集成算法(chapter 7 - Hands on machine learning with scikit learn and tensorflow)
Voting classifier
多种分类器分别训练,然后分别对输入(新数据)预测/分类,各个分类器的结果视为投票,投出最终结果:
训练:
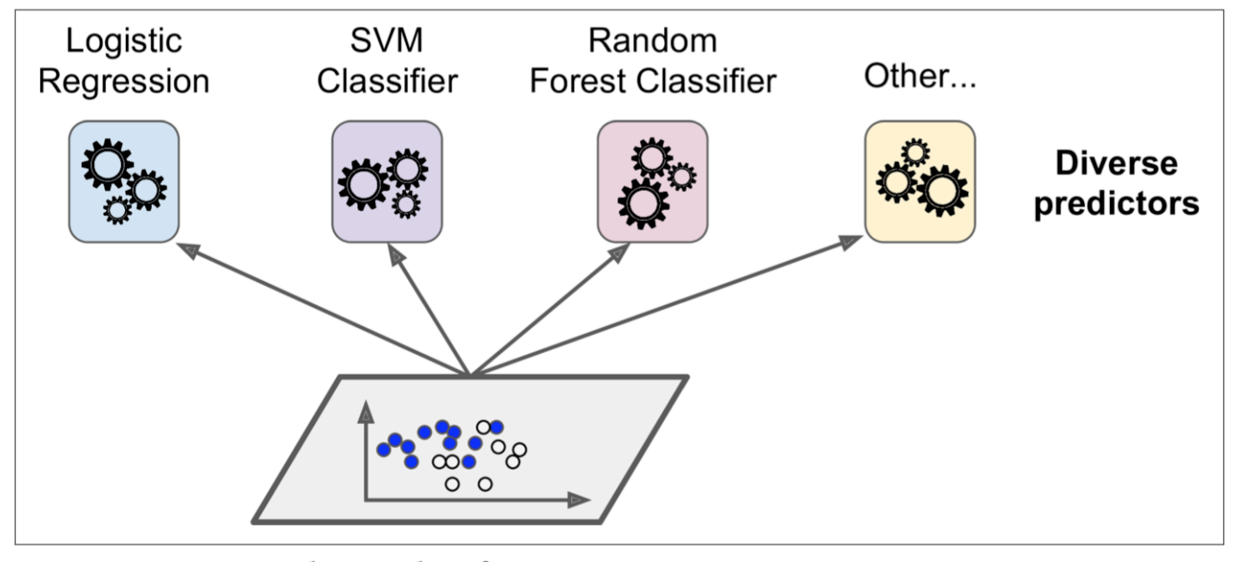
投票:

为什么三个臭皮匠顶一个诸葛亮。通过大数定律直观地解释:
一个硬币P(H)=0.51。大数定律保证抛硬币很多次之后,平均得到的正面频数接近\(0.51 \times N\),并且N越大,越接近。那么换个角度,N表示同时掷硬币的人数,即为这边的N个臭皮匠,他们的结果合到一起就得到的是接近真实结果的值。
进一步根据中心极限定理,即二项分布以正态分布为其极限分布定律,可以计算“N次抛硬币后,header占大多数的概率”
例如P(H)=0.51,N=1000,则\(\Pr(\text{Header 占大多数}) = 1-\Phi (\frac{n/2 - np}{\sqrt{np(1-p)}})=\Phi(0.63)=0.74\),当N=10000,\(Pr=\Phi(2)=0.98\)
Bagging and Pasting
跟投票的思路不同,Bagging(boost aggregating)的思路是同一算法训练多个模型,每个模型训练时只使用部分数据。预测时,每个模型分别给出自己的预测结果,再将这些结果聚合起来。
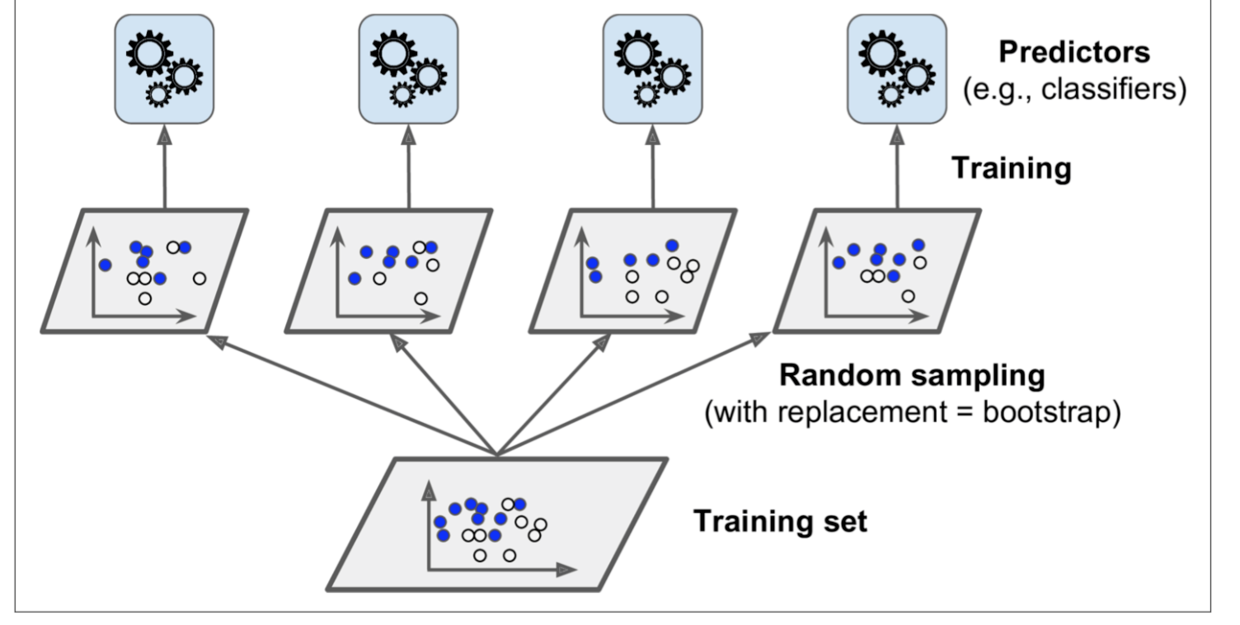
Out Of Bag
因为每个模型训练时随机选择每个训练sample数据,那么,对于某个sample而言,有可能被选中0次或多次。如果一个sample没有被选中,那么它很自然地可以被用做交叉验证。
