day16-小数据池
一,什么是代码块
Python程序是由代码块构造的。块是一个python程序的文本,他是作为一个单元执行的。
代码块:一个模块,一个函数,一个类,一个文件等都是一个代码块。
而作为交互方式输入的每个命令都是一个代码块。
什么叫交互方式?就是咱们在cmd中进入Python解释器里面,每一行代码都是一个代码块,例如:

而对于一个文件中的两个函数,也分别是两个不同的代码块:

二,id,is,==
在Python中,id是什么?id是内存地址,比如你利用id()内置函数去查询一个数据的内存地址:
name = 'Tom'
print(id(name))
#
那么 is 是什么? == 又是什么?
== 是比较的两边的数值是否相等,而 is 是比较两边的内存地址是否相等。 如果内存地址相等,那么这两边其实是指向同一个内存地址。

可以说如果内存地址相同,那么值肯定相同,但是如果值相同,内存地址不一定相同。
三,小数据池
小数据池,也称为小整数缓存机制,或者称为驻留机制等等。
那么到底什么是小数据池?他有什么作用呢?
大前提:小数据池,只针对,整数,字符串,bool值。
官方对于整数,字符串的小数据池是这么说的:
对于整数,Python官方文档中这么说:
The current implementation keeps an array of integer objects for all integers between -5 and 256, when you create an int in that range you actually just get back a reference to the existing object. So it should be possible to change the value of 1. I suspect the behaviour of Python in this case is undefined. 对于字符串:
Incomputer science, string interning is a method of storing only onecopy of each distinct string value, which must be immutable. Interning strings makes some stringprocessing tasks more time- or space-efficient at the cost of requiring moretime when the string is created or interned. The distinct values are stored ina string intern pool. –引自维基百科
翻译并汇总一下,表达的意思就是:
Python自动将-5~256的整数进行了缓存,当你将这些整数赋值给变量时,并不会重新创建对象,而是使用已经创建好的缓存对象。
python会将一定规则的字符串在字符串驻留池中创建一份,当你将这些字符串赋值给变量时,并不会重新创建对象, 而是使用在字符串驻留池中创建好的对象。
其实,无论是缓存还是字符串驻留池,都是python做的一个优化,就是将-5~256的整数,和一定规则的字符串,放在一个‘池’(容器,或者字典)中,无论程序中那些变量指向这些范围内的整数或者字符串,那么他直接在这个‘池’中引用,言外之意,就是内存中只创建一个。
优点:能够提高一些字符串,整数处理在时间和空间上的性能;需要值相同的字符串,整数的时候,直接从‘池’里拿来用,避免频繁地创建和销毁,提升效率,节约内存。
缺点:在‘池’中创建或插入字符串、整数时,会花费更多的时间。
int:那么大家都知道对于整数来说,小数据池的范围是-5~256 ,如果多个变量都是指向同一个(在这个范围内的)数字,他们在内存中指向的都是一个内存地址。
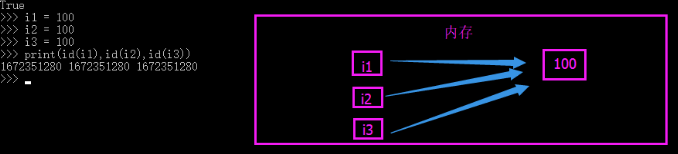
那么对于字符串的规定呢?
str:字符串要从下面这几个大方向讨论:
1,字符串的长度为0或者1,默认都采用了驻留机制(小数据池)。

2,字符串的长度>1,且只含有大小写字母,数字,下划线时,才会默认驻留。
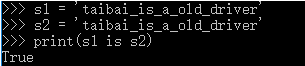
3,用乘法得到的字符串,分两种情况。
3.1 乘数为1时:
仅含大小写字母,数字,下划线,默认驻留。

