嘻嘻~
首先看一下数据集的样子,flower_data文件夹下有四个文件夹,每个文件夹表示一种花的类别

划分数据集的主要步骤:
1. 定义一个空字典,用来存放各个类别的训练集、测试集和验证集,字典的key是类别,value也是一个字典,存放该类别的训练集、测试集和验证集;
2.使用python获取所有的类别文件夹;
3.对每个类别划分训练集、测试集和验证集:(1)把该类别的所有有效图片放入一个列表中;(2)设置一个随机数对列表进行划分。
具体的代码实现如下所示
import glob
import os.path
import random
import numpy as np
# 图片数据文件夹
INPUT_DATA = './flower_data'
# 这个函数从数据文件夹中读取所有的图片列表并按训练、验证、测试数据分开
# testing_percentage和validation_percentage指定了测试数据集和验证数据集的大小
def create_image_lists(testing_percentage,validation_percentage):
# 得到的所有图片都存在result这个字典里,key为类别的名称,value值也是一个字典,存放的是该类别的
# 文件名、训练集、测试集和验证集
result = {}
# 获取当前目录下所有的子目录,这里x 是一个三元组(root,dirs,files),第一个元素表示INPUT_DATA当前目录,
# 第二个元素表示当前目录下的所有子目录,第三个元素表示当前目录下的所有的文件
sub_dirs = [x[0] for x in os.walk(INPUT_DATA)]
# sub_dirs = ['./flower_data','./flower_data\\daisy','./flower_data\\dandelion',
# './flower_data\\roses','./flower_data\\sunflowers','./flower_data\\tulips']
# 每个子目录表示一类花,现在对每类花划分训练集、测试集和验证集
# sub_dirs[0]表示当前文件夹本身的地址,不予考虑,只考虑他的子目录(各个类别的花)
for sub_dir in sub_dirs[1:]:
# 获取当前目录下所有的有效图片文件
extensions = ['jpg','jpeg']
# 把图片存放在file_list列表里
file_list = []
# os.path.basename(sub_dir)返回sub_sir最后的文件名
# 如os.path.basename('./flower_data/daisy')返回daisy
dir_name = os.path.basename(sub_dir)
for extension in extensions:
file_glob = os.path.join(INPUT_DATA,dir_name,'*.'+extension)
# glob.glob(file_glob)获取指定目录下的所有图片,存放在file_list中
file_list.extend(glob.glob(file_glob))
if not file_list: continue
# 通过目录名获取类别的名称,返回将字符串中所有大写字符转换为小写后生成的字符串
label_name = dir_name.lower()
# 初始化当前类别的训练数据集、测试数据集和验证数据集
training_images = []
testing_images = []
validation_images = []
for file_name in file_list:
base_name = os.path.basename(file_name)
# 随机将数据分到训练数据集、测试数据集和验证数据集
# 产生一个随机数,最大值为100
chance = np.random.randint(100)
if chance < validation_percentage:
validation_images.append(base_name)
elif chance < (testing_percentage+validation_percentage):
testing_images.append(base_name)
else:
training_images.append(base_name)
# 将当前类别是数据放入结果字典
result[label_name]={'dir':dir_name,
'training':training_images,
'testing':testing_images,
'validation':validation_images}
# 返回整理好的所有数据
return result
result = create_image_lists(10,30)
print(result)
运行结果:
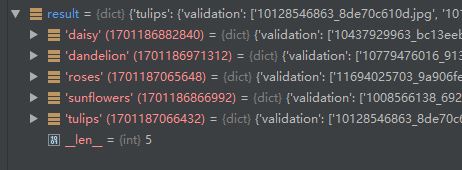
可以看出字典result中有五个key,表示五个类别。
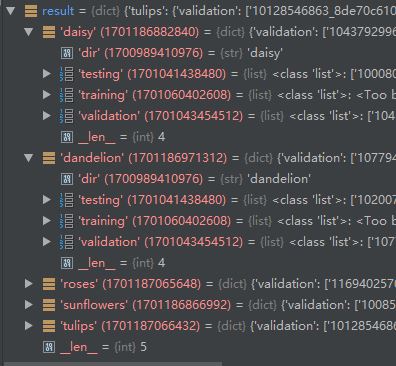
下图是各个类别的划分情况:
使用python划分数据集的更多相关文章
- Pytorch划分数据集的方法
之前用过sklearn提供的划分数据集的函数,觉得超级方便.但是在使用TensorFlow和Pytorch的时候一直找不到类似的功能,之前搜索的关键字都是"pytorch split dat ...