某个sample至少被一个模型训练用到的概率,\(\Pr(\text{sample被选中})=1-\left( 1- \frac{1}{N}\right)^k\)
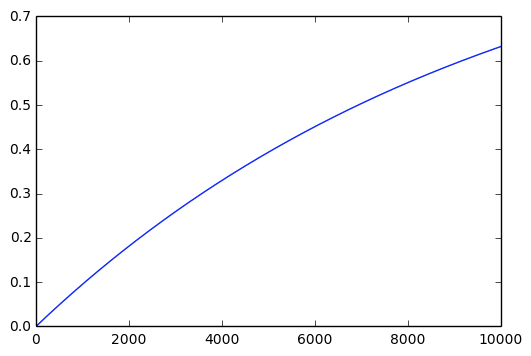
\(k=N\), \(\lim_{N\to\infty}1-\left(1-\frac{1}{N}\right)^N=1-e^{-1} =0.63\)
parallel training pattern
bagging算法需要训练多个模型,每个模型的训练过程相同,只是算法使用的数据不同。联想到并行训练的问题,两种思路:
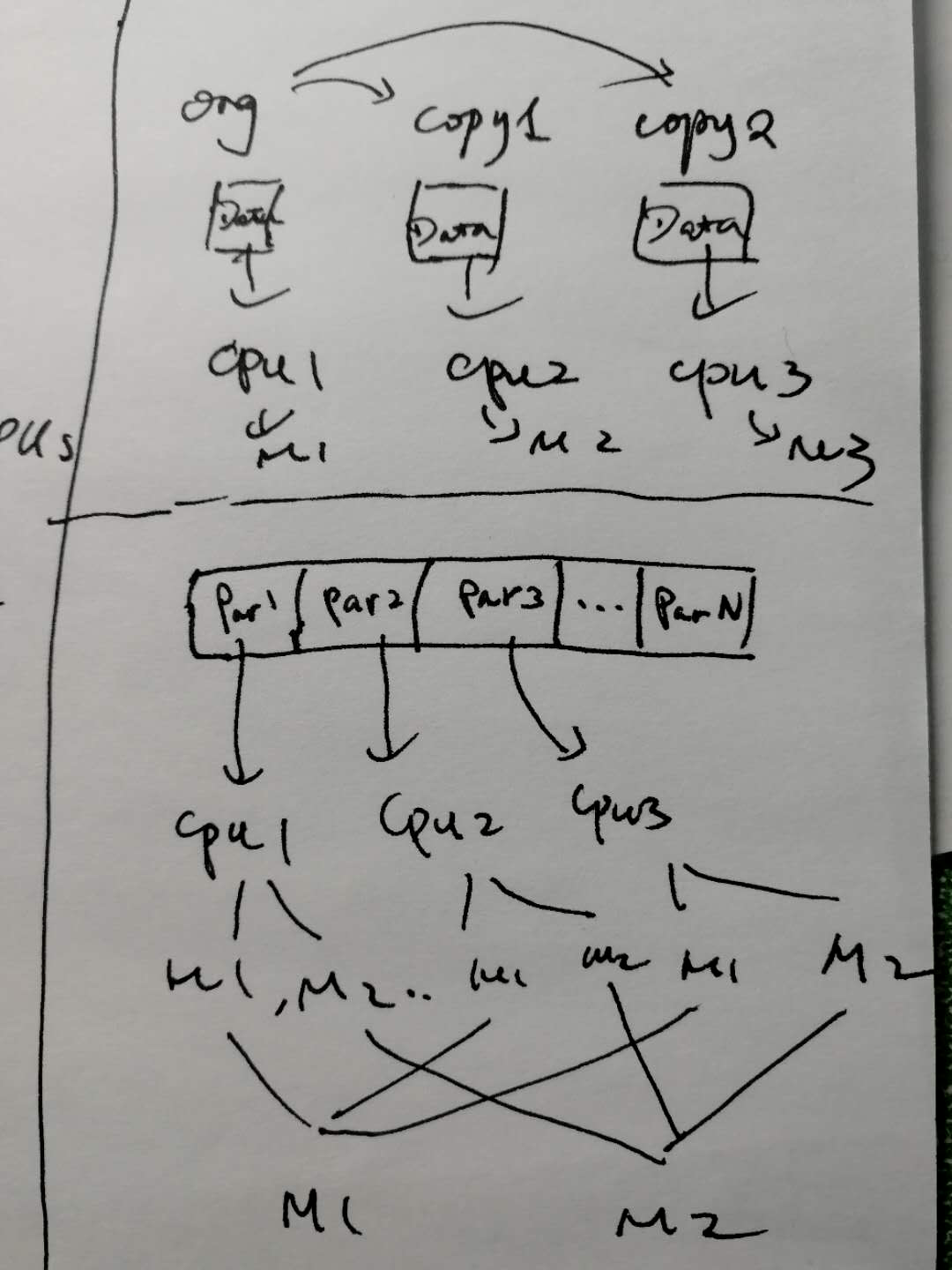
- 如果训练样本数比较小,每个模型能够承受所有数据,那么使用上面的模式。
- 如果训练样本很大,需要分区到多个cpu/节点上,那么每个节点只消费部分训练样本,但是每个节点可以同时训练多个模型,最终再把各个模型的半成品结合到一起形成完整的模型。
随机森林
随机森林一般采用bagging算法训练模型。
rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, n_jobs=-1)
bag_clf = BaggingClassifier(
DecisionTreeClassifier(splitter="random", max_leaf_nodes=16),
n_estimators=500, max_samples=1.0, bootstrap=True, n_jobs=-1
)
Feature Importance
Lastly, if you look at a single Decision Tree, important features are likely to appear closer to the root of the tree, while unimportant features will often appear closer to the leaves (or not at all). It is therefore possible to get an estimate of a feature’s importance by computing the average depth at which it appears across all trees in the forest.
Boosting
定义:any Ensemble method that can combine several weak learners into a strong learner. The general idea of most boosting methods is to train predictors sequentially, each trying to correct its predecessor.
AdaBoosting
如果各一个样本被predecessor分类器误分类了,那么下一个分类器将会更重视这个样本(boost/提升这个样本)。
所以在顺序训练模型时,每个样本的重要性在变化:

Gradient Boosting
Gradient Boosting也是通过不断增加predictor来修正之前的predictor。不同于adaboost的地方是,gradient boosting调整每个样本的权重,后面的predictor直接去拟合前面的predictor的残差(residual error).