含其他字符,长度<=1,默认驻留。

含其他字符,长度>1,默认驻留。

3.2 乘数>=2时:
仅含大小写字母,数字,下划线,总长度<=20,默认驻留。
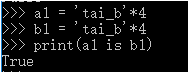
4,指定驻留。
from sys import intern
a = intern('hello!@'*20)
b = intern('hello!@'*20)
print(a is b)
#指定驻留是你可以指定任意的字符串加入到小数据池中,让其只在内存中创建一个对象,多个变量都是指向这一个字符串。
满足以上字符串的规则时,就符合小数据池的概念。
bool值就是True,False,无论你创建多少个变量指向True,False,那么它在内存中只存在一个。
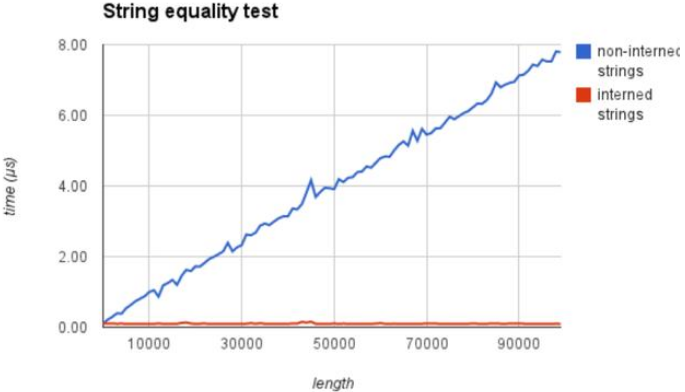
看一下用了小数据池(驻留机制)的效率有多高:
显而易见,节省大量内存在字符串比较时,非驻留比较效率o(n),驻留时比较效率o(1)。
四,代码块与小数据池的关系。
同样一段代码,为什么在交互方式中执行,和通过python代码的文件执行结果不同呢?
# pycharm 通过运行文件的方式执行下列代码:
i1 = 1000
i2 = 1000
print(i1 is i2) # 结果为True
通过交互方式中执行下面代码:
>>> i1 = 1000
>>> i2 = 1000
>>> print(i1 is i2)
False
结果为什么不同呢?难道是解释器出问题,还是pycharm软件出问题了?
这是因为代码块内的缓存机制,和代码块与代码块之间的缓存机制不同!
Python在执行同一个代码块的初始化对象的命令时,会检查是否其值是否已经存在,如果存在,会将其重用。换句话说:执行同一个代码块时,遇到初始化对象的命令时,他会将初始化的这个变量与值存储在一个字典中,在遇到新的变量时,会先在字典中查询记录,如果有同样的记录那么它会重复使用这个字典中的之前的这个值。所以在你给出的例子中,文件执行时(同一个代码块)会把i1、i2两个变量指向同一个对象。
如果是不同的代码块,他就会看这个两个变量是否是满足小数据池的数据,如果是满足小数据池的数据则会指向同一个地址。所以:i1、i2赋值语句分别被当作两个代码块执行,但是他们不满足小数据池的数据所以会得到两个不同的对象,因而is判断返回False。
更多验证:
# 虽然在同一个文件中,但是是不同的代码块,不满足小数据池(驻存机制),则指向两个不同的地址。
def func():
i1 = 1000
print(id(i1)) # def func2():
i1 = 1000
print(id(i1)) # func()
func2()
最后,在深入一点,对于同一个代码块的变量复用的问题,只能针对于数字,字符串,bool值,而对于其他数据类型是不成立的。
# 同一个代码块下,数字,字符串,bool值的复用成立。
a1 = 1000
a2 = 1000
print(id(a1),id(a2)) # 2419837390800 2419837390800 s1 = 'alexsb@'
s2 = 'alexsb@' print(id(s1),id(s2)) # 2278732245624 2278732245624 f1 = True
f2 = True
print(id(f1),id(f2)) # 1672093872 1672093872 # 同一个代码块下,元祖,列表,字典的复用不成立。
tu1 = (1,2,3)
tu2 = (1,2,3)
print(id(tu1),id(tu2)) # 2278732278088 2278732279312 l1 = [1, 2, 3]
l2 = [1, 2, 3]
print(id(l1),id(l2)) # 2278733685000 2278733685192 dic1 = {'name':'taibai'}
dic2 = {'name':'taibai'}
print(id(dic1),id(dic2)) # 2278728382728 2278728382856
本文引用和参考链接如下:
http://www.cnblogs.com/jin-xin/articles/9439483.html
day16-小数据池的更多相关文章
- python2与python3的区别 ,小数据池 bytes 类型
一.python2和3的区别 在python3中 在python2中 print('ab')方式打印内容()括号是必须要有的. print 'ab' 可以加可以不加. 只有range 有ran ...
- id,is的用法,小数据池的概念及编码知识进阶
一:id 查询内存地址 name = 'alex' print(id(name)) li = [1,2,3] print(id(li)) 二:is 判断的是内存地址 name1 = 'alex@' ...
- 07_Python变量内存地址、小数据池
一.变量在内存中的地址 变量:用来标识(identify)一块内存区域.为了方便表示内存,我们操作变量实质上是在操作变量指向的那块内存单元.编译器负责分配.我们可以使用Python内建函数id()来获 ...