- 【机器学习算法-python实现】决策树-Decision tree(1) 信息熵划分数据集
(转载请注明出处:http://blog.csdn.net/buptgshengod) 1.背景 决策书算法是一种逼近离散数值的分类算法,思路比較简单,并且准确率较高.国际权威的学术组织,数据挖掘国际 ...
- 使用Sklearn-train_test_split 划分数据集
使用sklearn.model_selection.train_test_split可以在数据集上随机划分出一定比例的训练集和测试集 1.使用形式为: from sklearn.model_selec ...
- sklearn 划分数据集。
1.sklearn.model_selection.train_test_split随机划分训练集和测试集 函数原型: X_train,X_test, y_train, y_test =cross_v ...
- KNN手写实践:Python基于数据集整体计算以及排序
1. 距离计算,不要通过遍历每个样本来计算和指定样本距离,而是通过对于指定样本进行广播(复制)成为一个shape和全局一致后,再进行整体计算,这里的广播 / 复制采用的是tile函数来实现的: 2. ...
- Python处理数据集-2
原数据集的数据格式: 每行为:(test_User, test_Item) negativeItem1 negativeItem2 negativeItem3 …… negativeItem99 即每 ...
- Python处理数据集-1
原数据集的数据格式: 每行为:(test_User, test_Item) negativeItem1 negativeItem2 negativeItem3 …… negativeItem99 即每 ...
- python 鸢尾花数据集报表展示
import seaborn as snsimport pandas as pdimport matplotlib.pyplot as pltsns.set_style('white',{'font. ...
- pandas DataFrame 数据处理常用操作
Xgboost调参: https://wuhuhu800.github.io/2018/02/28/XGboost_param_share/ https://blog.csdn.net/hx2017/ ...
随机推荐
- get the page name from url
https://stackoverflow.com/questions/1874532/better-way-to-get-page-name The way I interpret the ques ...
- yii2.0 ActiveRecord 查询汇总
User::find()->all(); 此方法返回所有数据: User::findOne($id); 此方法返回 主键 id=1 的一条数据(举个例子): User::find()->w ...
- Ubuntu 搭建 LAMP 服务器
/******************************************************************** * Ubuntu 搭建 LAMP 服务器 * 说明: * 想 ...
- 创建oracle数据库job服务
创建oracle数据库job服务:PlSqlDev操作job https://www.baidu.com/link?url=5vXhw0IqjvWEAgGSIYsSEVPvJb6njGkJ-_P_VF ...
- 【IOI 1996】 Network of Schools
[题目链接] 点击打开链接 [算法] 对于第一问,将这个图缩点,输出出度为零的点的个数 对于第二问,同样将这个图缩点,输出入度为零.出度为零的点的个数的最大值 [代码] #include <al ...
- bzoj1044 [HAOI2008]木棍分割——前缀和优化DP
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=1044 咳咳...终于A了... 居然没注意到正着找pos是n方会TLE...所以要倒着找po ...
- poj 3311(DP + 状态压缩)
Hie with the Pie Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 5205 Accepted: 2790 ...
- springmvc h5上传图片
工作中开发一个评价功能,需要上传拍照的图片,后台使用springmvc接收文件,前端FormData异步提交. 1. spring配置multipartResolver <bean id=&qu ...
- Linux 系统管理命令 - iostat - I/O 信息统计
命令详解 重要星级: ★★★★☆ 功能说明: iostat 是 I/O statistics ( 输入/输出统计 ) 的缩写,其主要功能是对系统的磁盘 I/O 操作进行监视.它的输出主要是显示磁盘读写 ...
- docker学习教程
我们的docker学习教程可以分为以下几个部分,分别是: 第一:docker基础学习 第二:docker日志管理 第三:docker监控管理 第四:docker三剑客之一:docker-machine ...