Stacking (stacked generalisation)
多层训练模型的雏形。
集成算法(chapter 7 - Hands on machine learning with scikit learn and tensorflow)的更多相关文章
- How do I learn machine learning?
https://www.quora.com/How-do-I-learn-machine-learning-1?redirected_qid=6578644 How Can I Learn X? ...
- [GPU] Machine Learning on C++
一.MPI为何物? 初步了解:MPI集群环境搭建 二.重新认识Spark 链接:https://www.zhihu.com/question/48743915/answer/115738668 马铁大 ...
- [翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems"
[翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed ...
- Machine Learning for Developers
Machine Learning for Developers Most developers these days have heard of machine learning, but when ...
- Azure Machine Learning
About me In my spare time, I love learning new technologies and going to hackathons. Our hackathon p ...
- 壁虎书2 End-to-End Machine Learning Project
the main steps: 1. look at the big picture 2. get the data 3. discover and visualize the data to gai ...
- A Gentle Guide to Machine Learning
A Gentle Guide to Machine Learning Machine Learning is a subfield within Artificial Intelligence tha ...
- Bayesian machine learning
from: http://www.metacademy.org/roadmaps/rgrosse/bayesian_machine_learning Created by: Roger Grosse( ...
- [Machine Learning] 机器学习常见算法分类汇总
声明:本篇博文根据http://www.ctocio.com/hotnews/15919.html整理,原作者张萌,尊重原创. 机器学习无疑是当前数据分析领域的一个热点内容.很多人在平时的工作中都或多 ...
随机推荐
- [SoapUI] 在SoapUI中通过Groovy脚本执行window命令杀掉进程
//杀Excel进程 String line def p = "taskkill /F /IM EXCEL.exe".execute() def bri = new Buffere ...
- Python编程笔记(第三篇)【补充】三元运算、文件处理、检测文件编码、递归、斐波那契数列、名称空间、作用域、生成器
一.三元运算 三元运算又称三目运算,是对简单的条件语句的简写,如: 简单条件处理: if 条件成立: val = 1 else: val = 2 改成三元运算 val = 1 if 条件成立 else ...
- [AI]神经网络章1 神经网络基本工作原理
神经元细胞的数学计算模型 神经网络由基本的神经元组成,下图就是一个神经元的数学/计算模型,便于我们用程序来实现. 输入 (x1,x2,x3) 是外界输入信号,一般是一个训练数据样本的多个属性,比如,我 ...
- Imageview 按比例适应屏幕大小
DisplayMetrics dm = new DisplayMetrics();//取得窗口属性getWindowManager().getDefaultDisplay().getMetrics(d ...
- centos nfs配置备忘
[需求]web应用需要部署在两台机器,图片目录共用,MySQL共用. [环境]Server: 192.168.168.10Client: 192.168.168.20 [配置步骤]1.在两台机器上安装 ...
- 浅谈Spring中的Quartz配置
浅谈Spring中的Quartz配置 2009-06-26 14:04 樊凯 博客园 字号:T | T Quartz是一个强大的企业级任务调度框架,Spring中继承并简化了Quartz,下面就看看在 ...
- Windows-universal-samples学习笔记系列四:Data
Data Blobs Compression Content indexer Form validation (HTML) IndexedDB Logging Serializing and dese ...
- Windows 平台 (UWP)应用设计
Make Your Apps Cooperate with Cross-App Communication : https://rewards.msdn.microsoft.com/Challeng ...
- 求先序排列(NOIP2001&NOIP水题测试(2017082301))
题目链接:求先序排列 这道题讲白了,就是数的构造,然后遍历. 思路大致是这样: 我们先通过后序遍历,找到当前区间的根,然后在中序遍历中找到根对应的下标,然后就可以分出左右子树,建立当前根与左右子树根的 ...
- MySQL中使用SHOW PROFILE命令分析性能的用法整理
show profile是由Jeremy Cole捐献给MySQL社区版本的.默认的是关闭的,但是会话级别可以开启这个功能.开启它可以让MySQL收集在执行语句的时候所使用的资源.为了统计报表,把pr ...