- Python二次编码、小数据池之心照神交
二次编码.解码.小数据池: encode(str:编码):参数编码方式,返回字节码. str_1 = "编码" str_2 = str_1.encode("utf-8&q ...
- day4-python基础-小数据池以及深浅copy浅讲
今天的目录是 1.小数据池 2.深浅copy 正文开始 1.小数据池 在说明今天的内容前,先说明一个在今天重复用到的一个知识点 ###比较’=’俩边的数据是否完全相同,以及判断一个对象的内存地址是否完 ...
- Python小数据池和字典操作
小数据池 #id 查看内存地址 #多个代码块可以使用小数据池 #一个代码块中有一个问题,就是重复使用 #数字 -5~256 #字符串 字符串 乘法总数长度不能超过20, 0,1除外 #不能有特殊字符 ...
- python基础之小数据池、代码块、编码和字节之间换算
一.代码块.if True: print(333) print(666) while 1: a = 1 b = 2 print(a+b) for i in '12324354': print(i) 虽 ...
- python之路day06--python2/3小区别,小数据池的概念,编码的进阶str转为bytes类型,编码和解码
python2#print() print'abc'#range() xrange()生成器#raw_input() python3# print('abc')# range()# input() = ...
- range 小数据池介绍
1.range 2.小数据池 1. range 范围 [起始位置:终止位置:步长]range(起始位置,终止位置,步长) #顾头不顾尾 3.小数据池 小数据池,也称为小整数缓存机制,或者称为驻留机制等 ...
- python -- 小数据池 is和 == 再谈编码
1.小数据池 python程序是由代码块构成的,一个代码块的文本作为python程序的执行单元. 代码块:一个模块,一个函数,一个类,甚至一个command命令都是一个代码块,一个文件也是一个代码块, ...
随机推荐
- WordPress设置地址的问题
刚刚安装了一个Wordpress,第一次使用,所以对设置不是很熟悉. 在常规设置那里,有两个地址设置,一个是WordPress 地址(URL),另一个是站点地址(URL),刚开始分不清这两个的区别,所 ...
- 安卓权威编程指南 - 第五章学习笔记(两个Activity)
学习安卓编程权威指南第五章的时候自己写了个简单的Demo来加深理解两个Activity互相传递数据的问题,然后将自己的学习笔记贴上来,如有错误还请指正. IntentActivityDemo学习笔记 ...
- 第一天课程:第一个python程序print say hello
print("Hello World") linux下要加可执行权限 chmod 755 hello.py 权限755,7=4+2+1,4是读,2是写,1是执行,第一个7代表用户, ...
- idea 破解方法--可以使用到2099年
破解方式有2种,第一种比较方便 第一种比较方便 1.使用注册码破解:http://idea.lanyus.com/ 复制这段: 2. 修改hosts文件: hosts位置:C:\Windows\Sys ...
- [UE4]先报告后广播模式
解决客户端射击,在服务器端和其他客户端看不到的问题. 一.把要广播的操作封装成一个事件(函数不支持网络属性),选择“多路传送” 二.创建一个事件,选择“在服务器上运行” 总结:从客户端执行的事件报告到 ...
- phpmyadmin在nginx环境下配置错误
location ~ \.css { add_header Content-Type text/css; } location ~ \.js { ...
- .net core identity(一)简单运用
1.net core identity涉及到很多知识,很多概念包括Claims,Principal等等概念需要我们一步步学习才能掌握其原理,有两篇博客是比较好的介绍该框架的, https://segm ...
- typescript函数类型接口
/* 接口的作用:在面向对象的编程中,接口是一种规范的定义,它定义了行为和动作的规范,在程序设计里面,接口起到一种限制和规范的作用.接口定义了某一批类所需要遵守的规范,接口不关心这些类的内部状态数据, ...
- 可变卷积Deforable ConvNet 迁移训练自己的数据集 MXNet框架 GPU版
[引言] 最近在用可变卷积的rfcn 模型迁移训练自己的数据集, MSRA官方使用的MXNet框架 环境搭建及配置:http://www.cnblogs.com/andre-ma/p/8867031. ...
- (转)C# WebApi 身份认证解决方案:Basic基础认证
原文地址:http://www.cnblogs.com/landeanfen/p/5287064.html 阅读目录 一.为什么需要身份认证 二.Basic基础认证的原理解析 1.常见的认证方式 2. ...